Algo
[TOC]
待填坑:
数学:莫比乌斯反演、多项式与生成函数、快速傅里叶变换、快速数论变换、计算几何、原根、Pick定理、线性基、母函数、
基础算法:莫队、倍增、
字符串:exKMP、AC自动机、后缀自动机、可持久化Trie、回文树、
图论:树链剖分、基环树、树分治、圆方树、
数据结构:主席树、平衡树、笛卡尔树、动态树、可持久化数据结构、
动态规划:计数DP、插头DP、期望/概率DP、
数学
基础运算
快速冥/乘
//求a^b对p取模的值
long long qmi(long long a, long long b,long long p) {
long long ans = 1;
while (b) {
if (b&1) {//如果指数为奇数
ans = ans*a%p;//收集好指数为奇数时分离出来的一次方,(不可写为ans*=a%p)
}
b >>= 1; //指数折半
a = a*a%p; //底数变平分
}
return ans%p;
}
//龟速乘
//求a*b对p取模的值
long long qmx(long long a, long long b, long long p) {
long long ans = 0;
while (b) {
if (b & 1) ans = (ans + a) % p;
b >>= 1;
a = (a + a) % p;
}
return ans;
}
//__int128
long long qmx(long long a, long long b, long long p) {
return __int128(a) * b % p;
}
//转为浮点运算(模数p不超过int)
long long qmx(long long a, long long b, long long p) {
a %= p; b %= p;
long long r = a * b - p*(long long)(1.0L / p * a * b);
return r - p * (r >= p) + p * (r < 0);
}
求$n^k$的前三位数
$n^k = 10^{k\lg n} = 10^{\lfloor k\lg n\rfloor} \times 10^{k\lg n - \lfloor k\lg n\rfloor}$ 前半部分为整数次幂,后半部分为小数次幂。$n^k = 小数次幂 \times 10^{整数次幂}$ ,例如$2^{20} = 1.048576\times 10^6$ 我们只需要取小数次幂的三位(乘100再取整即可)
//https://vjudge.net/problem/LightOJ-1282
int p = pow(10,k*log10(n) - floor(k*log10(n))) * 100;
高精度
加 减 乘 除 模 幂
//按住ctrl点击跳转
加
// A+B
#include<iostream>
#include<vector>
using namespace std;
string a, b;
vector<int> A, B;
vector<int> add(vector<int>&A, vector<int>&B) {
vector<int>C;
int t = 0;
for (int i = 0; i < A.size() || i < B.size(); i++){
if (i < A.size()) t += A[i];
if (i < B.size()) t += B[i];
C.push_back(t % 10); //无论是否有进位,都取 %10的余数
t /= 10; //判断是否有进位
}
if (t) C.push_back(1); //如果有最高位还有进位则在C数组最后加元素1
return C;
}
int main() {
cin >> a >> b; //a = 123456
for (int i = a.size() - 1; i >= 0; i--) {
A.push_back(a[i] - '0'); //A = {6,5,4,3,2,1}
}
for (int i = b.size() - 1; i >= 0; i--) {
B.push_back(b[i] - '0');
}
A = add(A, B); //auto 进行类型自动转换 在此相当于vector<int>;
for (int i = A.size() - 1; i >= 0; i--) {
printf("%d", A[i]);
}
}
减
// A-B
#include <iostream>
#include <vector>
using namespace std;
string a, b;
vector<int>A, B, C; //判断a与b的大小
bool cmp(vector<int>& A, vector<int>& B) {
if (A.size() != B.size()) return A.size() > B.size();//先比较位数
for (int i = A.size() - 1; i >= 0; i--) { //位数相同则从高位依次比下来
if (A[i] != B[i]) return A[i] > B[i];
}
return 1;
}
vector<int>sub(vector<int>& A, vector<int>& B) {//A >= B
vector<int>C;
int t = 0;
for (int i = 0;i < A.size();i++){
t+=A[i];
if (i < B.size()) t -= B[i];
C.push_back((t + 10) % 10); //保证相减后取正数
if (t < 0) t = -1; //判断是否要借位
else t = 0;
}
while (C.size() > 1 && C.back() == 0) C.pop_back();//去除前导0,pop_back删除容器中最后一个元素
return C;
}
int main() {
cin >> a >> b;
for (int i = a.size() - 1; i >= 0; i--) {
A.push_back(a[i] - '0');
}
for (int i = b.size() - 1;i >= 0;i--){
B.push_back(b[i] - '0');
}
if (cmp(A, B)) A = sub(A, B);
else A = sub(B, A);
for (int i = A.size() - 1; i >= 0; i--) printf("%d", A[i]);
}
乘

//A*b O(N)
vector<int>mul(vector<int>& A, int b) {
int t = 0;
vector<int>C;
for (int i = 0; i < A.size() || t; i++) { //注意加上||t;
if (i < A.size()) t += A[i] * b; //将b当做一个整体分别与a的每一位相乘,再加上进位
C.push_back(t % 10); //C的每一位取其%10
t /= 10; //计算进位
}
return C;
}
//A*B O(N*M)
vector<int> mul(vector<int> &A,vector<int> &B)
vector<int> C(A.size()+B.size());
for(int i=0;i<A.size();i++)
for(int j=0;j<B.size();j++)
C[i+j]+=A[i]*B[j];
for(int i=0,t=0;i<res.size();i++){
t+=C[i];
C[i]=t%10;
t/=10;
}
while(C.size() >= 2 && C.back()==0) C.pop_back();
return C;
}
//A*B FFT实现 O((N+M)log(N+M))
//https://www.luogu.com.cn/problem/P1919
const long double PI = acosl(-1.0);
void FFT(std::vector<std::complex<long double>>& a, bool invert) {
int n = a.size();
if(n == 0) return;
for(int i = 1, j = 0; i < n; i++) {
int bit = n >> 1;
for (; j & bit; bit >>= 1) j ^= bit;
j ^= bit;
if (i < j) std::swap(a[i], a[j]);
}
for(int len = 2; len <= n; len <<= 1) {
long double ang = 2 * PI / len * (invert ? -1 : 1);
std::complex<long double> wlen(cosl(ang), sinl(ang));
for (int i = 0; i < n; i += len) {
std::complex<long double> w(1.0);
for (int j = 0; j < len / 2; j++) {
std::complex<long double> u = a[i + j];
std::complex<long double> v = a[i + j + len / 2] * w;
a[i + j] = u + v;
a[i + j + len / 2] = u - v;
w *= wlen;
}
}
}
if(invert) {
for (std::complex<long double>& x : a) x /= n;
}
}
std::vector<long long> operator * (const std::vector<long long>&A,const std::vector<long long>&B){
std::vector<long long>C;
int n = A.size(), m = B.size();
if((n == 1 && A[0] == 0) || (m == 1 && B[0] == 0)) return {0};
int MAX_N = 1;
while (MAX_N < n + m) MAX_N <<= 1;
std::vector<std::complex<long double>> a(MAX_N, 0.0), b(MAX_N, 0.0);
for(int i = 0; i < n; i++) a[i] = std::complex<long double>(A[i], 0);
for(int i = 0; i < m; i++) b[i] = std::complex<long double>(B[i], 0);
FFT(a, false);
FFT(b, false);
for(int i = 0; i < MAX_N; i++) a[i] *= b[i];
FFT(a, true);
std::vector<long long> temp(n + m, 0);
for(int i = 0; i < n + m; i++) {
long long val = (long long)(a[i].real() + 0.5);
temp[i] = val;
}
long long carry = 0;
for(int i = 0; i < n + m; i++) {
long long total = temp[i] + carry;
C.push_back(total % 10);
carry = total / 10;
}
if(carry) C.push_back(carry);
while(C.size() >= 2 && C.back() == 0) C.pop_back();
return C;
}
除

//A/b及其余数
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
vector<int>A;//C为商
vector<int>div(vector<int>&A,int b,int&r){ //r是引用
vector<int>C;
for (int i = A.size() - 1;i >= 0;i--){ //除法此处倒序,然后再翻转
r = r * 10 + A[i]; //上一位的余数*10再加上本位
C.push_back(r / b); //将其对b的商记录进C数组
r %= b; //然后变为其对b的余数供下一位使用
}
reverse(C.begin(), C.end());
while (C.size() > 1 && C.back() == 0) C.pop_back();
return C;
}
int main() {
string a; int b, r = 0; //r为余数
cin >> a >> b;
for (int i = a.size() - 1; i >= 0; i--) {
A.push_back(a[i] - '0');
}
A = div(A, b, r);
for (int i = A.size() - 1;i >= 0;i--){
printf("%d", A[i]);
}
cout << endl << r << endl;
return 0;
}
//a/b 保留k位小数
long long a,b,k;cin >> a >> b >> k;
cout << a/b << '.';
a = a%b*10;
while(k--){
cout << a/b;
a = a%b*10;
}
//求a/b的第k位小数 相当于a*10^k/b%10
long long a,b,k;cin >> a >> b >> k;
cout << a*qmi(10,k-1,b)*10/b%10;
模
给两个正整数a,b,输出他们的最大公约数 a<=1e10^6,b <= 1e9
首先有以下性质 1.(a+b)%mod等价于a%mod+b%mod 2.a * b%mod 等价于 a%modb%mod(仅当a * b没有溢出时) 该题求解gcd(a,b)a是大数 根据辗转相除法 gcd(a,b)=gcd(b,a%b) 因此我们可以先求a%b把a限制在1e9的范围内,然后做gcd 因为a很大,又可以表示为$\sum_{i=1}^n{a_i10^{n-i}}$(其中n为字符串的长度,ai为第i个字符) 又由性质1和2,我们就可以对每个ai求mod,同时通过乘和累加求出
//A%b
//https://ac.nowcoder.com/acm/contest/86034/D
#include <iostream>
using namespace std;
using ll = long long;
ll gcd(ll a,ll b){return b?gcd(b,a%b):a;}
ll qmod(string& a,ll b){//高精度A % 低精度b
ll t = 0;
for(int i = 0;i < a.size();i++) {
t=(t*10+a[i]-'0')%b;
}
return t;
}
int main(){
string a;cin >> a;
ll b;cin >> b;
cout << gcd(b,qmod(a,b));
}
幂
//中精度 2^n 2*n <= 30000 //n可以为负数
//仅适用于计算2^n的精确值
#include <iostream>
#include <sstream>
#include <iomanip>
#include <cmath>
using namespace std;
int main(){
int n; cin>>n;
stringstream ss;
ss << fixed << setprecision(n>0?0:-n) << pow(2.0L,n);
//string s = ss.str(); //字符串流,也可以用sprintf
string s; ss >> s;
cout << s;
}
//高精度快速幂 A^b 一般b取不了太大
Bigint qmi(Bigint &a,int b){
Bigint ans = 1;
while(b){
if(b&1) ans = ans*a;
b >>= 1;
a = a*a;
}
return ans;
}
python高精
import sys
sys.set_int_max_str_digits(100005) #修改最大位数
a = int(input())
b = int(input())
print(a+b) #加
print(a-b) #减
print(a*b) #乘
print(a//b) #除
print(a%b) #模
print(a**b) #幂
数学运算
sqrt
//向下取整
long long qsqrt(long long n) {
long long s = std::sqrt(n);
while (s*s > n) { s--; }
while ((s+1)*(s+1) <= n) { s++; }
return s;
}
log
//向上取整
long long logi(long long a, long long b) {//log(a,b) a^t ≥ b
long long t = 0;
long long v = 1;
while (v < b) {
v *= a;
t++;
}
return t;
}
long long llog(long long a, long long b) {//loglog(a,b) a^(a^t) ≥ b
if (a <= b) {
int l = logi(a, b);
return (l == 0 ? 0 : std::__lg(2 * l - 1));
}
assert(b != 1);
long long l = logi(b, a + 1) - 1;
assert(l > 0);
return -std::__lg(l);
}
//预处理log2, (向下取整)
lg2[0] = -1;
for(int i = 1;i < N;i++){
lg2[i] = lg2[i>>1]+1;
}
除法取整
long long ceilDiv(long long n, long long m) {//上取整
if (n >= 0) return (n + m - 1) / m;
else return n / m;
}
long long floorDiv(long long n, long long m) {//向下取整
if (n >= 0) return n / m;
else return (n - m + 1) / m;
}
分式运算
源自jiangly分数四则运算 博客园 (cnblogs.com)
Frac a(1,3); 表示$\frac{1}{3}$ ,支持分式之间 + - * / 和比较大小
template<class T>
struct Frac {// num/den
T num;
T den;
Frac(T num_, T den_) : num(num_), den(den_) {
if (den < 0) {
den = -den;
num = -num;
}
}
Frac() : Frac(0, 1) {}
Frac(T num_) : Frac(num_, 1) {}
explicit operator double() const {
return 1. * num / den;
}
explicit operator long long() const{
return num / den;
}
friend long long floor(const Frac &x){
if(x.num >= 0) return x.num / x.den;
else return (x.num - x.den + 1) / x.den;
}
friend long long ceil(const Frac &x){
if(x.num >= 0) return (x.num + x.den - 1) / x.den;
else return x.num / x.den;
}
Frac &operator+=(const Frac &rhs) {
num = num * rhs.den + rhs.num * den;
den *= rhs.den;
return *this;
}
Frac &operator-=(const Frac &rhs) {
num = num * rhs.den - rhs.num * den;
den *= rhs.den;
return *this;
}
Frac &operator*=(const Frac &rhs) {
num *= rhs.num;
den *= rhs.den;
return *this;
}
Frac &operator/=(const Frac &rhs) {
num *= rhs.den;
den *= rhs.num;
if (den < 0) {
num = -num;
den = -den;
}
return *this;
}
friend Frac operator+(Frac lhs, const Frac &rhs) {
return lhs += rhs;
}
friend Frac operator-(Frac lhs, const Frac &rhs) {
return lhs -= rhs;
}
friend Frac operator*(Frac lhs, const Frac &rhs) {
return lhs *= rhs;
}
friend Frac operator/(Frac lhs, const Frac &rhs) {
return lhs /= rhs;
}
friend Frac operator-(const Frac &a) {
return Frac(-a.num, a.den);
}
friend bool operator==(const Frac &lhs, const Frac &rhs) {
return lhs.num * rhs.den == rhs.num * lhs.den;
}
friend bool operator!=(const Frac &lhs, const Frac &rhs) {
return lhs.num * rhs.den != rhs.num * lhs.den;
}
friend bool operator<(const Frac &lhs, const Frac &rhs) {
return lhs.num * rhs.den < rhs.num * lhs.den;
}
friend bool operator>(const Frac &lhs, const Frac &rhs) {
return lhs.num * rhs.den > rhs.num * lhs.den;
}
friend bool operator<=(const Frac &lhs, const Frac &rhs) {
return lhs.num * rhs.den <= rhs.num * lhs.den;
}
friend bool operator>=(const Frac &lhs, const Frac &rhs) {
return lhs.num * rhs.den >= rhs.num * lhs.den;
}
friend std::ostream &operator << (std::ostream &os, Frac x) {
T g = std::gcd(x.num, x.den);
if (x.den == g) { return os << x.num / g; } //
else { return os << x.num / g << "/" << x.den / g; }
}
};
BigInt
高精度整数运算,不支持负数运算(待完善),写得一坨,勉强能用只能说是==
| 操作 | A op b (高精度op低精度) | A op B (高精度op高精度) |
|---|---|---|
| 加法 | + 、+= |
+ 、+= |
| 减法(仅限大op小) | -、 -= |
-、 -= |
| 乘法 | *、 *= |
*、 *= (O(N*M)模拟),不推荐,建议换FFT) |
| 除法(下取整) | /、 /= |
|
| 取模 | % 、%= |
|
| 比较大小 | > < == != >= <= |
> < == != >= <= |
允许直接A/B、A%B 但需要保证B在整型范围内(B <= 9.2e17)
初始化
Bigint A(123);Bigint A("123");int n = 123; Bigint A = n;string s = 123; Bigint A = s;cin >> A;
struct Bigint{
std::vector<long long> a;
Bigint (){ }
Bigint(const std::string &s){
for(int i = s.size()-1;i >= 0;i--){
if(s[i] >= '0' && s[i] <= '9') a.emplace_back(s[i] - '0');
}
while(a.size() >= 2 && a.back() == 0) a.pop_back();
}
Bigint(long long x){
if(x == 0) {a.emplace_back(0); return;}
if(x < 0) x = ~x + 1;
while(x) a.emplace_back(x%10),x/=10;
}
friend long long Bigint_to_int(const Bigint &B){
long long b = 0;
for(int i = B.a.size()-1;i >= 0;i--){
b = b*10 + B.a[i];
}
return b;
}
Bigint operator + (const Bigint &B){
Bigint C;
std::vector<long long>&c = C.a;
const std::vector<long long>&b = B.a;
long long t = 0;
for(int i = 0;i < a.size() || i < b.size() || t;i++){
if(i < a.size()) t += a[i];
if(i < b.size()) t += b[i];
c.emplace_back(t%10);
t/=10;
}
return C;
}
Bigint operator + (long long b){
return *this + Bigint(b);
}
Bigint operator * (long long b){
long long t = 0;
Bigint C;
std::vector<long long>&c = C.a;
for(int i = 0;i < a.size() || t;i++){
if(i < a.size()) t += a[i]*b;
c.emplace_back(t%10);
t/=10;
}
while(c.size() >= 2 && c.back() == 0) c.pop_back();
return C;
}
Bigint operator * (const Bigint &B){
const auto &A = this->a;
Bigint C;
C.a = std::vector<long long>(A.size()+B.a.size());
for(int i = 0;i < A.size();i++){
for(int j = 0;j < B.a.size();j++){
C.a[i+j] += A[i]*B.a[j];
}
}
long long t = 0;
for(int i = 0;i < C.a.size();i++){
t += C.a[i];
C.a[i] = t%10;
t /= 10;
}
while(C.a.size() >= 2 && C.a.back() == 0) C.a.pop_back();
return C;
}
Bigint operator - (const Bigint &B){
Bigint C;
std::vector<long long>&c = C.a;
const std::vector<long long>&b = B.a;
long long t = 0;
for(int i = 0;i < a.size();i++){
t += a[i];
if(i < b.size()) t -= b[i];
c.emplace_back((t+10)%10);
if(t < 0) t = -1;
else t = 0;
}
while(c.size() >= 2 && c.back() == 0) c.pop_back();
return C;
}
Bigint operator - (long long b){
return *this - Bigint(b);
}
Bigint operator / (long long b){
Bigint C;
std::vector<long long>&c = C.a;
long long t = 0;
for(int i = a.size()-1;i >= 0;i--){
t = t*10 + a[i];
c.emplace_back(t/b);
t %= b;
}//t as the remainder == A%b
reverse(c.begin(),c.end());
while(c.size() >= 2 && c.back() == 0) c.pop_back();
return C;
}
Bigint operator / (const Bigint &B){
return (*this)/Bigint_to_int(B);
}
Bigint operator % (long long b){
long long t = 0;
for(int i = a.size()-1;i >= 0;i--){
t = (t*10 + a[i]) %b;
}
return Bigint(t);
}
Bigint operator % (const Bigint &B){
return (*this)%Bigint_to_int(B);
}
int cmp (const Bigint &B){
const std::vector<long long>&b = B.a;
if(a.size() != b.size()) {
return a.size() > b.size() ? 1 : -1;
}
for(int i = a.size()-1;i >= 0;i--){
if(a[i] != b[i]){
return a[i] > b[i] ? 1 : -1;
}
}
return 0;
};
void operator += (const auto &b){*this = *this + b;}
void operator -= (const auto &b){*this = *this - b;}
void operator *= (const auto &b){*this = *this * b;}
void operator /= (const auto &b){*this = *this / b;}
void operator %= (const auto &b){*this = *this % b;}
bool operator > (const auto &b){return cmp(b) == 1;}
bool operator < (const auto &b){return cmp(b) == -1;}
bool operator == (const auto &b){return cmp(b) == 0;}
bool operator != (const auto &b){return cmp(b) != 0;}
bool operator >= (const auto &b){return cmp(b) != -1;}
bool operator <= (const auto &b){return cmp(b) != 1;}
friend std::ostream &operator << (std::ostream &o,const Bigint &t){
for(int i = t.a.size()-1;i >= 0;i--){
o << t.a[i];
}
return o;
}
friend std::istream &operator >> (std::istream &o,Bigint &t){
std::string s;o >> s;
t = s;
return o;
}
};
初等数论
常见符号
- 整除符号:$x\mid y$,表示 $x$ 整除 $y$,即 $x$ 是 $y$ 的因数。
- 取模符号:$x\bmod y$,表示 $x$ 除以 $y$ 得到的余数。
- 互质符号:$x\perp y$,表示 $x$,$y$ 互质。
- 最大公约数:$\gcd(x,y)$,在无混淆意义的时侯可以写作 $(x,y)$。
- 最小公倍数:$\operatorname{lcm}(x,y)$,在无混淆意义的时侯可以写作 $[x,y]$。
约数
平凡约数(平凡因数):对于整数 $b\ne0$,$\pm1$、$\pm b$ 是 $b$ 的平凡约数。当 $b=\pm1$ 时,$b$ 只有两个平凡约数。
对于整数 $b\ne 0$,$b$ 的其他约数称为真约数(真因数、非平凡约数、非平凡因数)。
公约数
求一个数g的所有约数,或两个数x,y的所有公约数 f(30) = {1 2 3 5 6 10 15 30} f(30,5) = {1,5}
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int gcd(int a,int b){return b?gcd(b,a%b):a;}
vector<int>v;
int main(){
int x,y;cin >> x >> y;
int g = gcd(x,y);
//预处理所有公约数,这些公约数一定是最大公约数的约数
for (int i = 1; i <= g/i; ++i) {
if(g%i == 0) {
v.push_back(i);
if(i!=g/i) v.push_back(g/i);
}
}
sort(v.begin(),v.end());//排序
for (int i = 0; i < v.size(); ++i) {
cout << v[i] << ' ';
}
return 0;
}
最大公约数
AcWing 872. 六种方法求最大公约数及其时间复杂度分析 - AcWing
//GNU编译器
__gcd(a,b); //#include <algorithm> 返回a,b的最大公约数
//二进制优化,快个两三倍
int gcd(int a,int b){
int az = __builtin_ctz(a),bz = __builtin_ctz(b);//末尾元素0的个数,对于LL类型,需要使用__builtin_ctzll
int z = std::min(az,bz);
b >>= bz;
while(a) {
a >>= az;
int dif = b-a;
az = __builtin_ctz(dif);
if(a < b) b = a;
if(dif < 0) a = -dif;
else a = dif;
}
return b << z;
}
[欧几里得算法][辗转相除法]求最大公约数:
//a和b的最大公约数是a%b和b的最大公约数
int gcd(int a, int b) {return b ? gcd(b,a%b) : a;}
相邻的两个数gcd(n,n-1) = 1
$GCD(a_1,a_2,a_3,\ldots,a_n) = GCD(s_1,s_2,s_3,\ldots,s_n)$ 其中s[ ]为a[ ]的前缀和数组(或者差分数组)
扩展欧几里得
求解形如 $ax +by = c$ 的通解(有解的充要条件: c % gcd(a , b) == 0)
裴蜀定理:对于任意整数a,b,一定存在一对整数x,y,满足:ax + by = gcd(a,b)
设d = gcd(a,b)
设x,y为当前层的一组解 ,x1,y1为下一层的一组解
当前层方程为 $ax+by = d$
下一层方程为 $bx_1+(a\%b)y_1 = d$ $\Longrightarrow bx_1 + (a-(a/b)b)y_1 = d$ $\Longrightarrow ay_1 + b(x_1 - a/by_1) = d$
联立当前层与下一层,则可得到当前层的解x,y,与下一层方程解x1,y1的关系 $ax+by = ay_1 + b(x_1 - a/b*y_1)$
下层往上回溯时用下一层的解x1,y1更新当前层的解x,y $x = y_1$ ,$y = x_1-a/b*y_1$
$ax+by = gcd(a,b)$的特解、通解、最小正整数解,$x_0,y_0$ 为 $d = exgcd(a,b,x,y)$的一组解 特解:$x = x_0,y = y_0$ ,诺$b \ne 0$,那么必有$|x_0| \le b,|y_0| \le a$ 通解:$x = x_0 + \frac{b}{d} * k$,$y = y_0 - \frac{a}{d}*k ,其中k\in Z$,由此可知$x,y$的增减性相反 x的最小非负整数解:$x=(x_0 \% |\frac{b}{d}|+|\frac{b}{d}|)\%|\frac{b}{d}|$
$ax+by = c$的特解、通解、最小正整数解(诺c%gcd(a,b) != 0 则无解)令 $x_0,y_0$ 为 $d = exgcd(a,b,x,y)$的一组解
特解:$x = x_0 * \frac{c}{d},y = y_0 * \frac{c}{d}$
通解:$x = x_0\frac{c}{d} + \frac{b}{d}k,y = y_0 * \frac{c}{d} - \frac{a}{d}*k,其中k\in Z$
x的最小非负整数解:$x = x_0 * \frac{c}{d} \% |\frac{b}{d}| + |\frac{b}{d}|) \% |\frac{b}{d}|$
int exgcd(int a,int b,int& x,int& y){//x,y引用传递
if(!b){
x = 1,y = 0;//当最终b = 0时,x = 1,y = 0 显然是方程的解a*1+0*0 = a
return a;
}
int d = exgcd(b,a%b,x,y);
int x1 = x,y1 = y;
x = y1;
y = x1 - a/b*y1;
return d;
}
类似的,多元线性丢番图$a_1x_1+a_2x_2+\dots +a_nx_n = c$有整数解,当且仅当$d = gcd(a_1,a_2\dots a_n)$整除c。
最小公倍数
重要推论:gcd(a,b) * lcm(a,b) = a*b
long long gcd(long long a, long long b) { return b ? gcd(b, a % b) : a; }
long long lcm(long long a, long long b) { return a / gcd(a, b) * b; }
//先算除法避免数据越界
#define lcm(a, b) a / gcd(a, b) * b
//计算最小公倍数时,可以使用带参数的宏定义,比使用函数略微快一些(省去了函数的调用、返回和传参)
分解只因数
每个合数都可以写成几个质数相乘的形式,其中每个质数都是这个合数的因数
如:$12 = 2^2 * 3^1$
试除法
时间复杂度 $O(\sqrt N)$
fac(12) = {(2,2),(3,1)}
//https://www.acwing.com/problem/content/description/869/
#include <iostream>
using namespace std;
int main() {
int t; cin >> t;
while (t--){
int n; cin >> n;
for (int i = 2; i <= n / i; i++) {
if (n % i == 0) {//循环里的i一定是n的素因子
int s = 0;
while (n%i == 0){
n /= i;
s++;
}
cout << i << ' ' << s << endl;
}
}
if (n > 1) cout << n << ' ' << 1 << endl;
cout << endl;
}
}
约数分解
fac(12) = {1,2,3,4,6,12}
//试除法求约数 https://www.acwing.com/problem/content/871/
vector<int>fac;
void dfs(vector<pair<int,int>>&v,int u,int now){
if(u >= v.size()) return;
for(int i = u;i < v.size();i++){
int w = 1;
for(int j = 0;j < v[i].second;j++){
w *= v[i].first;
fac.emplace_back(now*w);
dfs(v,i+1,now*w);
}
}
}
void soviet(){
int x; cin >> x;
auto v = factorize(x);
fac = {1};
dfs(v,0,1);
sort(fac.begin(),fac.end());
cout << fac.size() << '\n';
for(auto x:fac){
cout << x << ' ';
}
cout << '\n';
}
筛法求质因数
$O(N)$ 预处理,$O(p(x))$ 查询,$p(x)$为$x$的因数个数
primes[]存1~N的所有素数,0_idx
minp[x]为x的最小质因子
maxp[x]为x的最大质因子,诺 maxp[x] == x则x为质数
std::vector<int> primes, minp, maxp;
void sieve(int n = 1e6) {
minp.resize(n + 1);
maxp.resize(n + 1);
for (int i = 2; i <= n; i++) {
if (!minp[i]) {
minp[i] = maxp[i] = i;
primes.emplace_back(i);
}
for (auto &j : primes) {
if (j > minp[i] || j > n / i) break;
minp[i * j] = j;
maxp[i * j] = maxp[i];
}
}
}
std::vector<std::pair<int,int>> factorize(int n) {//pair{质因数,次方}
std::vector<std::pair<int,int>>ans;
while (n > 1) {
long long now = get_maxprime(x);
ans.push_back({now,1});
x /= now;
while(x % now == 0) {
ans.back().second++;
x /= now;
}
}
return ans;
}
int main(){
sieve(1000000);
int x; std::cin >> x;
for(auto [p,k]:factorize(x)){
std::cout << p << '^' << k << '\n';
}
}
Pollard_Rho
泼辣的肉,期望时间复杂度为 $O(\sqrt{p}) = O(N^{\frac{1}{4}})$
namespace Pollard_Rho{
long long qmi(long long a,long long b,long long p){
long long ans = 1;
while(b){
if(b&1) ans = __int128(ans) * a % p;
b>>=1;
a = __int128(a) * a % p;
}
return ans;
}
bool isprime(long long x) {//Miller-Rabin素数判断,时间复杂log~log^2
if (x < 2 || x % 6 % 4 != 1) return (x|1) == 3;
long long s = __builtin_ctzll(x-1), d = x >> s;
for (long long a : {2, 325, 9375, 28178, 450775, 9780504, 1795265022}) {
long long p = qmi(a % x, d, x), i = s;
while (p != 1 && p != x - 1 && a % x && i--) {
p = __int128(p) * p % x;
}
if (p != x - 1 && i != s) return 0;
}
return 1;
}
long long gcd(long long a,long long b) {return b ? gcd(b,a%b) : a;}
long long max_factor;
long long Pollard_Rho(long long x) {
long long s = 0, t = 0;
long long c = (long long)rand() % (x - 1) + 1;
long long val = 1;
for (int goal = 1;; goal <<= 1, s = t, val = 1) {//倍增优化
for (int step = 1; step <= goal; ++step) {
t = ((__int128)t*t%x + c) % x;
val = (__int128)val*std::abs(t-s)%x;
if ((step % 127) == 0) {
long long d = gcd(val, x);
if (d > 1) return d;
}
}
long long d = gcd(val, x);
if (d > 1) return d;
}
}
void fac(long long x) {
if (x <= max_factor || x < 2) return;
if (isprime(x)) {
max_factor = std::max(max_factor, x);
return;
}
long long p = x;
while (p >= x) p = Pollard_Rho(x);
while ((x % p) == 0) x /= p;
fac(x), fac(p);
}
long long get_maxprime(long long x){//返回x的最大质因子
max_factor = 0;
fac(x);
return max_factor;
}
std::vector<std::pair<long long,int>> factorize(long long x){//返回x的质因子vec{prime,k次方}
std::vector<std::pair<long long,int>> ans;
while(x > 1) {
long long now = get_maxprime(x);
if(ans.empty() || now != ans.back().first) ans.push_back({now,1});
else ans.back().second++;
x /= now;
}
std::reverse(ans.begin(),ans.end());
return ans;
}
};
using Pollard_Rho::isprime,Pollard_Rho::get_maxprime,Pollard_Rho::factorize;
int main(){//使用方法示例
long long x; std::cin >> x;
std::cout << isprime(x) << '\n';//素数判断
std::cout << get_maxprime(x) << '\n';//最大质因子
for(auto &[p,k]:factorize(x)){//分解质因数(从小到大排序)
std::cout << p << '^' << k << '\n';
}
}
约数个数
如果N = $p_1^{c_1}p_2^{c_2}…*p_k^{c_k}$
约数个数 = $(c_1+1)(c_2+1)…(c_k+1) = \prod_{i=1}^{k}(c_i+1)$ 约数之和 = $(p_1^0+p_1^1+…p_1^{c_1})…*(p_k^0+p_k^1+…p_k^{c_k})=\prod_{i=1}^k(\sum_{j=0}^{c_i}p_i^j)$
//https://www.acwing.com/problem/content/872/
//给定 n 个正整数 a[],请你输出这些数的乘积的约数个数,答案对 1e9+7 取模。
#include <iostream>
#include <unordered_map>
using namespace std;
const int mod = 1e9 + 7;
unordered_map<int, int>primes;
int main() {
int t; cin >> t;
while (t--){
int n; cin >> n;
for (int i = 2; i <= n / i;i++) {
while (n % i == 0) {
n /= i;
primes[i]++;
}
}
if (n > 1) primes[n]++;
}
long long ans = 1;
for (auto& i : primes) {
int a = i.second;
ans = ans * (a + 1) % mod;
}
cout << ans << endl;
}
约数之和
如果N = $p_1^{c_1}p_2^{c_2}…*p_k^{c_k}$
约数个数 = $(c_1+1)(c_2+1)…(c_k+1) = \prod_{i=1}^{k}(c_i+1)$ 约数之和 = $(p_1^0+p_1^1+…p_1^{c_1})…*(p_k^0+p_k^1+…p_k^{c_k})=\prod_{i=1}^k(\sum_{j=0}^{c_i}p_i^j)$
求a^b约数之和%mod,0 <= a,b <= 5e7
实现一个sum函数,sum(p, k)表示$p^0+p^1+…+p^{k−1}$
方法一O(k):递推求p^0 + p^1 + … + p^k
ll sum0(ll p,ll k){ ll res = 1; for(int i = 1;i <= k;i++){ res = (res*p+1)%mod; } return res; }
方法二O(logK):递归求 k为偶数时sum(p,k) => $p^0+p^1+…+p^{\frac{k}{2}-1}+p^{\frac{k}{2}}+p^{\frac{k}{2}+1}+…+p^{k-1}$ =>$p^0+p^1+…+p^{\frac{k}{2}-1}+p^{\frac{k}{2}}(p^0+p^1+…+p^{\frac{k}{2}-1})$ =>$sum(p,\frac{k}{2}$) + $p^{\frac{k}{2}}sum(p,\frac{k}{2}$) =>$(p^{\frac{k}{2}}+1) * sum(p,\frac{k}{2}$) 当k为奇数时,为了更方便调用我们写的偶数项情况,可以单独拿出最后一项,把剩下的项转化为求偶数项的情况来考虑,再加上最后一项,就是奇数项的情况了,也即$sum(p,k-1) + p^{k-1}$
ll sum1(ll p,ll k){//sum1(p,k+1),调用时k要加1 if(k == 1) return 1;//边界条件 if(!(k&1)) return (qmi(p,k/2)+1)*sum1(p,k/2)%mod;//k为偶数 return (qmi(p,k-1) + sum1(p,k-1))%mod;//k为奇数,k-1为偶数 }
方法三(OlogK):等比求和公式 $sum = p^0+p^1+p^2+…+p^k$ ——① $sum*p = p^1+p^2+p^3…+p^{k+1}$ ——② ②-①化简得sum = $\frac{p^{k+1}-1}{p-1}$ ,利用快速幂求逆元求解
ll sum2(ll p,ll k){ if((p-1)%mod == 0) return k+1; //p-1与mod不互质,逆元不存在 return (qmi(p,k+1)-1)%mod*qmi(p-1,mod-2)%mod; }
//https://www.acwing.com/problem/content/99/
#include <iostream>
#include <map>
using namespace std;
using ll = long long;
const int mod = 9901;
ll qmi(ll a,ll b){
ll ans = 1;
while(b){
if(b&1) ans = ans*a%mod;
b >>= 1;
a = a*a%mod;
}
return ans%mod;
}
ll sum0(ll p,ll k){//递推求p^0 + p^1 + ... + p^k
ll res = 1;
for(int i = 1;i <= k;i++){
res = (res*p+1)%mod;
}
return res;
}
ll sum1(ll p,ll k){//递归求p^0 + p^1 + ... +p^(k-1)
if(k == 1) return 1;//边界条件
if(!(k&1)) return (qmi(p,k/2)+1)*sum1(p,k/2)%mod;//k为偶数
return (qmi(p,k-1) + sum1(p,k-1))%mod;//k为奇数,k-1为偶数
}
ll sum2(ll p,ll k){//等比求和公式[p^(n+1)-a^0]/(p-1)
if((p-1)%mod == 0) return k+1; //p-1与mod不互质,逆元不存在
return (qmi(p,k+1)-1)%mod*qmi(p-1,mod-2)%mod;
}
int main(){
ll a,b;cin >> a >> b;
if(a == 0) return cout << 0,0;
map<ll,ll>mp;
for(int i = 2;i <= a/i;i++){
while(a%i == 0){
mp[i]+=b;
a/=i;
}
}
if(a > 1) mp[a]+=b;
ll ans1 = 1;
for(auto &[p,k]:mp){
ans1 = ans1*sum1(p,k+1)%mod;//ans*=p^(0~k),sum为(0~k-1),所以k要加1
//ans2 = ans2*sum2(p,k)%mod;
}
cout << ans1;
//cout << (ans2%mod+mod)%mod;
}
素数
试除法
时间复杂度$O(\sqrt x)$
bool isPrime(int n){
if (n <= 1 || n == 4) return 0;
if (n == 2 || n == 3) return 1;
if (n % 6 != 1 && n % 6 != 5) return 0;
for (int i = 5; i <= n/i; i += 6) {
if (n % i == 0 || n % (i + 2) == 0) return 0;
}
return 1;
}
Miller-Rabin
快速判断一个数 $x$ 是不是素数,时间复杂度大概为 $log(x)\sim log^2(x)$
long long qmi(long long a,long long b,long long p){
long long ans = 1;
while(b){
if(b&1) ans = __int128(ans) * a % p;
b>>=1;
a = __int128(a) * a % p;
}
return ans;
}
bool isprime(long long x) {
if (x < 2 || x % 6 % 4 != 1) return (x|1) == 3;
long long s = __builtin_ctzll(x-1), d = x >> s;
for (long long a : {2, 325, 9375, 28178, 450775, 9780504, 1795265022}) {
long long p = qmi(a % x, d, x), i = s;
while (p != 1 && p != x - 1 && a % x && i--) {
p = __int128(p) * p % x;
}
if (p != x - 1 && i != s) return 0;
}
return 1;
}
素数筛
$O(N)$ 预处理, $O(1)$ 查询
//线性筛 https://www.luogu.com.cn/problem/P3912
#include <iostream>
using namespace std;
const int N = 1e8 + 5;
bool st[N];//i >= 2且st[i] == 0 则i是素数
int primes[N],cnt;//primes存质数
void initi(int n){
//st[0] = st[1] = 1;
for(int i = 2;i <= n;i++){
if(!st[i]) primes[++cnt] = i;//如果没被筛过,则i是素数
for(int j = 1;primes[j] <= n/i;j++){
st[i*primes[j]] = 1;
if(i%primes[j] == 0) break;
}
}
}
int main() {
int n; cin >> n;
initi(n);
cout << cnt;
}
求[l,r]之间的所有质数 $1\le l \le r < 2^{31} \ \ \ \ \ \ r-l <= 1e6$
//https://vjudge.net/problem/LightOJ-1197
//用数组p存储√r以内的所有质数
//再用p筛选出l~r之间的所有合数,剩下的即为质数
#include <iostream>
const int N = 100005;
bool vis[N];
int primes[N],cnt;
void get_primes(int n){
for(int i = 2;i <= n;i++){
if(!vis[i]) primes[++cnt] = i;
for(int j = 1;i*primes[j] <= n;j++){
vis[i*primes[j]] = 1;
if(i%primes[j] == 0) break;
}
}
}
bool st[N];
void sol(){
long long l,r; std::cin >> l >> r;
for(int i = 0;i < r-l+1;i++) st[i] = 0;
for(int i = 1;(long long)primes[i]*primes[i] <= r;i++){
long long p = primes[i];//p[i]的倍数即为合数
for(long long j = std::max(p+p,p*((l+p-1)/p));j <= r;j += p){
st[j-l] = 1;//j-l为数j相对于l的偏移位置
}
}
int ans = 0;
for(int i = 0;i < r-l+1;i++){
if(!st[i] && l+i > 1) {//特判1
ans++;
}
}
std::cout << ans << '\n';
}
int main(){
get_primes(N-1);
int t; std::cin >> t;
for(int i = 1;i <= t;i++){
printf("Case %d: ",i);
sol();
}
}
威尔逊定理
对于素数p > 1,$(p-1)!\equiv -1\ (mod\ p)$是 p 为素数的充分必要条件。
$(p-1)! \equiv p-1(mod\ p) \equiv -1\ (mod\ p)$
欧拉函数
ϕ(𝑁)表示1~N中与N互质的数的个数
诺将N分解质因数:N = $p_1^{a_1}p_2^{a_2}p_3^{a_3}…p_k^{a_k}$ 则欧拉函数计算公式ϕ(𝑁) = $N·\frac{p_1-1}{p1}·\frac{p_2-1}{p2}·\frac{p_3-1}{p3}…\frac{p_k-1}{pk}$
//求一个数的欧拉函数 √N
//根据计算公式,在分解质因数时顺便求欧拉函数
//https://www.acwing.com/problem/content/875/
#include <iostream>
#include <map>
using namespace std;
int phi(int n){
int ans = n;
for(int i = 2;i <= n/i;i++){
if(n%i == 0){
ans = ans/i*(i-1);
while(n % i == 0){ n /= i; }
}
}
if(n >= 2) ans = ans/n*(n-1);
return ans;
}
int main(){
int tt;cin >> tt;
while(tt--){
int x;cin >> x;
cout << phi(x) <<endl;
}
}
欧拉筛
//筛选法求欧拉函数 O(N)
//在筛质数时顺便求欧拉函数
//https://www.acwing.com/problem/content/876/
#include <iostream>
using namespace std;
const int N = 1000006;
int n;
bool st[N];
int primes[N],cnt;
int phi[N];
void get_phi(int n){
phi[1] = 1;
for(int i = 2;i <= n;i++){
if(!st[i]) {
primes[++cnt] = i;
phi[i] = i-1;//诺i为质数,则phi[i] = i-1
}
for(int j = 1;primes[j] <= n/i;j++){
st[i*primes[j]] = 1;
if(i%primes[j] == 0) {
phi[i*primes[j]] = phi[i]*primes[j];
break;
}
else phi[i*primes[j]] = phi[i]*(primes[j]-1);
}
}
}
int main(){
cin >> n;
get_phi(n);
}
欧拉定理
诺正整数a与n互质,则$a^{\phi(n)} \equiv 1 (mod\ n)$
欧拉定理推论:
诺正整数a与n互质,对于任意正整数b,有$a^b\equiv a^{b\%\phi(n)}(mod\ n)$ 面对乘方算式对质数p取模,可以先把,可以先把底数对p取模、指数对$\phi(p)$取模再计算乘方
诺正整数a与n互质,则满足$a^x\equiv 1(mod\ n)$的最小正整数$x_0$是$phi(n)$的约数。
$\sum_{d n}\phi{(d)} = n$ (n为正整数) for(int i = 1;i <= n;i++){ if(n%i == 0){ ans += phi[i]; } }//ans == n
求$\sum_{i=1}^n\sum_{j=1}^n\gcd(i,j)$
在结论$n=\sum_{d n}\varphi(d)$中代入n=gcd(a,b),则有$\gcd(a,b) = \sum_{d \gcd(a,b)}\varphi(d) = \sum_d [d a][d b]\varphi(d)$ 其中,$[\cdot]$ 称为 Iverson 括号,只有当命题 $P$ 为真时 $[P]$ 取值为 $1$,否则取 $0$。对上式求和,就可以得到 \(\sum_{i=1}^n\gcd(i,n)=\sum_{d}\sum_{i=1}^n[d|i][d|n]\varphi(d)=\sum_d\left\lfloor\frac{n}{d}\right\rfloor[d|n]\varphi(d)=\sum_{d|n}\left\lfloor\frac{n}{d}\right\rfloor\varphi(d).\) 这里关键的观察是 $\sum_{i=1}^n[d|i]=\lfloor\frac{n}{d}\rfloor$,即在 $1$ 和 $n$ 之间能够被 $d$ 整除的 $i$ 的个数是 $\lfloor\frac{n}{d}\rfloor$。
利用这个式子,就可以遍历约数求和了。需要多组查询的时候,可以预处理欧拉函数的前缀和,利用数论分块查询。
仿照上文的推导,可以得出 \(\sum_{i=1}^n\sum_{j=1}^n\gcd(i,j) = \sum_{d=1}^n\left\lfloor\frac{n}{d}\right\rfloor^2\varphi(d).\)
//https://www.luogu.com.cn/problem/P2398
#include <iostream>
using namespace std;
using ll = long long;
const int N = 100005;
int primes[N],cnt;
int phi[N],sum[N];
bool st[N];
void get_phi(int n){
phi[1] = 1;
for(int i = 2;i <= n;i++){
if(!st[i]){
primes[++cnt] = i;
phi[i] = i-1;
}
for(int j = 1;i*primes[j] <= n;j++){
st[i*primes[j]] = 1;
if(i%primes[j] == 0){
phi[primes[j]*i] = phi[i]*primes[j];
break;
}
else phi[primes[j]*i] = phi[i]*(primes[j]-1);
}
}
}
int main(){
int n;cin >> n;
get_phi(n);
ll ans = 0;
for(int i = 1;i <= n;i++){
ans +=(long long)(n/i)*(n/i)*phi[i];
}
/*for(int l = 1,r;l <= n;l = r+1){//这部分计算,可以用整除分块进一步优化为O(sqrt(n))
int t = n/l;
r = n/t;
ans += (long long)t*t * (sum[r] - sum[l-1]);//sum为phi的前缀和数组
}*/
cout << ans;
}
拓展欧拉定理 (欧拉降幂)
\[a^b \equiv \begin{cases} a^{b \bmod \varphi(m)}, &\gcd(a,m) = 1, \\ a^b, &\gcd(a,m)\ne 1, b < \varphi(m), \\ a^{(b \bmod \varphi(m)) + \varphi(m)}, &\gcd(a,m)\ne 1, b \ge \varphi(m). \end{cases} \pmod m\]第一个要求a和m互质,第二个和第三个是广义欧拉降幂,不要求a和m互质,但要求b和phi(m)的大小关系。
P5091 【模板】扩展欧拉定理 - 洛谷 (luogu.com.cn)
求$a^B \% m$
#include <iostream>
using namespace std;
int phi(int n){
int ans = n;
for(int i = 2;i <= n/i;i++){
if(n%i == 0){
ans = ans/i*(i-1);
while(n % i == 0){n /= i;}
}
}
if(n >= 2) ans = ans/n*(n-1);
return ans;
}
long long qmi(long long a,long long b,long long p){
long long ans = 1;
while(b){
if(b&1) ans = ans*a%p;
b >>= 1;
a = a*a%p;
}
return ans%p;
}
int mo(string &b,int pm){//高精度取模,顺便与phi(m)比较大小
int ans = 0;
bool flag = 0;
for(int i = 0;i < b.size();i++){
int x = b[i] - '0';
ans = ans*10+x;
if(ans >= pm) flag = 1;
ans %= pm;
}
if(flag) return ans+pm;//b >= phi(m)
return ans;//b < phi(m)
}
int main(){
int a,m;string b;cin >> a >> m >> b;
int pm = phi(m);
int ans = qmi(a,mo(b,pm),m);
cout << ans;
}
P4139 上帝与集合的正确用法 - 洛谷 (luogu.com.cn)
给定 p,求$2^{2^{2^{2^{…}}}}\%p$
即 $a_0 = 1,a_n = 2^{a_{n-1}}$,可以证明$b_n = a_n\ mod\ p$在某一项后都是同一个值,求这个值。
#include <iostream>
using namespace std;
const int N = 10000007;
int p;
int phi[N],primes[N],cnt;
bool st[N];
void get_phi(int n){
phi[1] = 1;
for(int i = 2;i <= n;i++){
if(!st[i]) {
primes[++cnt] = i;
phi[i] = i-1;
}
for(int j = 1;primes[j] <= n/i;j++){
st[i*primes[j]] = 1;
if(i%primes[j] == 0){
phi[i*primes[j]] = phi[i]*primes[j];
break;
}
else phi[i*primes[j]] = phi[i]*(primes[j]-1);
}
}
}
long long qmi(long long a,long long b,long long p){
long long ans = 1;
while(b){
if(b&1) ans = ans*a%p;
b >>= 1;
a = a*a%p;
}
return ans%p;
}
int sol(int p){
if(p == 1) return 0;
return qmi(2,sol(phi[p])+phi[p],p);
}
int main(){
get_phi(N-1);
int t;cin >> t;
while(t--){
cin >> p;
cout << sol(p) << '\n';
}
}
[P10414 蓝桥杯 2023 国 A] 2023 次方 - 洛谷 (luogu.com.cn)
求$2^{3^{4^{…^{2023}}}} \% 2023$
int sol(int a,int p){
if(p == 1) return 0;
return qmi(a,sol(a+1,phi[p])+phi[p],p);
}
cout << sol(2,2023) << '\n';
模数
$a \% b$ 也可以表示为 $a - \lfloor \frac{a}{b} \rfloor * b$
c++取模运算中 -7%4 = -3 而数学取模中 -7 % 4 = 4 题目往往要求数学取模
int f(int x,int mod){//将c++取模转为数学取模
return (x % mod + mod) % mod;
}
运算法则
模运算与基本四则运算有些相似,但是[除法例外][详见:乘法逆元]。其规则如下: (a + b) % p = (a % p + b % p) % p (a - b) % p = (a % p - b % p ) % p (a * b) % p = (a % p * b % p) % p (a * b * c)%p=(a%p * b%p * c%p) % p (a ^ b) % p = ((a % p) ^ b) % p
同余定理
同余定理:给定一个正整数m,如果两个整数a和b满足a-b能够被m整除,那么就称整数a与b对模m同余,$a-b≡0(mod\ m)$,记作$a≡b(mod\ m)$。对模m同余是整数的一个等价关系。
若数组a[ ]的所有元素对 m 取余相同,则任意两个元素的差都能被 m 整除。m 必须是区间内所有元素两两差值的最大公约数 GCD。即$m = GCD(a_{l+1}-a_l,a_{l+2}-a_{l+1},…,a_r - a_{r-1})$。https://codeforces.com/contest/2050/problem/F
线性同余
扩展欧几里得算法求线性同余方程$ax\equiv b\ (mod\ m)$,因为未知数$x$的指数为1,所以称作线性同余或一次同余。
给定$a,b,m$,求出$x$使得$ax\equiv b\ (mod\ m)$,如果无解则输出impossible。
问题等价于$ax-b$是$m$的倍数,假设为$-y$倍,则问题可转化为$ax+my=b$求解$x$。
//https://www.acwing.com/problem/content/880/
#include <iostream>
using namespace std;
int exgcd(int a,int b,int &x,int &y){
if(!b){
x = 1,y = 0;
return a;
}
int d = exgcd(b,a%b,x,y);
int x1 = x,y1 = y;
x = y1;
y = x1 - a/b*y1;
return d;
}
int f(int a,int b,int m){
int x,y,d = exgcd(a,m,x,y);
if(b%d) return -1;//诺不能整除最大公约数则无解
int t = std::abs(m/d);
return ((long long)x*(b/d) % t + t ) % t;//返回最小正整数解
}
int main(){
int q;cin >> q;
while(q--){
int a,b,m;cin >> a >> b >> m;
int x = f(a,b,m);
if(x == -1) cout << "impossible\n";
else cout << x << '\n';
}
}
高次同余
BSGS
求解$a^x \equiv b (mod\ p)$的最小非负整数解$x$(或返回无解),其中a,p互质,$2\le a,b < p < 2^{31}$。
BSGS(baby-step giant-step,大步小步算法)常用于求解离散对数问题,该算法可以在$O( \sqrt N)$ 的时间内求解(用map则多一个log)。
//模版题 https://www.luogu.com.cn/problem/P3846
int bsgs(int a,int b,int p){//无解则返回-1,否则返回最小非负整数解
map<int,int>hs;
b %= p;
int t = (int)sqrt(p) + 1;
for(int j = 0;j < t;j++){
int val = (long long) b * qmi(a,j,p) % p;
hs[val] = j;
}
a = qmi(a,t,p);
if(a == 0) return b == 0 ? 1 : -1;
for(int i = 0;i <= t;i++){
int val = qmi(a,i,p);
int j = hs.find(val) == hs.end() ? -1 : hs[val];
if(j >= 0 && i * t - j >= 0) return i * t - j;
}
return -1;
}
扩展BSGS
求解$a^x \equiv b (mod\ p)$的最小非负整数解$x$(或返回无解),其中a,p不一定互质,$1\le a,b,p \le 10^9$或$a=b=p=0$。
//模版题 https://www.luogu.com.cn/problem/P4195
int exbsgs(int a,int b,int p){
a%=p; b%=p;
if(b == 1 || p == 1) return 0;
int d,ax=1,cnt=0,x,y;
while((d=exgcd(a,p,x,y))^1){
if(b%d) return -1;
b/=d; p/=d; cnt++;
ax=1ll*ax*(a/d)%p;
if(ax == b) return cnt;
}
exgcd(ax,p,x,y);
int inv=(x%p+p)%p;
b=1ll*b*inv%p;
//下面为bsgs
map<int,int>hs;
b %= p;
int t = (int)sqrt(p) + 1;
for(int j = 0;j < t;j++){
int val = (long long) b * qmi(a,j,p) % p;
hs[val] = j;
}
a = qmi(a,t,p);
if(a == 0) return b == 0 ? 1 : -1;
for(int i = 0;i <= t;i++){
int val = qmi(a,i,p);
int j = hs.find(val) == hs.end() ? -1 : hs[val];
if(j >= 0 && i * t - j >= 0) return i * t - j + cnt;//这里+cnt
}
return -1;
}
乘法逆元
费马小定理:对于任何一个整数a,以及素数p: 1.如果a是p的倍数,$a^p ≡ a (mod\ p)$ 2.如果a不是p的倍数,$a^{p-1} ≡ 1 (mod\ p)$
将上述公式2变形得到: $a * a^{p-2} ≡ 1 (mod\ p)$ $a^{p-2} ≡ a^{-1} (mod\ p)$ 所以:$a^{-1} ≡ a^{p-2} (mod\ p)$ 其中a和p互质(有逆元的充要条件) $\frac{a}{b}\%p = ab^{p-2}\% p = a\%pb^{p-2}\%p$
//快速幂求逆元
//给定n组a,p,其中p是质数,求a模p的乘法逆元,若逆元不存在则输出impossible
#include <iostream>
using namespace std;
using ll = long long;
ll qmi(ll a,ll b,ll p){
ll ans = 1;
while(b){
if(b&1) ans = ans*a%p;
b>>=1;
a = a*a%p;
}
return ans%p;
}
ll gcd(ll a,ll b){return b?gcd(b,a%b):a;}
int main(){
int t;cin >> t;
while(t--){
int a,p;cin >> a >> p;
if(gcd(a,p) != 1) cout << "impossible" << endl;
//a有逆元的充要条件是a与p互质
else cout << qmi(a,p-2,p) << endl;
}
}
$\frac{1}{ab} \% mod= qmi(a,mod-2)qmi(b,mod-2)\%mod$
中国剩余定理
扩展中国剩余定理(EXCRT):模数不互质
$\begin{cases}
x &\equiv m_1 \pmod {a_1}
x &\equiv m_2 \pmod {a_2}
&\vdots
x &\equiv m_n \pmod {a_n}
\end{cases}$
给定 a[1~n] 和 m[1~n],求一个最小的非负整数 𝑥,满足∀𝑖∈[1,𝑛],𝑥 ≡ 𝑚𝑖(𝑚𝑜𝑑 𝑎𝑖)。 输出最小非负整数解 𝑥,如果 𝑥 不存在,则输出 −1。$a \geqslant 1,0 \leqslant m < a$,ai之间可以不互质
选第一个式子和第二个式子有: $x≡m_1(mod\ a_1)$,$x≡m_2(mod\ a_2)$ $\Longrightarrow x = k_1a_1 + m_1$,$x = k_2a_2+m_2$ //即求最小非负整数k1 $\Longrightarrow k_1a_1+m_1 = k_2a_2+m_2$ $\Longrightarrow k_1a_1-k_2a_2=m_2-m_1$ —————-①
令d = exgcd(a1,-a2),解为$k_1’,k_2’$ 如果m2-m1不能整除d则无解,返回-1 否则一对整数解为$k1 = (m2-m1)/dk_1’ , k2 = (m2-m1)/dk_2’$
对于①式又有性质$k_1=(k_1+\frac{ka_2}{d})$,$k_2=(k_2+\frac{ka_1}{d})$ k1最小非负整数解为$k_1 = k_1\%|\frac{a_2}{d}|$ //不确定d的正负,取绝对值
$x = (k_1 + \frac{ka_2}{d})a_1 + m_1$ $\Longrightarrow x=k_1a_1+m_1 + k\frac{a_1a_2}{d}$ $\Longrightarrow x = k_1a_1+m_1+k*lcm(a_1,a_2)$ 令$m_0 = k_1a_1+m_1$,$a_0 = lcm(a_1a_2)$ 则$x = ka_0+m_0$ //再用此式子与其它式子依次递推,x=m即为当前x最小正整数解
给定 $n$ 组非负整数 $a_i, b_i$ ,求解关于 $x$ 的方程组的最小非负整数解。
\[\begin{cases}x\equiv b_1\pmod{a_1}\\x\equiv b_2\pmod{a_2}\\\dots\\x\equiv b_n\pmod{a_n}\end{cases}\]时间复杂度$O(N)$
//https://www.luogu.com.cn/problem/P4777
//数据略强:q <= 1e5;a[i],b[i] <= 1e12;
#include <iostream>
#include <vector>
using namespace std;
const int N = 100005;
struct node{
long long a,b;
};
long long exgcd(long long a,long long b,long long& x,long long& y){
if(!b){
x = 1,y = 0;
return a;
}
long long d = exgcd(b,a%b,x,y);
long long x1 = x,y1 = y;
x = y1,y = x1 - a/b*y1;
return d;
}
long long excrt(const std::vector<node> &e){//0_idx
long long ans = e[0].b,M = e[0].a,x = 0,y = 0;
for(int i = 1;i < e.size();i++){
long long B = ((e[i].b - ans) % e[i].a + e[i].a) % e[i].a;
long long d = exgcd(M,e[i].a,x,y);
if(B%d) {return -1;}//诺B不能整除最大公约数d,则无解。
x = (__int128)x*(B/d) % e[i].a;//__int128或龟速乘防止爆long long
ans += M*x;
M *= e[i].a / d;
ans = (ans + M) % M;//ans即为前i(0_idx)个柿子的解
}
return ans;
}
int main(){
int n;cin >> n;
std::vector<node>e(n);
for(int i = 0;i < n;i++) {
std::cin >> e[i].a >> e[i].b;//x%a == b
}
cout << excrt(e);
}
数论分块
快速求解形如$\sum_{i=1}^{n}{f(i)g(\lfloor \frac{n}{i} \rfloor)}$ 的和式。当可以在$O(1)$内计算$f(r) - f(l)$或已经预处理出$f$的前缀和时,数论分块就可以在$O(\sqrt N)$的时间内计算上述和式的值。
[P2261 CQOI2007] 余数求和 - 洛谷 (luogu.com.cn)
给定n,k,求$\sum_{i=1}^{n}{k\%i}$ 。
$原式 = \sum_{i=1}^{n}{(k - i * \lfloor \frac{k}{i} \rfloor)} = n*k - \sum_{i=1}^{n}{(i * \lfloor \frac{k}{i} \rfloor)}$
例如样例 n = 10,k = 5
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| $t = \lfloor \frac{k}{i} \rfloor$ | 5 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
发现$\lfloor \frac{k}{i} \rfloor$分别在一定的区域内相等。 左端点$l$从1开始枚举,令$t = \lfloor \frac{k}{l} \rfloor$,则数值$t$所在的右端点$r = \lfloor \frac{k}{t} \rfloor$,在区间$[l, r]$内$t$的值相等,于是我们可以快速求出这一段区间的取值,再让$l = r + 1$。
#include <iostream>
using namespace std;
int main(){
long long n,k;cin >> n >> k;
long long ans = n * k;
for(int l = 1,r;l <= n;l = r + 1){
long long t = k/l;
if(t == 0) r = n;
else r = min(k/t,n);
ans -= t * (l+r)*(r-l+1)/2;//区间[l,r]值均为t,快速计算
}
cout << ans;
}
其它
一些数学常数
圆周率: π = acos(-1) = 3.14159265358979323846264338327950288419716939937510
自然常数: e = 2.7182818284590452353602874713526624977572470936999595749
⑨的倍数
如果一个数能整除9,那么它的所有位数之和也能整除9
x个k连在一起组成的正整数
可以表示为 $\frac{k(10^x-1)}{9}$ ,如x = 6,k = 8,f(x,k) = 888888
一堆正整数相乘后,末尾0的个数
cnt2统计所有乘数中质因数2的个数
cnt5统计所有乘数中质因数5的个数
则末尾0的个数 =min(cnt2,cnt5)
组合数学
排列组合
排列(nPr):$A_n^m = \frac{n!}{(n-m)!} = \underbrace{n(n-1)(n-2)…(n-m+1)}_{m个因子}$
组合(nCr):$C_n^m = \frac{A_n^m}{m!} = \frac{n!}{m!(n-m)!}$
A[7,3] = 7 * 6 * 5 = 210 C[7,3] = (7 * 6 * 5)/(3 * 2 * 1) = 6
性质
$C_n^m = C_{n-1}^{m-1} + C_{n-1}^{m}$
$C_n^0+C_n^1+…+C_n^n = 2^n$
$C_n^m = C_n^{n-m}$
组合数判定奇偶:对于C(n,m),诺 n&m==m 则为奇数,否则为偶数。
多重集
多重集是指包含重复元素的广义集合,设 S = {$n_1个a_1,n_2个a_2,…,n_k个a_k$}
S的全排列个数$A = \frac{n!}{n_1!n_2!···n_k!}$
从S中选 r ($r <= n_k$)个元素组成一个多重集,产生的不同多重集的数量为$C_{k+r-1}^{k-1}$
二项式定理
$(a+b)^n = \sum_{k=0}^n{C_n^ka^kb^{n-k}}$
一些常见的组合计数
n*m的网格从左上角(1,1)走到右下角(n,m),每次只能往下或右走,不同的路径的总数$C_{n+m-2}^{n-1}$或$C_{n+m-2}^{m-1}$种
需要的总步数为n+m-2,其中向下走n-1步,向右走m-1步,不同的路径总共有$C_{n+m-2}^{n-1}$或$C_{n+m-2}^{m-1}$种。
n个相同的物品分成m组,每组至少1个元素的方案数:$C_{n-1}^{m-1}$
考虑拿
m-1个板子插到n个元素形成的n-1个空里面,将物品分成m组。答案就是$C_{n-1}^{m-1}$。 本质是求$x_1+x_2+…+x_m=n$的正整数解的组数。其中$x_i \ge 1$
n个相同的物品分成m组,每组可以有0个元素的方案数:$C_{n+m-1}^{n}$或$C_{n+m-1}^{m-1}$
显然此时没法直接插板了,因为可能出现很多块板子插到同一个空里面,不好计算。 先借m个元素过来,在这n+m个形成的
n+m-1个空里面插入m-1个板子,方案数为$C_{n+m-1}^{n}$或$C_{n+m-1}^{m-1}$。 开头借了m个元素用于保证每组至少有一个元素,插完板后将借来的m个元素删除,因为元素是相同的,所以转化过的情况和转化前的情况可以一一对应,答案也就是相等的。 也相当于是求多重集{n个物品,m-1个板子}的全排列数。本质是求$x_1+x_2+…+x_m=n$的非负整数解的组数。其中$x_i \ge 0$
n个物品分成m组,要求对于第$i$组,至少要分到$a_i$个元素($\sum{a_i\le n}$),方案数为$C_{n-\sum{a_i}+m-1}^{n-\sum{a_i}}$
类比上一个问题,我们借$\sum{a_i}$个元素过来,保证第$i$组至少能分到$a_i$个,也就是令$x^{\prime} = x_i - a_i$。 得到新方程: \(\begin{aligned} (x_1^{\prime}+a_1)+(x_2^{\prime}+a_2)+\cdots+(x_k^{\prime}+a_k)&=n\\ x_1^{\prime}+x_2^{\prime}+\cdots+x_k^{\prime}&=n-a_1-a_2-\cdots-a_k\\ x_1^{\prime}+x_2^{\prime}+\cdots+x_k^{\prime}&=n-\sum a_i \end{aligned}\) 其中$x_i^{\prime} \ge 0$。然后就转化为了上一个问题,直接用插板法公式得到答案为$C_{n-\sum{a_i}+m-1}^{n-\sum{a_i}}$
本质是求$x_1+x_2+…+x_m = n$的解的数目,其中$x_i \ge a_i$
从1~n的自然数中选m个,且这m个数中任意两个数差值大于k的方案有$C_{n-k(m-1)}^{m}$种。(其中$n-k(m-1)\ge m$,否则为0种。)
例题:Don’t be too close(★6) - AtCoder typical90_o - (vjudge.net)
杨辉三角
O($N^2$) 预处理 O(1)询问
$C_n^m = C_{n-1}^{m-1} + C_{n-1}^{m}$
const int mod = 1e9+7,N = 2005;
long long C[N][N];
void init() {//初始化
for (int i = 0; i <= 2000 ; i ++ ){
for (int j = 0; j <= i; j ++ ){
if (!j) C[i][j] = 1;
else C[i][j] = (C[i - 1][j] + C[i - 1][j - 1]) % mod;
}
}
}
逆元求组合数
$O(N)$预处理 O(1)询问
$C_n^m = \frac{n!}{m!(n-m)!}\ \%P= n!(m!^{P-2})(n-m)!^{P-2}\ \%P$
#include <iostream>
using ll = long long;
using namespace std;
const int N = 100005,P = 1e9+7;
ll fact[N],infact[N];
ll qmi(ll a,ll b,ll p){
ll ans = 1;
while(b){
if(b&1) ans = ans * a % p;
b >>= 1;
a = a * a % p;
}
return ans%p;
}
void initi(){
fact[0] = infact[0] = 1;//0的阶乘等于1
for(int i = 1;i < N;i++){//预处理阶乘
fact[i] = fact[i-1]*i%P;
}
infact[N-1] = qmi(fact[N-1],P-2,P);//预处理阶乘的逆元,倒着处理只用算一次快速幂求逆元
for(int i = N - 2;i >= 1;i--){
infact[i] = infact[i+1]*(i+1)%P;
}
}
ll C(int a,int b){
//if(a < b) return 0;
return fact[a]*infact[b]%P*infact[a-b]%P;
}
int main(){
initi();
int t;cin >> t;
while(t--){
int a,b;cin >> a >> b;
cout << C(a,b) << '\n';
}
}
卢卡斯定理
$M\le N \le 10^{18},P \le 10^5$,其中$P$为质数
O($P\ logN\ logP$)询问
$C_n^m≡C_{n/p}^{m/p} C_{n\%p}^{m\%p} (mod\ p)$
#include <iostream>
using namespace std;
using ll = long long;
ll qmi(ll a,ll b,ll p){
ll ans = 1;
while(b){
if(b&1) ans = ans*a%p;
b >>= 1;
a = a*a%p;
}
return ans%p;
}
ll C(ll a,ll b,ll p){//O(blogP)朴素求组合数
ll ans = 1;
for(int i = 1,j = a;i <= b;i++,j--){
ans = ans*j%p;
ans = ans*qmi(i,p-2,p)%p;
}
return ans;
}
ll lucas(ll a,ll b,ll p){
if(a < p && b < p) return C(a,b,p);
return C(a%p,b%p,p)*lucas(a/p,b/p,p)%p;
}
int main(){
int q; cin >> q;
while(q--){
ll a,b,p; cin >> a >> b >> p;
cout << lucas(a,b,p) << endl;
}
return 0;
}
高精度排列组合
$n,m \le 5000$
阶乘质因数分解+高精度乘法
博客:阶乘(n!)的素因数分解_正整数 (sohu.com)
算术基本定理:任意一个大于1的正整数n,它都可以分解为以下形式,其中p为质数,a为正整数 $n = P_1^{a_1}P_2^{a^2}…P_k^{a_k}$ $m = P_1^{b_1}P_2^{b^2}…P_k^{b_k}$ $n-m = P_1^{c_1}P_2^{c^2}…P_k^{c_k}$ 其中
P[]为n以内的所有素数 \(则有C_n^m =\frac{n!}{m!(n-m)!} = \prod p_i^{a_i - b_i - c_i}\)
//https://www.acwing.com/problem/content/890/
#include <iostream>
#include <vector>
using namespace std;
const int N = 5003;
int primes[N],cnt;
bool st[N];
int sum[N];
void initi(int n){
for(int i = 2;i <= n;i++){
if(!st[i]) primes[++cnt] = i;
for(int j = 1;primes[j] <= n/i;j++){
st[primes[j]*i] = 1;
if(i % primes[j] == 0) break;
}
}
}
int get(int n,int p){//计算n!里面分解为p^k的k值
//12! = 1*2*3*4*5*6*7*8*9*10*11*12
//p = 2 {2,4,6,8,10,12} ans+=6
//p^2 = 4 {4,8,12} ans+=3
//p^3 = 8 {8} ans+=1
//get(12,2) = 6+3+1 = 10
int ans = 0;
while(n){
ans += n/p;
n/=p;
}
return ans;
}
vector<int> mul(vector<int>&A,int b){
vector<int>C;
int t = 0;
for(int i = 0;i < A.size();i++){
t += A[i]*b;
C.push_back(t%10);
t /= 10;
}
while(t){
C.push_back(t%10);
t/=10;
}
return C;
}
int main(){
int a,b;cin >> a >> b;
initi(a);
for(int i = 1;i <= cnt;i++){
int p = primes[i];
sum[i] = get(a,p) - get(b,p) - get(a-b,p);
}
vector<int>A(1,1);
for(int i = 1;i <= cnt;i++){
for(int j = 1;j <= sum[i];j++){//A *= primes[i]^sum[i]
A = mul(A,primes[i]);
}
}
for(int i = A.size()-1;i >= 0;i--){
cout << A[i];
}
return 0;
}
错位排列
没有任何元素出现在原有位置的排列。即,对于1~n的排列P,如果满足$P_i \neq i$,则称P是n的错位排列。 如三元错位排列有:${2,3,1}$ 和 ${3,1,2}$
递推关系式: \(D_n = (n-1)(D_{n-1}+D_{n-2}) = n(D_{n-1} + (-1)^n)\)
//递推计算错位排列数列 O(N)
a[0] = 1;
for(int i = 1;i < N;i++){
a[i] = i*a[i-1] + (i&1?-1:1);
}
for(int i = 1;i < N;i++) cout << a[i] << ' ';//0 1 2 9 44 265 ...
其它关系:
错位排列数有一个简单的取整表达式,增长速度与阶乘仅相差常数:$D_n=\begin{cases}
\left\lceil\frac{n!}{\mathrm{e}}\right\rceil, & n为偶数
\left\lfloor\frac{n!}{\mathrm{e}}\right\rfloor, & n为奇数
\end{cases}$
随着元素数量的增加,形成错位排列的概率 P 接近:$P=\lim_{n\to\infty}\frac{D_n}{n!}=\frac{1}{\mathrm{e}}$
容斥原理
\[|A\cup B\cup C|=|A|+|B|+|C|-|A\cap B|-|B\cap C|-|C\cap A|+|A\cap B\cap C|\]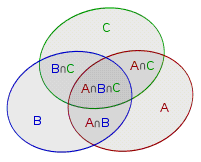 把上述问题推广到一般情况,就是我们熟知的容斥原理
把上述问题推广到一般情况,就是我们熟知的容斥原理
把包含于某内容中的所有对象的数目先计算出来,然后再把计数时重复计算的数目排斥出去,使得计算的结果既无遗漏又无重复
\[\begin{aligned} \left|\bigcup_{i=1}^{n}S_i\right|=&\sum_{i}|S_i|-\sum_{i<j}|S_i\cap S_j|+\sum_{i<j<k}|S_i\cap S_j\cap S_k|-\cdots\\ &+(-1)^{m-1}\sum_{a_i<a_{i+1} }\left|\bigcap_{i=1}^{m}S_{a_i}\right|+\cdots+(-1)^{n-1}|S_1\cap\cdots\cap S_n| \end{aligned}\]即
\[\left|\bigcup_{i=1}^{n}S_i\right|=\sum_{m=1}^n(-1)^{m-1}\sum_{a_i<a_{i+1} }\left|\bigcap_{i=1}^mS_{a_i}\right|\]//https://www.acwing.com/problem/content/description/892/
//给定一个整数 n 和 m 个不同的质数 p1,p2,…,pm。
//请你求出 1∼n中能被 p1,p2,…,pm 中的至少一个数整除的整数有多少个。
#include <iostream>
using namespace std;
using ll = long long;
int p[20];
ll ans = 0;
int main(){
int n,m;cin >> n >> m;
for(int i = 1;i <= m;i++){
cin >> p[i];
}
for(int i = 1;i < 1 << m;i++){//二进制1~11...11枚举所有状态
ll cnt = 0,t = 1;
for(int k = 0;k < m;k++){
if(i >> k & 1){
cnt++;
t *= p[k+1];
if(t > n){t = -1;break;}
}
}
if(t == -1) continue;
if(cnt&1) ans += n/t;
else ans -= n/t;
}
cout << ans;
return 0;
}
数列
等差/等比
等差数列
通项公式:$a_n = a_1 + (n-1)*d$
求和公式:$S_n = \frac{(a_1+a_n)*n}{2}$
等比数列
\[\sum_{x=1}^{n}{x} = {\frac{n(n+1)}{2}}\] \[\sum_{x=1}^{n}{x^2} = \frac{n(n+1)(2n+1)}{6}\] \[\sum_{x=1}^{n}{x^3} = {(\sum_{x=1}^{n}{x})^2} = (\frac{n(n+1)}{2})^2\]通项公式:$a_n = a_1*q^{n-1}$
求和公式:$\begin{cases} S_n = \frac{a_1(q^n-1)}{q-1}\ \quad (q\ !=1)
S_n = n*a_1 \qquad (q == \ 1) \end{cases}$诺无法求逆元可以考虑递归:$S(k) = \begin{cases} A \qquad\qquad\qquad\qquad\qquad\ \ k = 1
S(k-1)+A^k \qquad \qquad \quad \ k为奇数\
S(k/2) + S(k/2)*A^\frac{k}{2} \qquad k为偶数
\end{cases}$
数列递推
求解递推数列 $a_n = a_{n-1} + k*n + b$ 的第 n 项(其中 k,b 为常数)
$a_n = a_1 + \sum_{i=2}^{n}(ki+b) = a_1 + k\sum_{i=2}^{n}{i} + b\sum_{i=2}^{1}$
其中 $\sum_{i=2}^{n}{i} = \frac{n(n+1)}{2}-1$ , $\sum_{i=2}^{n}{1}=n-1$
代入求和得$a_n = \frac{k}{2}n^2 + (b+\frac{k}{2})n + (a_1-b-k)$
斐波那契
斐波那契数列相关 - zhoukangyang - 博客园 (cnblogs.com)
f(0) = 0,f(1) = 1,f(n) = f(n-2)+f(n-1)
0 1 1 2 3 5 8 13 21 ….
快速倍增法
O(logN) 询问 比矩阵乘法常数更小,返回值为pair<Fib(n),Fib(n+1)>;
$F_{2k} = F_k (2 F_{k+1} - F_{k}) $ $F_{2k+1} = F_{k+1}^2 + F_{k}^2$
pair<ll,ll> fib(ll n) {
if (n == 0) return {0,1};
auto [a,b] = fib(n >> 1);
ll c = a * (2*b%mod - a + mod)%mod;
ll d = (a*a%mod + b*b%mod)%mod;
if (n&1) return {d,c+d};
else return {c,d};
}
//cout << fib(n).first;
一些性质
- 卡西尼性质:$F_{n-1} F_{n+1} - F_n^2 = (-1)^n$。
- 附加性质:$F_{n+k} = F_k F_{n+1} + F_{k-1} F_n$。
- 取上一条性质中 $k = n$,我们得到 $F_{2n} = F_n (F_{n+1} + F_{n-1})$。
-
由上一条性质可以归纳证明,$\forall k\in \mathbb{N},F_n F_{nk}$。 -
上述性质可逆,即 $\forall F_a F_b,a b$。 - GCD 性质:$GCD(F_n, F_m) = F_{GCD(n, m)}$。
广义斐波那契数列
O(logN)询问
例:求 $f(n) = p*f(n-1) + q * f(n-2)$
可以得到矩阵公式: $\begin{bmatrix} f(n) & f(n-1) \end{bmatrix} = \begin{bmatrix} f(n-1) & f(n-2) \end{bmatrix} \times \begin{bmatrix} p & 1 \ q & 0\ \end{bmatrix}$
$ans = \begin{bmatrix} f(2) & f(1) \ 0 & 0\ \end{bmatrix}$
$base = \begin{bmatrix} p & 1 \ q & 0\ \end{bmatrix}$
利用矩阵快速幂求 $ans*base^{n-2}$,对于n <= 2的情况,直接输出答案即可(因为第一次相乘即得到F[3],所以是n-2次方)
有关base转移矩阵的构造:$F[N] = pF[n-1]+qF[n-2]$ , $F[N-1] = 1F[N-1] + 0F[N-2]$ 实际是转为了二维:$F[i][0] = F[i-1][0]p + F[i-1][1]q$ , $F[i][1] = F[i-1][0]*1$
| F[n] | F[n-1] | |
|---|---|---|
| F[n-1] | p | 1 |
| F[n-2] | q | 0 |
//https://www.luogu.com.cn/problem/P1349
//给定p,q和前两项f(1),f(2) 求f(n)%mod
#include <iostream>
using namespace std;
int mod;
struct mat{
long long a[2][2];
};
mat operator * (const mat &a,const mat &b){
mat ans = {};
for(int i = 0;i < 2;i++){
for(int j = 0;j < 2;j++){
for(int k = 0;k < 2;k++){
ans.a[i][j] = (ans.a[i][j] + a.a[i][k] * b.a[k][j]) % mod;
}
}
}
return ans;
}
mat qmi(mat a,long long b){
mat ans = {};
for(int i = 0;i < 2;i++){
ans.a[i][i] = 1;
}
while(b){
if(b & 1) ans = ans * a;
b >>= 1;
a = a * a;
}
return ans;
}
int main(){
int p,q,a1,a2,n; cin >> p >> q >> a1 >> a2 >> n >> mod;
if(n == 1){cout << a1;return 0;}
if(n == 2){cout << a2;return 0;}
mat ans = {a2,a1};
mat base = {p,1,q,0};
ans = ans * qmi(base,n-2);
cout << ans.a[0][0];
}
皮萨诺周期
模p意义下的斐波那契数列最下正周期被称为皮萨诺周期。 皮萨诺周期总是不超过6p,且只有在$p=2*5^k$形式下才取得等号
当需要计算第 $n$ 项斐波那契数模 $m$ 的值的时候,如果 $n$ 非常大,就需要计算斐波那契数模 $m$ 的周期。当然,只需要计算周期,不一定是最小正周期。
如果 $a$ 与 $b$ 互素,$ab$ 的皮萨诺周期就是 $a$ 的皮萨诺周期与 $b$ 的皮萨诺周期的最小公倍数
//https://codeforces.com/contest/2033/problem/F
//G(n,k)为第n个能被k整除的数的下标 n<=1e18,k<=1e5
//暴力找出第一次能被k整除时的下标i,n*i即为第n个能被k整除的下标
void sol(){
ll n,k;cin >> n >> k;
ll l = 0,r = 1;
for(ll i = 1;;i++){
tie(l,r) = make_pair(r%k,(l+r)%k);
if(!l) { cout << n%mod*i%mod << '\n'; return; }
}
}
卡特兰数
组合数学中一个常出现在各种计数问题中出现的数列
卡特兰数(Catalan)公式、证明、代码、典例._卡特兰数公式
1,1,2,5,14,42,132,429…(从第0项开始)
通项公式:$h(n) = \frac{1}{n+1}C_{2n}^n$
递推公式:$h[0] = 1、h[i] = \frac{2(2i-1)}{i+1}h[i-1]$
例:n对括号有多少种匹配方式?(诺有k种括号,则答案为$h(n)*k^n$) 求n个节点能够构成的不同的二叉树的个数? 一个栈的进栈序列为1,2,3,…,n有多少个不同的出栈序列? 给出一个n,要求一个长度为2n的01序列,使得序列的任意前缀中1的个数不少于0的个数, 有多少个不同的01序列?
//组合数求卡特兰数
//O(N)预处理,O(logN)询问
#include <iostream>
using namespace std;
using ll = long long;
const int N = 200005,P = 1e9+7;
int n;
ll fact[N],infact[N];
ll qmi(ll a,ll b,ll p){
ll ans = 1;
while(b){
if(b&1) ans = ans*a%p;
b >>= 1;
a = a*a%p;
}
return ans;
}
void init(){
fact[0] = infact[0] = 1;
for(int i = 1;i < N;i++){
fact[i] = fact[i-1]*i%mod;
}
infact[N-1] = qmi(fact[N-1],mod-2,mod);
for(int i = N-2;i >= 1;i--){
infact[i] = infact[i+1]*(i+1)%mod;
}
}
ll C(int a,int b,int p){
return fact[a]*infact[b]%p*infact[a-b]%p;
}
int main(){
cin >> n;
initi();
cout << C(2*n,n,P)*qmi(n+1,P-2,P)%P;
}
//递推求卡特兰数
//O(NlogN)预处理,O(1)询问
#include <iostream>
using namespace std;
using ll = long long;
const int N = 200005, P = 1e9+7;
ll h[N];
ll qmi(ll a,ll b,ll p){
ll ans = 1;
while(b){
if(b&1) ans = ans*a%p;
b >>= 1;
a = a*a%p;
}
return ans;
}
int main(){
int n;cin >> n;
h[0] = 1;
for(int i = 1;i <= n;i++){
h[i] = (4*i - 2)*h[i-1]%P*qmi(i+1,P-2,P)%P;
}
cout << h[n];
}
#python大法 高精度求卡特兰数
import math
n = int(input())
A = math.factorial(2 * n)
B = math.factorial(n)
ans = A/B/B/(n+1);
print(ans)
贝尔数 (集合划分)
\[B_0 = 1,B_1 = 1,B_2=2,B_3=5,B_4=15,B_5=52,B_6=203,\dots\]$B_n$ 是基数为 $n$ 的集合的划分方法的数目。集合 $S$ 的一个划分是定义为 $S$ 的两两不相交的非空子集的族,它们的并是 $S$。例如 $B_3 = 5$ 因为 3 个元素的集合 ${a, b, c}$ 有 5 种不同的划分方法:
\[\begin{aligned} &\{ \{a\},\{b\},\{c\}\} \\ &\{ \{a\},\{b,c\}\} \\ &\{ \{b\},\{a,c\}\} \\ &\{ \{c\},\{a,b\}\} \\ &\{ \{a,b,c\}\} \\ \end{aligned}\]//O(N^2)预处理 O(1)询问
//贝尔三角形,每行的首项是贝尔数
const int N = 2003,mod = 1e9+7;
void get_bell(int n) {
bell[0][0] = 1;
for (int i = 1; i <= n; i++) {
bell[i][0] = bell[i-1][i-1];
for (int j = 1; j <= i; j++)
bell[i][j] = (bell[i-1][j-1] + bell[i][j-1])%mod;
}
}
for(int i = 0;i <= n;i++) cout << bell[i][0] << endl;
康托展开 (全排列排名)
康托展开:给定一个长度为N的全排列a[ ],求它是第几个排列。 逆康托展开:给点一个全排列的长度N,求第rk个排列是什么?
重要柿子:$rk = \sum_{i=1}^{n}{S(i) * (n-i)!}$
S(i)表示1 ~ a[i]-1中未出现过的数的个数,它可以看作是一种特殊的进制,也叫做阶乘进制。
如:$(463){10} = (341010){!} = 3\times 5!+4\times 4!+1\times 3!+0\times 2!+1\times 1!+0\times 0!$
时间复杂度$O(NlogN)$
假设原排列为a[ ],阶乘进制为s[ ],排名为rk,下面直接给出转换代码(排名从0开始,数组下标均从1开始) $a[\ ] \rightleftharpoons s[\ ] \rightleftharpoons rk$
vector<long long> a_to_s(int n,vector<long long>&a){
vector<long long>s(n+1);
vector<long long>t(n+1);
auto add = [&](int i,int x){
while(i <= n){
t[i] += x;
i += i&-i;
}
};
auto query = [&](int i)->long long{
long long ans = 0;
while(i){
ans += t[i];
i -= i&-i;
}
return ans;
};
for(int i = 1;i <= n;i++){
add(i,1);
}
for(int i = 1;i <= n;i++){
s[i] = query(a[i]-1);
add(a[i],-1);
}
return s;
}
vector<long long> s_to_a(int n,vector<long long>&s){
vector<long long>a(n+1);
struct st{
int l,r,sum;
};
st* t = new st[(n<<2)+5];//权值线段树,求全局第k小
auto pushup = [&](int p){
t[p].sum = t[p<<1].sum + t[p<<1|1].sum;
};
auto build = [&](auto& build, int p, int l, int r) -> void {
t[p].l = l;
t[p].r = r;
if (l == r) {
t[p].sum = 1;
return;
}
int mid = (l + r) >> 1;
build(build, p << 1, l, mid); build(build, p << 1 | 1, mid + 1, r);
pushup(p);
};
auto kth = [&](auto &kth,int p,int l,int r,int k)->int{
if(t[p].l == t[p].r){
t[p].sum = 0;//找到第k小时,顺便将他删除
return t[p].l;
}
int mid = t[p].l + t[p].r >> 1;
int res = 0;
if(k <= t[p<<1].sum) res = kth(kth,p<<1,l,mid,k);
else res = kth(kth,p<<1|1,mid+1,r,k-t[p<<1].sum);
pushup(p);
return res;
};
build(build,1,1,n);
for(int i = 1;i <= n;i++){
a[i] = kth(kth,1,1,n,s[i]+1);
}
//delete[] t;
return a;
}
long long s_to_rk(int n,vector<long long>&s){
vector<long long>fact(n+1);
fact[0] = 1;
for(int i = 1;i <= n;i++){
fact[i] = fact[i-1]*i%mod;
}
long long rk = 0;
for(int i = 1;i <= n;i++){
rk = (rk + s[i]*fact[n-i])%mod;
}
return rk;
}
void s_add_rk(int n,vector<long long>&s,long long rk){
s[n] += rk;
for(int i = n;i >= 1;i--){
s[i-1] += s[i] / (n-i+1);
s[i] %= (n-i+1);
}
}
vector<long long> rk_to_s(int n,long long rk){
vector<long long>s(n+1);
for(int i = 1;i <= n;i++){
s[n-i+1] = rk % i;
rk /= i;
}
return s;
};
一些例题:a[ ]->s[ ]->rk:P5367 【模板】康托展开 - 洛谷 (luogu.com.cn) s[ ]->a[ ]:UVA11525 Permutation - 洛谷 (luogu.com.cn) a[ ]->s[ ],s[ ]+rk->a[ ] U72177 火星人plus - 洛谷 (luogu.com.cn)
线性代数
矩阵
矩阵乘法
矩阵相乘只有在第一个矩阵的列数和第二个矩阵的行数相同时才有意义。
设 $A$ 为 $P \times M$ 的矩阵,$B$ 为 $M \times Q$ 的矩阵,设矩阵 $C$ 为矩阵 $A$ 与 $B$ 的乘积,
其中矩阵 $C$ 中的第 $i$ 行第 $j$ 列元素可以表示为矩阵A的第$i$行与矩阵B的第$j$列分别相乘再求和:
\(C_{i,j} = \sum_{k=1}^MA_{i,k}B_{k,j}\) 矩阵乘法满足结合律,不满足一般的交换律。利用结合律,矩阵乘法可以用快速幂的思想优化。
矩阵快速幂
时间复杂度 $O(N^3logK)$
P3390 【模板】矩阵快速幂 - 洛谷 (luogu.com.cn)
给点一个n*n的矩阵A,求$A^k$,对1e9+7取模。
#include <iostream>
using namespace std;
const int N = 105,mod = 1e9+7;
long long n,k;
struct mat{
long long a[N][N];
};
mat operator * (const mat &a,const mat &b){
mat ans = {};
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
for(int k = 1;k <= n;k++){
ans.a[i][j] = (ans.a[i][j] + a.a[i][k] * b.a[k][j]) % mod;
}
}
}
return ans;
}
mat qmi(mat a,long long b){
mat ans = {};//单位矩阵
for(int i = 1;i <= n;i++){
ans.a[i][i] = 1;
}
while(b){
if(b & 1) ans = ans * a;
b >>= 1;
a = a * a;
}
return ans;
}
void qmi(mat &ans,mat a, long long b){
while(b){
if(b & 1)ans = ans * a;
b >>= 1;
a = a * a;
}
}
int main(){
cin >> n >> k;
mat base = {};
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
cin >> base.a[i][j];
}
}
mat ans = qmi(base,k);
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
cout << ans.a[i][j] << ' ';
}cout << '\n';
}
}
P10502 Matrix Power Series - 洛谷 (luogu.com.cn)
给定一个 $n\times n$ 的矩阵 $A$ 和一个正整数 $k$ ,求 $S = A + A^1 +A^2 +\dots +A^k$。
$S(k) = \begin{cases}
S(k-1)+A^k \qquad \qquad \quad \ k为奇数\
S(k/2) + S(k/2)*A^\frac{k}{2} \qquad k为偶数
\end{cases}$
#include <iostream>
#include <vector>
int mod;
struct Mat{
int n;
std::vector<std::vector<int> >a;
Mat(){}
Mat(int _n) {
n = _n;
a = std::vector<std::vector<int> >(n,std::vector<int> (n));
}
Mat operator * (const Mat &m2){
Mat ans(n);
for(int i = 0;i < n;i++){
for(int j = 0;j < n;j++){
for(int k = 0;k < n;k++){
ans.a[i][j] = (ans.a[i][j] + a[i][k] * m2.a[k][j]) % mod;
}
}
}
return ans;
}
Mat operator + (const Mat &m2){
Mat ans = *this;
for(int i = 0;i < n;i++){
for(int j = 0;j < n;j++){
ans.a[i][j] = (ans.a[i][j] + m2.a[i][j]) % mod;
}
}
return ans;
}
Mat qmi(long long b){
Mat base = *this;
Mat ans(n);
for(int i = 0;i < n;i++) ans.a[i][i] = 1;
while(b){
if(b & 1) ans = ans * base;
b >>= 1;
base = base * base;
}
return ans;
}
};
Mat A;
Mat f(int k){
if(k == 1) return A;
if(k&1) {
return f(k-1) + A.qmi(k);
}
else{
Mat B = f(k/2);
return B + B * A.qmi(k/2);
}
}
int main(){
int n,k; std::cin >> n >> k >> mod;
A = Mat(n);
for(int i = 0;i < n;i++){
for(int j = 0;j < n;j++){
std::cin >> A.a[i][j];
A.a[i][j] %= mod;
}
}
A = f(k);
for(int i = 0;i < n;i++){
for(int j = 0;j < n;j++){
std::cout << A.a[i][j] << ' ';
}
std::cout << '\n';
}
}
矩阵封装
默认0_idx、N*N的矩阵大小,根据实际需要修改代码。
| Mat |
||
|---|---|---|
A +* B |
矩阵加/乘法 | |
auto B = A.qmi(k) |
矩阵快速幂 | |
A.norm() |
化为单位矩阵 | |
auto B = inv(A) |
求逆矩阵 | 诺不存在则B[0][0] == -1 |
det(A) |
行列式求值 | |
add(x,y,w) |
矩阵树连边 | 注意0_idx |
const int mod = 1e9+7;//
namespace MAT{
template<typename T>
struct Mat{//0_idx
int n;
std::vector<std::vector<T>>a;
Mat(int _n,T val = 0) {
n = _n;
a = std::vector<std::vector<T>>(n,std::vector<T>(n,val));
}
Mat operator * (const Mat &m2){
Mat ans(n,0);
for(int i = 0;i < n;i++){
for(int j = 0;j < n;j++){
for(int k = 0;k < n;k++){
ans.a[i][j] = (ans.a[i][j] + a[i][k] * m2.a[k][j]) % mod;
}
}
}
return ans;
}
Mat operator + (const Mat &m2){
auto ans = *this;
for(int i = 0;i < n;i++){
for(int j = 0;j < n;j++){
ans.a[i][j] = (ans.a[i][j] + m2.a[i][j]) % mod;
}
}
return ans;
}
void operator *= (const Mat &m2) {*this = *this * m2;}
void operator += (const Mat &m2) {*this = *this + m2;}
void norm(){
for(int i = 0;i < n;i++) a[i][i] = 1;
}
void add(int x,int y,int w){//Mat_tree:add_edge(x,y,w);
if(x == y) return;
a[y][y] = (a[y][y] + w) % mod;
a[x][y] = (a[x][y] - w) % mod;
}
Mat qmi(long long b){
auto base = *this;
Mat ans(n);
ans.norm();
while(b) {
if(b&1) ans = ans * base;
b >>= 1;
base = base * base;
}
return ans;
}
};
long long qmi(long long a,long long b,long long p){
long long ans = 1;
while(b){
if(b&1) ans = ans*a%p;
b>>=1;
a = a*a%p;
}
return ans;
}
template<typename T>
Mat<T> inv(Mat<T> mt){
int n = mt.n;
std::vector<std::vector<long long>> aug(n, std::vector<long long>(2 * n, 0));
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) { aug[i][j] = mt.a[i][j]; }
aug[i][i + n] = 1;
}
for (int i = 0; i < n; i++) {
int pivot = -1;
for (int r = i; r < n; r++) {
if (aug[r][i] != 0) {
pivot = r;
break;
}
}
if (pivot == -1) { mt.a[0][0] = -1;return mt; }//No_inv
if (i != pivot) { std::swap(aug[i], aug[pivot]); }
long long inv_val = qmi(aug[i][i], mod - 2, mod);
for (int j = 0; j < 2 * n; j++) {
aug[i][j] = aug[i][j] * inv_val % mod;
}
for (int j = 0; j < n; j++) {
if (j == i) continue;
long long mul = aug[j][i];
for (int k = 0; k < 2 * n; k++) {
aug[j][k] = (aug[j][k] - mul * aug[i][k] % mod + mod) % mod;
}
}
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
mt.a[i][j] = aug[i][j + n];
}
}
return mt;
}
template<typename T>
T det(Mat<T> mt){
int n = mt.n;
long long ans = 1;
for(int i = 0;i < n;i++){//if(mat_tree) please i begin with 1
for(int j = i+1;j < n;j++){
while(mt.a[j][i]){
long long t = mt.a[i][i]/mt.a[j][i];
for(int k = i;k < n;k++) {
mt.a[i][k] = (mt.a[i][k] - mt.a[j][k] * t % mod + mod) % mod;
//mt.a[i][k] -= t * mt.a[j][k];
}
std::swap(mt.a[i],mt.a[j]);
ans = -ans;
}
}
if(!mt.a[i][i]) return 0;
ans = (ans * mt.a[i][i] % mod + mod) % mod;
//ans *= mt.a[i][i];
}
return std::abs(ans);
}
}
using MAT::Mat;
行列式
定义 \(\operatorname A=\left|\begin{array}{cccc} a_{11} & a_{12} & \cdots & a_{1 n} \\ a_{21} & a_{22} & \cdots & a_{2 n} \\ \vdots & \vdots & & \vdots \\ a_{n 1} & a_{n 2} & \cdots & a_{n n} \end{array}\right|\) 对于一个矩阵$A[1\dots n][1\dots n]$,其行列式为$det(A) = \sum_{P}{(-1)^{\mu(P)}\prod_{i=1}^{n}A[i][p_i]}$。 (枚举排列$P[1\dots n]$,其中$\mu(P)$为排列$P$的逆序对数,$det(A)$又称作$|A|$)
一些性质
-
单位矩阵的行列式为1。
-
交换两行(列),行列式的值变号。
-
诺某一行(列)乘以 $t$,行列式的值也就乘以 $t$ 。
-
若行列式某一行(列)的元素是两数之和,则行列式可拆成两个行列式的和。$\left| \begin{array}{cc} a+a^{\prime} & b+b^{\prime}
c & d \end{array}\right|=\left|\begin{array}{cc} a & b
c & d \end{array}\right|+\left|\begin{array}{cc} a^{\prime} & b^{\prime}
c & d \end{array}\right|$ -
行列式某一行(列)元素加上另一行(列)对应元素的k倍,行列式的值不变。
-
诺有两行(列)一样,则行列式的值为0
行列式求值
高斯消元实现,时间复杂度$O(N^3)$
//模版 https://www.luogu.com.cn/problem/P7112
#include <bits/stdc++.h>
using namespace std;
int mod;
struct Mat{//1_idx
std::vector<std::vector<long long>>a;
Mat(int n){
a = std::vector<std::vector<long long>>(n+1,std::vector<long long>(n+1));
}
long long det(int n){
long long ans = 1;
for(int i = 1;i <= n;i++){
for(int j = i+1;j <= n;j++){
while(a[j][i]){
long long t = a[i][i]/a[j][i];
for(int k = i;k <= n;k++) {
a[i][k] = (a[i][k] - a[j][k] * t % mod + mod) % mod;
}
std::swap(a[i],a[j]);
ans = -ans;
}
}
if(!a[i][i]) return 0;
ans = (ans * a[i][i] % mod + mod) % mod;
}
return std::abs(ans);
}
};
int main(){
int n; cin >> n >> mod;
Mat mat(n);
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
cin >> mat.a[i][j];
}
}
cout << mat.det(n);
}
线性基
常用来解决子集异或一类题目
从a[ ]中选任意个整数(可能包含重复元素),使得选出的整数异或和最大,求这个异或和最大值可能是多少
//https://www.luogu.com.cn/problem/P3812
//时间复杂度O(NlogV)
#include <iostream>
#include <algorithm>
using namespace std;
using ll = long long;
const int N = 100005;
ll n,a[N],p[N],cnt;
void add(ll x){
for(int i = 1;i <= cnt;i++){
x = min(x,x^p[i]);
}
if(x){
p[++cnt] = x;
sort(p+1,p+cnt+1,greater<ll>());
}
}
int main(){
cin >> n;
for(int i = 1;i <= n;i++){
cin >> a[i];
add(a[i]);
}
ll x = 0;;
for(int i = 1;i <= cnt;i++){
x = max(x,x^p[i]);
}
cout << x;
}
应用:
- 快速查询一个数是否可以被一堆数异或出来
- 快速查询一堆数可以异或出来的最大/最小值
- 快速查询一堆数可以异或出来的第k大值
概率论
一般情况下,解决概率问题需要顺序循环,而解决期望问题使用逆序循环
期望
若随机变量 $X, Y$ 的期望存在,则
- 对任意实数 $a, b$,有 $E(aX + b) = a \cdot EX + b$。
- $E(X + Y) = EX + EY$。
通常把终止状态作为初值,把起始状态作为目标,倒着进行计算。因为在很多情况下,起始状态是唯一的,而终止状态很多。根据数学期望的定义,诺我们正着计算,则还需求出从起始状态到每个终止状态的概率,与F值相乘求和才能得到答案,增加了难度,也很容易出错
//绿豆蛙的归宿https://www.luogu.com.cn/problem/P4316
//F[N]=0,我们的目标是求出F[1],故我们从终点出发,在反图执行拓扑排序,在拓扑排序的过程中顺便计算F[x]即可
#include <bits/stdc++.h>
using namespace std;
const int N = 200005;
int n,m;
int h[N],e[N],ne[N],w[N],idx;
int in[N],out[N];
double ans[N];
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void uuz(int beg){
ans[beg] = 0;
queue<int>q;
q.push(beg);
while(q.size()){
auto t = q.front();q.pop();
for(int i = h[t];~i;i = ne[i]){
int k = e[i];
ans[k] += (ans[t] + w[i])/in[k];
out[k]--;
if(out[k] == 0) q.push(k);
}
}
}
void sol(){
memset(h,-1,sizeof h);
cin >> n >> m;
for(int i = 1;i <= m;i++){
int a,b,c;cin >> a >> b >> c;
add(b,a,c);//反向建边
in[a]++;out[a]++;
}
uuz(n);
cout << fixed << setprecision(2) << ans[1];
}
int main() {
while(T--){ sol(); }
}
方差
设随机变量 $X$ 的期望 $EX$ 存在,且期望 $E(X - EX)^2$ 也存在,则称上式的值为随机变量 $X$ 的 方差,记作 $DX$ 或 $Var(x)$,各个数据与均值的差的平方和。方差的算术平方根称为 标准差,记作 $\sigma(X) = \sqrt{DX}$。
方差的性质
若随机变量 $X$ 的方差存在,则
- 对任意常数 $a, b$ 都有 $D(aX + b) = a^2 \cdot DX$
- $DX = E(X^2) - (EX)^2$
数值算法
数值积分
自适应辛普森算法
求定积分$\int_{l}^{r}f(x)dx$ ,即为f(x)在区间[l,r]上与x轴围成的面积 (其中x轴上方为正值,下方为负值)
double f(double x){//f(x)
}
double simpson(double l, double r) {
double mid = (l + r) / 2;
return (r - l) * (f(l) + 4 * f(mid) + f(r)) / 6; // 辛普森公式
}
double asr(double l, double r, double eps, double ans, int step) {
double mid = (l + r) / 2;
double fl = simpson(l, mid), fr = simpson(mid, r);
if (abs(fl + fr - ans) <= 15 * eps && step < 0)
return fl + fr + (fl + fr - ans) / 15; // 足够相似的话就直接返回
return asr(l, mid, eps / 2, fl, step - 1) + asr(mid, r, eps / 2, fr, step - 1); // 否则分割成两段递归求解
}
double calc(double l, double r, double eps) {// calc(l,r,eps)
return asr(l, r, eps, simpson(l, r), 12);
}
P4525 【模板】自适应辛普森法 1 - 洛谷 (luogu.com.cn)
试计算积分$\int_{l}^{r}\frac{cx+d}{ax+b}dx$结果保留至小数点后6位。
#include <bits/stdc++.h>
using namespace std;
double a,b,c,d,l,r;
double f(double x){
return (c*x+d)/(a*x+b);
}
double simpson(double l, double r) {
double mid = (l + r) / 2;
return (r - l) * (f(l) + 4 * f(mid) + f(r)) / 6;
}
double asr(double l, double r, double eps, double ans, int step) {
double mid = (l + r) / 2;
double fl = simpson(l, mid), fr = simpson(mid, r);
if (abs(fl + fr - ans) <= 15 * eps && step < 0)
return fl + fr + (fl + fr - ans) / 15;
return asr(l, mid, eps / 2, fl, step - 1) + asr(mid, r, eps / 2, fr, step - 1);
}
double calc(double l, double r, double eps) {
return asr(l, r, eps, simpson(l, r), 12);
}
int main() {
cin >> a >> b >> c >> d >> l >> r;
cout << fixed << setprecision(6) << calc(l,r,1e-9);
}
高斯消元
高斯消元解线性方程组 \(\begin{cases} a_{1,1}x_1 + a_{1,2}x_2 + \cdots + a_{1,n}x_n &= b_1\\ a_{2,1}x_1 + a_{2,2}x_2 + \cdots + a_{2,n}x_n &= b_2\\ \cdots &\cdots \\ a_{m,1}x_1 + a_{m,2}x_2 + \cdots + a_{m,n}x_n &= b_m \end{cases}\)
运用初等行变换,把增广矩阵,变为阶梯型矩阵。最后再把阶梯型矩阵从下到上回代到第一层即可得到方程的解。
时间复杂度$O(N^3)$
枚举每一列c
找到当前列绝对值最大的一行,放到上面 将该行该列第一个数变成1 再将下面其他所有行该列变成0
//https://www.acwing.com/problem/content/885/
#include <bits/stdc++.h>
using namespace std;
const double eps = 1e-9;
int gauss(vector<vector<double>>&a) {//a[m+1][n+2]; 1_idx
int m = a.size()-1,n = a[0].size()-2;
int c,r;//col列 row行
for (c = 1,r = 1; c <= n; c++) {
int tr = r;//找到当前这一列,绝对值最大的所在行
for (int i = r+1; i <= m; i++) {
if (fabs(a[i][c]) > fabs(a[tr][c])) { tr = i; }
}
if (fabs(a[tr][c]) < eps) continue; //诺都是0直接跳过;
swap(a[r],a[tr]);//把当前这一行换到第最上面(第r行)
for(int j = n+1;j >= c;j--) {a[r][j] /= a[r][c];}//把当前该行该列第一个数变成1(从后往前系数倒着算)
for (int i = r+1; i <= m; i++) {//把当前列下面所有系数变为0
if(fabs(a[i][c]) > eps){//已经是0则可以跳过
for(int j = n+1;j >= c;j--){//每一行从后往前,系数-=行首系数*第c行同一列系数
a[i][j] -= a[i][c]*a[r][j];
}
}
}
r++;
}
if (r < n+1) {//r<n+1说明已经解出来的x不足以解出原方程
for (int i = r; i <= m; i++) {
if (fabs(a[i][n+1]) > eps) {//左边=0,右边b!=0,无解
return 0;
}
}
return 2;//0=0说明有无穷解
}
for(int i = n;i >= 1;i--){//从下往上回代,解出原方程
for(int j = i+1;j <= n;j++){
a[i][n+1] -= a[j][n+1]*a[i][j];
}
}
return 1;
}
int main() {
int n, m; cin >> n;m = n;
vector<vector<double>> a(m+1, vector<double>(n+2));
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n+1; j++) {
cin >> a[i][j];
}
}
int t = gauss(a);
if (t == 0) cout << "No solution";
if (t == 2) cout << "Infinite group solutions";
if (t == 1) {
for (int i = 1; i <= n; i++) {
printf("%.2lf\n", a[i][n+1]);
}
}
}
高斯消元解异或方程组
\(\begin{cases}
a_{1,1}x_1 \oplus a_{1,2}x_2 \oplus \cdots \oplus a_{1,n}x_n &= b_1\\
a_{2,1}x_1 \oplus a_{2,2}x_2 \oplus \cdots \oplus a_{2,n}x_n &= b_2\\
\cdots &\cdots \\
a_{m,1}x_1 \oplus a_{m,2}x_2 \oplus \cdots \oplus a_{m,n}x_n &= b_1
\end{cases}\)
在消元的时候使用「异或消元」而非「加减消元」,且不需要进行乘除改变系数(因为系数均为0和 1)
异或可以看做不进位的加法
//https://www.acwing.com/problem/content/description/886/
#include <iostream>
#include <vector>
using namespace std;
int gauss_xor(vector<vector<int>>&a){//a[m+1][n+2]; 1_idx
int m = a.size()-1,n = a[0].size()-2;
int c,r;
for(c = 1,r = 1;c <= n;c++){
int tr = r;
for(int i = r;i <= m;i++){
if(a[i][c]) {tr = i;break;}
}
if(a[tr][c] == 0) continue;
swap(a[r],a[tr]);
for(int i = r+1;i <= m;i++){
if(a[i][c]){
for(int j = n+1;j >= c;j--){
a[i][j] ^= a[r][j];
}
}
}
r++;
}
if(r < n+1){
for(int i = r;i <= m;i++){
if(a[i][n+1]) return 0;
}
return 2;
}
for(int i = n;i >= 1;i--){
for(int j = i+1;j <= n;j++){
if(a[i][j]) a[i][n+1] ^= a[j][n+1];
}
}
return 1;
}
int main(){
int n,m;cin >> n;m = n;
vector<vector<int>>a(m+1,vector<int>(n+2));
for(int i = 1;i <= m;i++){
for(int j = 1;j <= n+1;j++){
cin >> a[i][j];
}
}
int t = gauss_xor(a);
if(t == 1){
for(int i = 1;i <= n;i++){
cout << a[i][n+1] << '\n';
}
}
if(t == 2) cout << "Multiple sets of solutions";
if(t == 0) cout << "No solution";
}
插值
插值是一种通过已知的、离散的数据点推算一定范围内的新数据点的方法。插值法常用于函数拟合中。
拉格朗日插值 \(f(x)=\sum_{i=1}^n(y_i\cdot\prod_{j\neq i}\dfrac{x-x_j}{x_i-x_j})\)
P4781 【模板】拉格朗日插值 - 洛谷 (luogu.com.cn)
对于 $n$ 个点 $(x_i,y_i)$,如果满足 $\forall i\neq j, x_i\neq x_j$,那么经过这 $n$ 个点可以唯一地确定一个 $n-1$ 次多项式 $y = f(x)$。
现在,给定这样 $n$ 个点,请你确定这个 $n-1$ 次多项式,并求出 $f(k) \bmod 998244353$ 的值。
//O(N^2)实现
#include <iostream>
#include <vector>
using namespace std;
const int mod = 998244353;
long long qmi(long long a,long long b,long long p){
long long ans = 1;
while(b){
if(b&1) ans = ans*a%p;
b>>=1;
a = a*a%p;
}
return ans%p;
}
long long lagrange_interpolation(vector<pair<long long,long long>> &v,int k){//1_idx
long long ans = 0;
for(int i = 1;i < v.size();i++){
auto &[x1,y1] = v[i];
long long s1 = y1,s2 = 1;
for(int j = 1;j < v.size();j++){
if(i == j) continue;
auto &[x2,y2] = v[j];
s1 = s1 * (k-x2)%mod;
s2 = s2 * (x1-x2)%mod;
}
ans += s1 * qmi(s2,mod-2,mod) % mod;
ans = (ans + mod) % mod;
}
return ans;
}
int main(){
int n,k; cin >> n >> k;
vector<pair<long long,long long>>v(n+1);
for(int i = 1;i <= n;i++){
cin >> v[i].first >> v[i].second;
}
cout << lagrange_interpolation(v,k) << '\n';
}
博弈论
Nim游戏
n堆物品,每堆有$a_i$个,两个玩家轮流取走任意一堆的任意一个物品(不能不取),取走最后一个物品的人获胜
博弈图和状态
如果将每个状态视为一个节点,再从每个状态向它的后继状态连边,我们就可以得到一个博弈状态图。 例如,如果节点 $(i, j, k)$ 表示局面为 $i, j, k$ 时的状态,则我们可以画出下面的博弈图
定义 必胜状态 为 先手必胜的状态,必败状态 为 先手必败的状态。 通过推理,我们可以得出下面三条定理:
- 定理 1:没有后继状态的状态是必败状态。
- 定理 2:一个状态是必胜状态当且仅当存在至少一个必败状态为它的后继状态。
- 定理 3:一个状态是必败状态当且仅当它的所有后继状态均为必胜状态。
对于定理 1,如果游戏进行不下去了,那么这个玩家就输掉了游戏。
对于定理 2,如果该状态至少有一个后继状态为必败状态,那么玩家可以通过操作到该必败状态;此时对手的状态为必败状态——对手必定是失败的,而相反地,自己就获得了胜利。
对于定理 3,如果不存在一个后继状态为必败状态,那么无论如何,玩家只能操作到必胜状态;此时对手的状态为必胜状态——对手必定是胜利的,自己就输掉了游戏。
如果博弈图是一个有向无环图,则通过这三个定理,我们可以在绘出博弈图的情况下用O(N+M)的时间(其中N为状态种数,M为边数)得出每个状态是必胜状态还是必败状态。
Nim和
通过绘画博弈图,我们可以在 $O(\prod_{i=1}^n a_i)$ 的时间里求出该局面是否先手必赢。 但是,这样的时间复杂度实在太高。有没有什么巧妙而快速的方法呢? 定义 Nim 和 $=a_1 \oplus a_2 \oplus \ldots \oplus a_n$。 当且仅当 Nim和为 $0$ 时,该状态为必败状态;否则该状态为必胜状态。
//https://www.acwing.com/problem/content/893/
#include <iostream>
using namespace std;
int main(){
int ans = 0;
int n;cin >> n;
for(int i = 1;i <= n;i++){
int x;cin >> x;
ans^=x;
}
if(ans) cout << "Yes";
else cout << "No";
}
SG函数
有向图游戏是一个经典的博弈游戏——实际上,大部分的公平组合游戏都可以转换为有向图游戏。 在一个有向无环图中,只有一个起点,上面有一个棋子,两个玩家轮流沿着有向边推动棋子,不能走的玩家判负。 定义 $\operatorname{mex}$ 函数的值为不属于集合 $S$ 中的最小非负整数,即: \(\operatorname{mex}(S)=\min\{x\} \quad (x \notin S, x \in N)\)
例如 $\operatorname{mex}({0, 2, 4})=1$,$\operatorname{mex}({1, 2})=0$。
对于状态 $x$ 和它的所有 $k$ 个后继状态 $y_1, y_2, \ldots, y_k$,定义 $\operatorname{SG}$ 函数:
\[\operatorname{SG}(x)=\operatorname{mex}\{\operatorname{SG}(y_1), \operatorname{SG}(y_2), \ldots, \operatorname{SG}(y_k)\}\]而对于由 $n$ 个有向图游戏组成的组合游戏,设它们的起点分别为 $s_1, s_2, \ldots, s_n$,则有定理:当且仅当 $\operatorname{SG}(s_1) \oplus \operatorname{SG}(s_2) \oplus \ldots \oplus \operatorname{SG}(s_n) \neq 0$ 时,这个游戏是先手必胜的。同时,这是这一个组合游戏的游戏状态 $x$ 的 SG 值。
这一定理被称作 Sprague–Grundy 定理(Sprague–Grundy Theorem), 简称 SG 定理,适用于任何公平的两人游戏, 它常被用于决定游戏的输赢结果。
计算给定状态的 Grundy 值的步骤一般包括:
-
获取从此状态所有可能的转换;
-
每个转换都可以导致 一系列独立的博弈(退化情况下只有一个)。计算每个独立博弈的 Grundy 值并对它们进行 异或求和。
-
在为每个转换计算了 Grundy 值之后,状态的值是这些数字的 $\operatorname{mex}$。
-
如果该值为零,则当前状态为输,否则为赢。
将 Nim 游戏转换为有向图游戏
我们可以将一个有 $x$ 个物品的堆视为节点 $x$,则当且仅当 $y<x$ 时,节点 $x$ 可以到达 $y$。 那么,由 $n$ 个堆组成的 Nim 游戏,就可以视为 $n$ 个有向图游戏了。 根据上面的推论,可以得出 $\operatorname{SG}(x)=x$。再根据 SG 定理,就可以得出 Nim 和的结论了。
给定n堆石子和一个由m个不同正整数构成的数字集合S。两位玩家轮流操作,每次可以从任意一堆石子中拿取石子,每次拿取的石子数量必须包含于集合S,判断先手是否必胜?
#include <iostream>
#include <cstring>
#include <algorithm>
#include <set>
using namespace std;
const int N = 105,M = 10004;
int n,m;
int f[M],s[N];//f储存所有情况的sg值,s存可供选择的集合
int sg(int x){
if(f[x] != -1) return f[x];//如果当前数的sg已经确定,直接返回即可
set<int>st;
for(int i = 0;i < m;i++){
if(x >= s[i]) st.insert(sg(x-s[i]));//set存当前能到达状态的所有sg值
}
for(int i = 0;;i++){
if(st.find(i) == st.end()) {
return f[x] = i;//f[x] = 不属于集合set的最小非负整数
}
}
}
int main(){
memset(f,-1,sizeof f);
cin >> m;
for(int i = 0;i < m;i++)cin >> s[i];
cin >> n;
int ans = 0;
for(int i = 0;i < n;i++){
int x;cin >> x;
ans^=sg(x);
}
if(ans) cout << "Yes";
else cout << "No";
}
VS AtCoder(★6) - AtCoder typical90_ae - Virtual Judge (vjudge.net)
给定n堆石子,每堆石子由w[i]颗白石和b[i]颗蓝石。两人轮流进行以下操作之一:
- 选择一堆白石w >= 1的石子,向选择的石子中加入w颗蓝石,然后移除1颗白石。
- 选择一堆蓝石b >= 2的石子,移除k颗蓝石子,其中$1 \le k \le \lfloor \frac{b}{2} \rfloor$。
最后无法操作的输掉比赛。
#include <iostream>
#include <set>
#include <cstring>
using namespace std;
const int N = 100005;
int w[N],b[N];
int f[55][1505];
int sg(int x,int y){
if(f[x][y] != -1) return f[x][y];
set<int>se;
if(x >= 1) se.insert(sg(x-1,y+x));
if(y >= 2) {
for(int i = 1;i*2 <= y;i++){
se.insert(sg(x,y-i));
}
}
for(int i = 0;;i++){
if(se.find(i) == se.end()){
return f[x][y] = i;
}
}
}
int main(){
memset(f,-1,sizeof f);
int n;cin >> n;
for(int i = 1;i <= n;i++) cin >> w[i];
for(int i = 1;i <= n;i++) cin >> b[i];
int ans = 0;
for(int i = 1;i <= n;i++){
ans ^= sg(w[i],b[i]);
}
if(ans) cout << "First";
else cout << "Second";
}
计算几何
距离
| 距离 | 二维计算 | 多维计算 | ||||||
|---|---|---|---|---|---|---|---|---|
| 欧氏距离 | $ | AB | = \sqrt{(x_2-x_1)^2 + (y_2-y_1)^2}$ | 三维:$ | AB | = \sqrt{(x_2-x_1)^2 + (y_2-y_1)^2 + (z_2-z_1)^2}$ | ||
| 曼哈顿距离 | $d(A,B) = | x_1-x_2 | + | y_1-y_2 | $ | n维:$d(A,B) = \sum_{i=1}^{n} | x_i-y_i | $ |
| 切比雪夫距离 | $d(A,B) = max( | x_1-x_2 | , | y_1-y_2 | )$ | n维:$d(A,B) = max{ | x_i-y_i | }(i\in [1,n])$ |
曼哈顿距离与切比雪夫距离转换
曼哈顿->切比雪夫 : $(x,y) \Rightarrow (x+y,x-y)$
切比雪夫->曼哈顿 : $(x,y)\Rightarrow (\frac{x+y}{2},\frac{x-y}{2})$,一般为了避免小数,我们可以横纵坐标同时乘2(即转换时不除以2),最后答案除以2。
曼哈顿坐标系是通过切比雪夫坐标系旋转 $45^\circ$ 后,再缩小到原来的一半得到的。碰到求切比雪夫距离或曼哈顿距离的题目时,我们往往可以相互转化来求解。两种距离在不同的题目中有不同的优缺点,应该灵活运用。
[P5098 USACO04OPEN] Cave Cows 3 - 洛谷 (luogu.com.cn)
求平面内任意一点到其它点的最大距离
直接曼哈顿转切比雪夫坐标,答案就是max(当前的点的 x 和 x的极值做差的绝对值 , 当前的点的 y 和 y 的极值做差的绝对值的)
#include <iostream>
#include <algorithm>
#include <vector>
#include <tuple>
using namespace std;
const int N = 100005;
int n;
vector<long long>dx,dy;
struct node{
int x,y;
}p[N];
int main(){
cin >> n;
for(int i = 1;i <= n;i++){
auto &[x,y] = p[i];cin >> x >> y;
tie(x,y) = pair{x+y,x-y};
dx.emplace_back(x);//也可以用4个变量分别维护x和y的极大值和极小值,O(N)
dy.emplace_back(y);
}
sort(dx.begin(),dx.end());
sort(dy.begin(),dy.end());
long long ans = 0;
for(int i = 1;i <= n;i++){
auto [x,y] = p[i];
long long nx = max(abs(dx.back()-x),abs(dx[0]-x));
long long ny = max(abs(dy.back()-y),abs(dy[0]-y));
long long now = max(nx,ny);
ans = max(ans,now);
}
cout << ans;
}
扫描线
扫描线的思路就是数据结构维护一维,暴力模拟另一维。
面积并

P5490 【模板】扫描线 & 矩形面积并 - 洛谷 (luogu.com.cn)
给每一个矩形的上下边进行标记,下面的边标记为 1,上面的边标记为 -1。每遇到一个水平边时,让这条边(在横轴投影区间)的权值加上这条边的标记。当前的宽度就是整个数轴上权值大于 0 的区间总长度,总面积即为$\sum {(线段长度*扫过的高度)}$
线段树维护的是区间段(左闭右开)而不是离散点
点: 1 3 5 7
区间: [1,3) [3,5) [5,7)
索引: 1 2 3
modify当处理矩形边[1,5]时,覆盖的区间段索引 = [hs[1],hs[5]-1] = [1,2]
pushup计算节点p对应区间段时,节点p的左右端点[1,2],对应区间[v[1],v[2+1]) = [1,5)
#include <iostream>
#include <algorithm>
#include <vector>
const int N = 200005;
int n;
std::vector<int>hs(1,-2e9);
struct line{//从下往上扫描
int l,r,h;//记录每条线其左右区间[l,r]和所在高度h
int w;//w=1为下边,w=-1为上边
bool operator < (const line &e2)const{
if(h == e2.h) return w > e2.w;
return h < e2.h;
}
};
struct ST{
int l,r;
int cnt,len;//cnt:被覆盖次数,len:覆盖长度
}t[N<<2];
void build(int p,int l,int r){
t[p] = {l,r};
if(l == r) {
return;
}
int mid = l + r >> 1;
build(p<<1,l,mid);build(p<<1|1,mid+1,r);
}
void pushup(int p){
if(t[p].cnt){//完全覆盖,取整个区间长度
t[p].len = hs[t[p].r+1] - hs[t[p].l];
}
else{
if(t[p].l == t[p].r) t[p].len = 0; //叶子节点且未覆盖
else t[p].len = t[p<<1].len + t[p<<1|1].len; //合并子节点
}
}
void modify(int p,int l,int r,int x){
if(l <= t[p].l && r >= t[p].r){
t[p].cnt += x;
pushup(p);//更新当前节点,标记永久化(利用覆盖计数的特性)
return;
}//不需要pushdown下传标记
int mid = t[p].l + t[p].r >> 1;
if(l <= mid) modify(p<<1,l,r,x);
if(r > mid) modify(p<<1|1,l,r,x);
pushup(p);//更新当前节点
}
int main(){
std::cin >> n;
std::vector<line>e(1);
for(int i = 1;i <= n;i++){//读入坐标,并转化为线
int x1,y1,x2,y2;std::cin >> x1 >> y1 >> x2 >> y2;
e.push_back({x1,x2,y1,1});
e.push_back({x1,x2,y2,-1});
hs.push_back(x1);
hs.push_back(x2);
}
//离散化
std::sort(e.begin()+1,e.end());
std::sort(hs.begin()+1,hs.end());
hs.erase(std::unique(hs.begin()+1,hs.end()),hs.end());
int m = hs.size()-1;
for(int i = 1;i <= n << 1;i++){
e[i].l = std::lower_bound(hs.begin()+1,hs.end(),e[i].l) - hs.begin();
e[i].r = std::lower_bound(hs.begin()+1,hs.end(),e[i].r) - hs.begin();
}
build(1,1,m-1);//建树范围为区间段个数,m个点对应m-1个区间(开m个也没关系)
long long ans = 0;
for(int i = 1;i <= n << 1;i++){//最后一条边不用累加上答案,但仍需要modify处理,否则多测会导致线段树数据残留
auto &[l,r,h,w] = e[i];
modify(1,l,r-1,w);//左闭右开区间
if(i < n << 1) ans += (long long)t[1].len * (e[i+1].h - e[i].h);//面积+=当前全局覆盖长度*上下高度差
}
std::cout << ans;
}
周长并
[P1856 IOI 1998][USACO5.5] 矩形周长 Picture - 洛谷 (luogu.com.cn)


横边的总长度 = $\sum |当前截得的总长度 - 上次截得的总长度|$ 竖边的总长度 = $\sum (2\times 当前线段条数\times 扫过的高度)$
#include <iostream>
#include <vector>
#include <algorithm>
const int N = 10004;
int n;
std::vector<int>hs(1,-2e9);
struct line{
int l,r,h,w;
bool operator < (const line &e2) const{
if(h == e2.h) return w > e2.w;//高度相同先扫描底边,否则会多算这条边
return h < e2.h;
}
};
struct ST{
int l,r;
int len,cnt;
int c;//c:区间线段条数
bool lc,rc;//lc、rc:左右端点是否被覆盖,辅助计算c
}t[N<<2];
void build(int p,int l,int r){
t[p] = {l,r};
if(l == r){
return;
}
int mid = l + r >> 1;
build(p<<1,l,mid);build(p<<1|1,mid+1,r);
}
void pushup(int p){
if(t[p].cnt){//当前区间完全被覆盖
t[p].len = hs[t[p].r+1] - hs[t[p].l];
t[p].lc = t[p].rc = t[p].c = 1;
}
else{
if(t[p].l == t[p].r) {//当前区间未被覆盖且为子区间
t[p].len = 0;
t[p].lc = t[p].rc = t[p].c = 0;
}
else {//合并两个子区间
t[p].len = t[p<<1].len + t[p<<1|1].len;
t[p].lc = t[p<<1].lc;
t[p].rc = t[p<<1|1].rc;
t[p].c = t[p<<1].c + t[p<<1|1].c;
if(t[p<<1].rc && t[p<<1|1].lc) t[p].c--;
}
}
}
void modify(int p,int l,int r,int x){
if(l <= t[p].l && r >= t[p].r){
t[p].cnt += x;
pushup(p);
return;
}
int mid = t[p].l + t[p].r >> 1;
if(l <= mid) modify(p<<1,l,r,x);
if(r > mid) modify(p<<1|1,l,r,x);
pushup(p);
}
int main(){
std::cin >> n;
std::vector<line>e(1);
for(int i = 1;i <= n;i++){
int x1,y1,x2,y2;std::cin >> x1 >> y1 >> x2 >> y2;
e.push_back({x1,x2,y1,1});
e.push_back({x1,x2,y2,-1});
hs.push_back(x1);
hs.push_back(x2);
}
std::sort(e.begin()+1,e.end());
std::sort(hs.begin()+1,hs.end());
hs.erase(std::unique(hs.begin()+1,hs.end()),hs.end());
for(int i = 1;i <= n << 1;i++){
e[i].l = std::lower_bound(hs.begin()+1,hs.end(),e[i].l) - hs.begin();
e[i].r = std::lower_bound(hs.begin()+1,hs.end(),e[i].r) - hs.begin();
}
int m = hs.size() - 1;
build(1,1,m-1);
long long ans = 0;
long long last = 0;
for(int i = 1;i <= n << 1;i++){
auto &[l,r,h,w] = e[i];
modify(1,l,r-1,w);
ans += std::abs(t[1].len - last);//计算横边(i <= 2*n)
last = t[1].len;
if(i < n << 1) ans += 2 * t[1].c * (e[i+1].h - e[i].h);//计算竖边(i <= 2*n-1)
}
std::cout << ans;
}
二维数点
U245713 【模板】 二维数点 - 洛谷 (luogu.com.cn)
给定一个长度为
n的序列a[],然后进行m次询问:求区间[l,r]内大小在[x,y]范围内的数的个数。
 把
把a[i]看作平面上的一个点(i,a[i]),询问即为求矩形内包含多少个点。
我们将询问离线,用一条线从左往右扫描,每遇到一个点就把它加入一个集合,表示当前所有扫过的点,用权值树状数组维护集合。每个询问的答案即为1~r内位于[x,y]的数的个数减去1~l-1内位于[x,y]的数的个数。
#include <iostream>
#include <vector>
#include <algorithm>
const int N = 1000006;
struct ask{
int l,r,x,y;
};
struct node{
int x,y,w,id;//w = 1表示当前为r,w = -1表示当前为l-1
};
std::vector<node>e[N];
int t[N*3],siz;//对离散化后的a[],x[],y[]建立权值树状数组,至少开三倍大小
void add(int i,int x){
while(i <= siz){
t[i] += x;
i += i&-i;
}
}
int query(int i){
int res = 0;
while(i){
res += t[i];
i -= i&-i;
}
return res;
}
std::vector<int> sol(std::vector<int>&a,std::vector<ask>&q){
std::vector<int>ans(q.size());
std::vector<int>hs(1,-2e9);
for(int i = 1;i < a.size();i++){
hs.push_back(a[i]);
}
for(int i = 1;i < q.size();i++){
auto &[l,r,x,y] = q[i];
hs.push_back(x);
hs.push_back(y);
}
std::sort(hs.begin()+1,hs.end());
hs.erase(std::unique(hs.begin()+1,hs.end()));
siz = hs.size();
for(int i = 1;i < a.size();i++){
a[i] = std::lower_bound(hs.begin()+1,hs.end(),a[i]) - hs.begin();
}
for(int i = 1;i < q.size();i++){
auto &[l,r,x,y] = q[i];
x = std::lower_bound(hs.begin()+1,hs.end(),x) - hs.begin();
y = std::lower_bound(hs.begin()+1,hs.end(),y) - hs.begin();
e[l-1].push_back({x,y,-1,i});
e[r].push_back({x,y,1,i});
}
for(int i = 1;i < a.size();i++){
add(a[i],1);
for(auto &[x,y,w,id]:e[i]){
ans[id] += w*(query(y) - query(x-1));//query(y) - query(x-1)即为当前位于[x,y]的点的个数
}
}
return ans;
}
int main(){
std::ios::sync_with_stdio(false);std::cin.tie(0);
int n,m; std::cin >> n >> m;
std::vector<int> a(n+1);
std::vector<ask> q(m+1);
for(int i = 1;i <= n;i++){
std::cin >> a[i];
}
for(int i = 1;i <= m;i++){
auto &[l,r,x,y] = q[i];
std::cin >> l >> r >> x >> y;
}
auto ans = sol(a,q);
for(int i = 1;i <= m;i++){
std::cout << ans[i] << '\n';
}
}
类似的,诺给定二维平面上的点集[x,y],然后给出诺干个询问求矩形[x1,y1,x2,y2]内有多少个点,则需要分别将所有横纵坐标都离散化。例题[P2163 SHOI2007] 园丁的烦恼 - 洛谷 (luogu.com.cn)
#include <iostream>
#include <vector>
#include <algorithm>
const int N = 500005;
struct Point{
int x,y;
};
struct Ask{
int x1,y1,x2,y2;
};
struct Node{
int x,y,w,id;
};
std::vector<Node>e[N*3];//x,x1,x2
int t[N*3],siz;//y,y1,y1
void add(int i,int x){
while(i <= siz){
t[i] += x;
i += i&-i;
}
}
int query(int i){
int res = 0;
while(i){
res += t[i];
i -= i&-i;
}
return res;
}
std::vector<int> sol(std::vector<Point>&p,std::vector<Ask>&ask){
std::vector<int> ans(ask.size());
std::vector<int> dx(1,-2e9),dy(1,-2e9);
for(int i = 1;i < p.size();i++){
auto &[x,y] = p[i];
dx.push_back(x);
dy.push_back(y);
}
for(int i = 1;i < ask.size();i++){
auto &[x1,y1,x2,y2] = ask[i];
dx.push_back(x1); dx.push_back(x2);
dy.push_back(y1); dy.push_back(y2);
}
std::sort(dx.begin()+1,dx.end()); dx.erase(std::unique(dx.begin()+1,dx.end()),dx.end());
std::sort(dy.begin()+1,dy.end()); dy.erase(std::unique(dy.begin()+1,dy.end()),dy.end());
siz = dy.size()-1;
for(int i = 1;i < p.size();i++){
auto &[x,y] = p[i];
x = std::lower_bound(dx.begin()+1,dx.end(),x) - dx.begin();
y = std::lower_bound(dy.begin()+1,dy.end(),y) - dy.begin();
e[x].push_back({y,y,0,0});
}
for(int i = 1;i < ask.size();i++){
auto &[x1,y1,x2,y2] = ask[i];
x1 = std::lower_bound(dx.begin()+1,dx.end(),x1) - dx.begin();
x2 = std::lower_bound(dx.begin()+1,dx.end(),x2) - dx.begin();
y1 = std::lower_bound(dy.begin()+1,dy.end(),y1) - dy.begin();
y2 = std::lower_bound(dy.begin()+1,dy.end(),y2) - dy.begin();
e[x1-1].push_back({y1,y2,-1,i});
e[x2].push_back({y1,y2,1,i});
}
//这里没有分开将点和询问分开存储,而是用e[i].w为0或者1/-1,表示当前是点还是询问。因为是先push点,再push询问,保证了处理询问前会先处理与询问相关的点
for(int i = 1;i < dx.size();i++){
for(auto &[y1,y2,w,id]:e[i]){
if(w == 0){ add(y1,1); }//扫描到点,则将点加入集合
else{ ans[id] += w*(query(y2) - query(y1-1)); }//否则处理询问
}
}
return ans;
}
int main(){
int n,m; std::cin >> n >> m;
std::vector<Point>p(n+1);
std::vector<Ask>ask(m+1);
for(int i = 1;i <= n;i++){
auto &[x,y] = p[i];
std::cin >> x >> y;
}
for(int i = 1;i <= m;i++){
auto &[x1,y1,x2,y2] = ask[i];
std::cin >> x1 >> y1 >> x2 >> y2;
}
auto ans = sol(p,ask);
for(int i = 1;i <= m;i++){
std::cout << ans[i] << '\n';
}
}
平面几何
点线封装
| 点、向量 Point |
||||||
|---|---|---|---|---|---|---|
p1 +- p2 |
向量加减 | $\vec{p_1} + \vec{p_2} = (x_1 + x2 , y_1 + y_2)$ | ||||
p */ x |
向量乘除标量 | $v\ \vec{p_1} = (x_1 \times v,y_1 \times v)$ | ||||
dot(p1,p2) |
点积 | $\vec{p_1} \cdot \vec{p_2} = x_1x_2 + y_1y_2 = | \vec{p_1} | \vec{p_2} | cos \theta$ | ||
cross(p1,p2) |
叉积 | $\vec{p_1}\times \vec{p_2} = x_1y_2 - x_2y_1 = | \vec{p_1} | \vec{p_2} | sin\theta \vec{n}$ | |
length(p) |
向量的模 | $ | \vec{p_1} | = \sqrt{x_1^2 + y_1^2}$ | ||
normalize(p) |
单位向量 | $\hat{p_1} = \frac{\vec{p_1}}{ | \vec{p_1} | }$ | ||
distance(p1,p2) |
两点之间距离(欧几里得距离) | |||||
rotate(p) |
向量逆时针旋转90度 | |||||
sgn(p) |
判断向量所在象限(一/四:1,二/三:-1) | |||||
pointInPolygon(p,vec<Point>) |
判断$点$是否在$多边形$内部或多边形边上(射线法,0_idx) | 多边形的点需要按顺/逆时针顺序排列,仅支持简单多边形(不自交) |
| 线 Line |
||
|---|---|---|
length(l) |
$线段$长度 | |
distancePS(p,l) |
$点$到$线段$Segment距离 | |
pointOnSegment(p,l) |
判断$点$是否在$线段$上 | |
distanceSS(l1,l2) |
两$线段$最短距离 | |
segmentIntersection(l1,l2) |
$线段$相交判定 返回值: tuple(类型,交点1,交点2) |
0:不相交 1:严格相交(交点在两线段内部) 2:重叠(返回重叠部分的两个端点) 3:端点相交(交点为线段端点) |
segmentInPolygon(l,vec<Point>) |
$线段$是否在$多边形$内部 | (需满足:端点在内且不与任何边$严格相交$)。多变形的点需要按顺/逆时针顺序排列 |
distancePL(p,l) |
$点$到$直线$Line距离 | |
parallel(l1,l2) |
判断两$直线$是否平行或共线(叉积为0) | 1:共线 2:平行 0:相交 |
lineIntersection(l1,l2) |
求两$直线$交点 (需要保证不平行/共线) | |
pointOnLineLeft(p,l) |
$点$是否在$直线$($\vec{ab}$)左侧(叉积为正) | 以直线的方向向量$\vec{ab}$方向为基准 |
hp(vec<Line>) |
返回$凸多边形$顶点集(半平面交S&I算法,并按逆时针排列) | 传入的参数不需要预先排列 |
template<typename T>
struct Point {
T x,y;
Point (const T &_x = 0,const T &_y = 0) : x(_x),y(_y){}
template<typename U>//自动类型转换
operator Point<U>() {
return Point<U>(U(x), U(y));
}
Point &operator+=(const Point &p) & {
x += p.x; y += p.y;
return *this;
}
Point &operator-=(const Point &p) & {
x -= p.x; y -= p.y;
return *this;
}
Point &operator*=(const T &v) & {
x *= v; y *= v;
return *this;
}
Point &operator/=(const T &v) & {
x /= v; y /= v;
return *this;
}
Point operator-() const { return Point(-x, -y); }
friend Point operator+(Point a, const Point &b) { return a += b; }
friend Point operator-(Point a, const Point &b) { return a -= b; }
friend Point operator*(Point a, const T &b) { return a *= b; }
friend Point operator/(Point a, const T &b) { return a /= b; }
friend Point operator*(const T &a, Point b) { return b *= a; }
friend bool operator==(const Point &a, const Point &b) { return a.x == b.x && a.y == b.y; }
friend bool operator!=(const Point &a,const Point &b) { return !(a == b);}
friend std::istream &operator>>(std::istream &is, Point &p) {
return is >> p.x >> p.y;
}
friend std::ostream &operator<<(std::ostream &os, const Point &p) {
return os << "(" << p.x << "," << p.y << ")";
}
};
template<typename T>//点乘
T dot(const Point<T> &p1,const Point<T>&p2){
return p1.x*p2.x + p1.y*p2.y;
}
template<typename T>//叉乘
T cross(const Point<T> &p1,const Point<T>&p2){
return p1.x*p2.y - p1.y*p2.x;
}
template<typename T>//向量的模
double length(const Point<T> &p){
return std::sqrt(dot(p,p));
}
template<typename T>//单位向量
Point<T> normalize(const Point<T> &p) {
return p/length(p);
}
template<typename T>//两点之间距离(欧几里得距离)
double distance(const Point<T> &p1,const Point<T> &p2){
return length(p1-p2);
}
template<typename T>//向量逆时针旋转90度
Point<T> rotate(const Point<T> &p){
return Point(-p.y,p.x);
}
template<typename T>// 判断向量所在象限(第一/四象限为1,第二/三象限为-1)
int sgn(const Point<T> &a) {
return a.y > 0 || (a.y == 0 && a.x > 0) ? 1 : -1;
}
template<typename T>
struct Line{
Point<T>a,b;
Line (const Point<T> &_a = Point<T>(),const Point<T> &_b = Point<T>()) : a(_a),b(_b){}
template<typename U>
operator Line<U>(){
return Line<U>(Point<U>(a),Point<U>(b));
}
};
template<typename T>//线段长度
double length(const Line<T> &l){
return length(l.a-l.b);
}
template<typename T>//判断两直线是否平行(叉积为0)
int parallel(const Line<T> &l1,const Line<T> &l2){
if(cross(l1.b-l1.a,l2.b-l2.a) == 0){
if(distancePL(l2.b,l1) == 0) return 1;//共线
else return 2;//平行
}
return 0;
}
template<typename T>//点到直线距离
double distancePL(const Point<T> &p,const Line<T> &l){
return std::abs(cross(l.a-l.b,l.a-p)) / length(l);
}
template<typename T>//点到线段距离
double distancePS(const Point<T> &p, const Line<T> &l) {
if (dot(p - l.a, l.b - l.a) < 0) { return distance(p, l.a); }
if (dot(p - l.b, l.a - l.b) < 0) { return distance(p, l.b); }
return distancePL(p, l);
}
template<typename T>//点是否在直线左侧
bool pointOnLineLeft(const Point<T> &p, const Line<T> &l) {
return cross(l.b - l.a, p - l.a) > 0;
}
template<typename T>//求两直线交点(需确保不平行)
Point<T> lineIntersection(const Line<T> &l1, const Line<T> &l2) {
return l1.a + (l1.b - l1.a) * (cross(l2.b - l2.a, l1.a - l2.a) / cross(l2.b - l2.a, l1.a - l1.b));
}
template<typename T>//判断点是否在线段上
bool pointOnSegment(const Point<T> &p, const Line<T> &l) {
return cross(p - l.a, l.b - l.a) == 0 && std::min(l.a.x, l.b.x) <= p.x && p.x <= std::max(l.a.x, l.b.x)
&& std::min(l.a.y, l.b.y) <= p.y && p.y <= std::max(l.a.y, l.b.y);
}
template<typename T>//判断点是否在多边形内部(或多边形上) 0_idx,多边形点集需要按顺序排列
bool pointInPolygon(const Point<T> &a, const std::vector<Point<T>> &p) {
int n = p.size();
for (int i = 0; i < n; i++) {
if (pointOnSegment(a, Line(p[i], p[(i + 1) % n]))) {
return true;
}
}
int t = 0;
for (int i = 0; i < n; i++) {
auto u = p[i];
auto v = p[(i + 1) % n];
if (u.x < a.x && v.x >= a.x && pointOnLineLeft(a, Line(v, u))) {
t ^= 1;
}
if (u.x >= a.x && v.x < a.x && pointOnLineLeft(a, Line(u, v))) {
t ^= 1;
}
}
return t == 1;
}
/*
线段相交判定
返回值:tuple(类型,交点1,交点2)
类型:
0:不相交
1:严格相交(交点在两线段内部)
2:重叠(返回重叠部分的两个端点)
3:端点相交(交点为线段端点)
*/
template<typename T>
std::tuple<int, Point<T>, Point<T>> segmentIntersection(const Line<T> &l1, const Line<T> &l2) {
if (std::max(l1.a.x, l1.b.x) < std::min(l2.a.x, l2.b.x)) {
return {0, Point<T>(), Point<T>()};
}
if (std::min(l1.a.x, l1.b.x) > std::max(l2.a.x, l2.b.x)) {
return {0, Point<T>(), Point<T>()};
}
if (std::max(l1.a.y, l1.b.y) < std::min(l2.a.y, l2.b.y)) {
return {0, Point<T>(), Point<T>()};
}
if (std::min(l1.a.y, l1.b.y) > std::max(l2.a.y, l2.b.y)) {
return {0, Point<T>(), Point<T>()};
}
if (cross(l1.b - l1.a, l2.b - l2.a) == 0) {
if (cross(l1.b - l1.a, l2.a - l1.a) != 0) {
return {0, Point<T>(), Point<T>()};
}
else {
auto maxx1 = std::max(l1.a.x, l1.b.x);
auto minx1 = std::min(l1.a.x, l1.b.x);
auto maxy1 = std::max(l1.a.y, l1.b.y);
auto miny1 = std::min(l1.a.y, l1.b.y);
auto maxx2 = std::max(l2.a.x, l2.b.x);
auto minx2 = std::min(l2.a.x, l2.b.x);
auto maxy2 = std::max(l2.a.y, l2.b.y);
auto miny2 = std::min(l2.a.y, l2.b.y);
Point<T> p1(std::max(minx1, minx2), std::max(miny1, miny2));
Point<T> p2(std::min(maxx1, maxx2), std::min(maxy1, maxy2));
if (!pointOnSegment(p1, l1)) { std::swap(p1.y, p2.y); }
if (p1 == p2) return {3, p1, p2};
else return {2, p1, p2};
}
}
auto cp1 = cross(l2.a - l1.a, l2.b - l1.a);
auto cp2 = cross(l2.a - l1.b, l2.b - l1.b);
auto cp3 = cross(l1.a - l2.a, l1.b - l2.a);
auto cp4 = cross(l1.a - l2.b, l1.b - l2.b);
if ((cp1 > 0 && cp2 > 0) || (cp1 < 0 && cp2 < 0) || (cp3 > 0 && cp4 > 0) || (cp3 < 0 && cp4 < 0)) {
return {0, Point<T>(), Point<T>()};
}
Point p = lineIntersection(l1, l2);
if (cp1 != 0 && cp2 != 0 && cp3 != 0 && cp4 != 0) return {1, p, p};
else return {3, p, p};
}
template<typename T>//返回两线段最短距离
double distanceSS(const Line<T> &l1, const Line<T> &l2) {
if (std::get<0>(segmentIntersection(l1, l2)) != 0) {
return 0.0;
}
return std::min({distancePS(l1.a, l2), distancePS(l1.b, l2), distancePS(l2.a, l1), distancePS(l2.b, l1)});
}
template<typename T>//线段是否在多边形内部(需满足:端点在内且不与任何边严格相交),多边形点集需要按顺序排列
bool segmentInPolygon(const Line<T> &l, const std::vector<Point<T>> &p) {
int n = p.size();
if (!pointInPolygon(l.a, p)) { return false; }
if (!pointInPolygon(l.b, p)) { return false; }
for (int i = 0; i < n; i++) {
auto u = p[i];
auto v = p[(i + 1) % n];
auto w = p[(i + 2) % n];
auto [t, p1, p2] = segmentIntersection(l, Line(u, v));
if (t == 1) { return false; }
if (t == 0) { continue; }
if (t == 2) {
if (pointOnSegment(v, l) && v != l.a && v != l.b) {
if (cross(v - u, w - v) > 0) {
return false;
}
}
}
else {
if (p1 != u && p1 != v) {
if (pointOnLineLeft(l.a, Line(v,u)) || pointOnLineLeft(l.b, Line(v,u))) {
return false;
}
}
else if (p1 == v) {
if (l.a == v) {
if (pointOnLineLeft(u, l)) {
if (pointOnLineLeft(w, l) && pointOnLineLeft(w, Line(u, v))) {
return false;
}
}
else {
if (pointOnLineLeft(w, l) || pointOnLineLeft(w, Line(u, v))) {
return false;
}
}
}
else if (l.b == v) {
if (pointOnLineLeft(u, Line(l.b, l.a))) {
if (pointOnLineLeft(w, Line(l.b, l.a)) && pointOnLineLeft(w,Line(u,v))) {
return false;
}
}
else {
if (pointOnLineLeft(w, Line(l.b,l.a)) || pointOnLineLeft(w,Line(u,v))) {
return false;
}
}
}
else {
if (pointOnLineLeft(u, l)) {
if (pointOnLineLeft(w, Line(l.b,l.a)) || pointOnLineLeft(w,Line(u,v))) {
return false;
}
}
else {
if (pointOnLineLeft(w, l) || pointOnLineLeft(w, Line(u, v))) {
return false;
}
}
}
}
}
}
return true;
}
template<typename T>//返回凸多边形顶点集 0_idx
std::vector<Point<T>> hp(std::vector<Line<T>> lines) {
std::sort(lines.begin(), lines.end(), [&](auto l1, auto l2) {
auto d1 = l1.b - l1.a;
auto d2 = l2.b - l2.a;
if (sgn(d1) != sgn(d2)) {
return sgn(d1) == 1;
}
return cross(d1, d2) > 0;
});
std::deque<Line<T>> ls;
std::deque<Point<T>> ps;
for (auto l : lines) {
if (ls.empty()) {
ls.push_back(l);
continue;
}
while (!ps.empty() && !pointOnLineLeft(ps.back(), l)) {
ps.pop_back();
ls.pop_back();
}
while (!ps.empty() && !pointOnLineLeft(ps[0], l)) {
ps.pop_front();
ls.pop_front();
}
if (cross(l.b - l.a, ls.back().b - ls.back().a) == 0) {
if (dot(l.b - l.a, ls.back().b - ls.back().a) > 0) {
if (!pointOnLineLeft(ls.back().a, l)) {
assert(ls.size() == 1);
ls[0] = l;
}
continue;
}
return {};
}
ps.push_back(lineIntersection(ls.back(), l));
ls.push_back(l);
}
while (!ps.empty() && !pointOnLineLeft(ps.back(), ls[0])) {
ps.pop_back();
ls.pop_back();
}
if (ls.size() <= 2) { return {}; }
ps.push_back(lineIntersection(ls[0], ls.back()));
return std::vector(ps.begin(), ps.end());
}
其它
中位数
一般要求最大化中位数之类的题目,可以二分一个数x,诺a[i] >= x则赋权值w[i]为1,否则为-1,判断某一区间中位数是否大于等于x,即求该区间和是否大于0。
对顶堆
动态维护中位数,插入/删除O(log),查找O(1)
se1的末尾元素即为中位数

multiset<int>se1,se2;
void balance(){//每次插入/删除后平衡两个集合
while(se1.size() > se2.size()){
se2.insert(*se1.rbegin());
se1.erase(prev(se1.end()));
}
while(se1.size() < se2.size()){
se1.insert(*se2.begin());
se2.erase(se2.begin());
}
}
void add(int x){//插入元素
se1.insert(x);
balance();
}
void del(int x){//删除元素
if(x <= *se1.rbegin()) se1.erase(se1.find(x));
else se2.erase(se2.find(x));
balance();
}
int query(){//查找中位数
return *se1.rbegin();
}
例题:
题意:定义一个数组的连续子数组(a[l] ~ a[r])每一项满足 $a_{i+1} =a_i + 1$ 为一个彩虹子数组,可以至多进行 k 次操作使任意$a_i+1$或$a_i-1$,求能构造出的最长彩虹子数组
思路:考虑$a_{i+1} =a_i + 1$可以转化为$a_{i+1} - (i + 1) = a_i - i $,所以先预处理把所有的$a_i$减去自己下标,问题就变成了:把一个区间的所有数字全部变成一个相同的数字,很容易知道,最小代价就是把所有数变成中位数即可,所以接下来就用一个双指针滑动窗口来维护,求最大的区间长度,这里动态维护滑动窗口的中位数用两个multiset
//https://codeforces.com/gym/104901/problem/K
#include <iostream>
#include <vector>
#include <set>
using namespace std;
using ll = long long;
int n;
multiset<int>se1,se2;
ll sum1,sum2;//sum1统计se1的和,sum2统计se2的和
void balance(){
while(se1.size() > se2.size()){
sum2 += *se1.rbegin();
sum1 -= *se1.rbegin();
se2.insert(*se1.rbegin());
se1.erase(prev(se1.end()));
}
while(se1.size() < se2.size()){
sum1 += *se2.begin();
sum2 -= *se2.begin();
se1.insert(*se2.begin());
se2.erase(se2.begin());
}
}
void add(int x){
se1.insert(x);
sum1 += x;
balance();
}
void del(int x){
if(x <= *se1.rbegin()) {se1.erase(se1.find(x)),sum1 -= x;}
else {se2.erase(se2.find(x)),sum2 -= x;}
balance();
}
ll query(){
return *se1.rbegin();
}
ll all(){//返回 使所有数变为中位数所需要的操作次数
return (se1.size()*query()-sum1) + (sum2-se2.size()*query());
}
void sol(){
se1.clear();se2.clear();
sum1 = sum2 = 0;
ll n,k;cin >> n >> k;
vector<ll>a(n+1);
for(int i = 1;i <= n;i++){
cin >> a[i];
a[i] -= i;
}
int ans = 1;
ll sum = 0;
for(int l = 0,r = 0;r <= n;){
while(sum <= k){
ans = max(ans,r-l+1);
r++;
if(r > n) break;
add(a[r]);
sum = all();
}
while(sum > k){
l++;
del(a[l]);
sum = all();
}
}
cout << ans-1 << endl;
}
int main(){
int tt;cin >> tt;
while(tt--){ sol(); }
return 0;
}
第k小数求中位数
查找O(N)
快排 或STL函数nth_element()
主席树
可持久化权值线段树
求区间第k小,不支持修改
//https://ac.nowcoder.com/acm/contest/91177/F
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
constexpr int MAXN = 1e5;
int tot, n, m;
int sum[(MAXN << 5) + 10], rt[MAXN + 10], ls[(MAXN << 5) + 10],rs[(MAXN << 5) + 10];
int a[MAXN + 10], ind[MAXN + 10], len;
int getid(const int &val) { // 离散化
return lower_bound(ind + 1, ind + len + 1, val) - ind;
}
int build(int l, int r) { // 建树
int root = ++tot;
if (l == r) return root;
int mid = l + r >> 1;
ls[root] = build(l, mid);
rs[root] = build(mid + 1, r);
return root; // 返回该子树的根节点
}
int update(int k, int l, int r, int root) { // 插入操作
int dir = ++tot;
ls[dir] = ls[root], rs[dir] = rs[root], sum[dir] = sum[root] + 1;
if (l == r) return dir;
int mid = l + r >> 1;
if (k <= mid)
ls[dir] = update(k, l, mid, ls[dir]);
else
rs[dir] = update(k, mid + 1, r, rs[dir]);
return dir;
}
int query(int u, int v, int l, int r, int k) { // 查询操作
int mid = l + r >> 1,
x = sum[ls[v]] - sum[ls[u]]; // 通过区间减法得到左儿子中所存储的数值个数
if (l == r) return l;
if (k <= x) // 若 k 小于等于 x ,则说明第 k 小的数字存储在在左儿子中
return query(ls[u], ls[v], l, mid, k);
else // 否则说明在右儿子中
return query(rs[u], rs[v], mid + 1, r, k - x);
}
void init() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; ++i) scanf("%d", a + i);
memcpy(ind, a, sizeof ind);
sort(ind + 1, ind + n + 1);
len = unique(ind + 1, ind + n + 1) - ind - 1;
rt[0] = build(1, len);
for (int i = 1; i <= n; ++i) rt[i] = update(getid(a[i]), 1, len, rt[i - 1]);
}
int l, r, k;
void work() {
while (m--) {
cin >> l >> r;//查询区间[l,r]中第k小
//cin >> k;
k = (r-l+2) >> 1;
printf("%d\n", ind[query(rt[l - 1], rt[r], 1, len, k)]);
}
}
int main() {
init();
work();
}
均值不等式
\[\frac{a_1+a_2+...+a_n}{n} >= \sqrt[n]{a_1*a_2*...*a_n}\] \[\frac{2}{\frac{1}{a}+\frac{1}{b}} <= \sqrt{ab} <= \frac{a+b}{2} <= \sqrt{\frac{a^2+b^2}{2}}\]约瑟夫环
n 个人标号 $0,1,\cdots, n-1$。逆时针站一圈,从 $0$ 号开始,每一次从当前的人逆时针数 $k$ 个,然后让这个人出局。问最后剩下的人是谁。
//O(N)
int josephus(int n, int k) {
int res = 0;
for (int i = 1; i <= n; ++i) res = (res + k) % i;
return res;
}
//O(KlogN)
int josephus(int n, int k) {
if (n == 1) return 0;
if (k == 1) return n - 1;
if (k > n) return (josephus(n - 1, k) + k) % n; // 线性算法
int res = josephus(n - n / k, k);
res -= n % k;
if (res < 0) res += n; // mod n
else res += res / (k - 1); // 还原位置
return res;
}
吉姆拉尔森日期公式
给定具体日期,推当天是星期几。也可以求两个日期的天数之差等等。
const int d[] = {31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
bool isLeap(int y) {//判断当前年是否为闰年
return y % 400 == 0 || (y % 4 == 0 && y % 100 != 0);
}
int daysInMonth(int y, int m) {
return d[m - 1] + (isLeap(y) && m == 2);
}
int getDay(int y, int m, int d) {
int ans = 0;
for (int i = 1970; i < y; i++) {
ans += 365 + isLeap(i);
}
for (int i = 1; i < m; i++) {
ans += daysInMonth(y, i);
}
ans += d;
//return ans; //返回今天是从1970.1.1起的第几天?(1970.1.1为第1天,星期4)
return (ans + 2) % 7 + 1;//返回今天是星期几?[1,2,3,4,5,6,7]
}
二维和一维坐标转化
下标从0开始
n行m列
idx = i*m + j
(i,j) = (idx/m,idx%m)
| 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 |
下标从1开始
n行m列
idx = (i-1)*m + j
(i,j) = ((idx+m-1)/m,(idx%m)? idx%m : m)
| 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 |
基础算法
前缀和&差分
在头文件
中也包含了一维前缀和/差分函数 int a[6] = {1,2,3,4,5,6},s[6]; partial_sum(a,a+6,s); //s = {1,3,6,10,15,21} adjacent_difference(a,a+6,s); //s = {1,1,1,1,1,1}
一维前缀和
pre[i] = a[1]+a[2] +…+a[i] = pre[i-1]+a[i] 前缀和数组一般下标从1开始,方便写
//求第a个数到第b个数的和
#include<iostream>
using namespace std;
int arr[1000006]; int pre[1000006];
int main() {
int k; cin >> k;
for (int i = 1;i <= k;i++){
scanf("%d", &arr[i]);
pre[i] += pre[i - 1] + arr[i];
}
int a, b; cin >> a >> b;
cout << pre[b] - pre[a - 1] << endl;
return 0;
}
//异或前缀和
for(int i = 1;i <= n;i++){
s[i] = s[i-1]^a[i];
}
ans = s[r]^s[l-1];
二维前缀和
子矩阵的和:
//每个点的S的求法,可以直接推
s[i][j] = s[i-1][j] + s[i][j-1] - s[i-1][j-1] + a[i][j];
//也可以先枚举维,然后对每一维做前缀和
s[i][j]=s[i][j-1]+a[i][j];
s[i][j]=s[i-1][j]+a[i][j];

//某一块S的求法:s[x1][y1]~s[x2][y2]
s[x2][y2] - s[x1-1][y2] - s[x2][y1-1] + s[x1-1][y1-1];
| x1,y1 | ||||||
| x2,y2 | ||||||
#include<iostream>
using namespace std;
const int N = 10006;
int arr[N][N]; int s[N][N];
int n, m;
int query(int x1,int y1,int x2,int y2){
return s[x2][y2] - s[x1-1][y2] - s[x2][y1-1] + s[x1-1][y1-1];
}
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
scanf("%d", &arr[i][j]);
for (int i = 1; i <= n; i++) //利用前缀和求每一点的S
for (int j = 1; j <= m; j++)
s[i][j] = s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1] + arr[i][j];
int x1, y1, x2, y2;
cin >> x1 >> y1 >> x2 >> y2;//求子矩阵x1,y1 ~ x2,y2的S
cout << query(x1,y1,x2,y2) << endl;
return 0;
}
一维差分
dif[1] + dif[2] + … + dif[i] = a[i]; 往往与前缀和联系
dif[i] = arr[i] - arr[i-1];
//https://www.luogu.com.cn/problem/P2367
#include <iostream>
using namespace std;
int arr[5000006], dif[5000006];
int main() {
int n, p; cin >> n >> p;
for (int i = 1; i <= n; i++){
scanf("%d", &arr[i]);//输入数据较多时建议scanf/printf 比cin/cout快,
dif[i] = arr[i] - arr[i - 1];
}
while (p--){
int x, y, z;
scanf("%d%d%d", &x, &y, &z);//区间[x,y]加x
dif[x] += z;
dif[y + 1] -= z;
}
int low = 1e9;
for (int i = 1; i <= n; i++){
arr[i] = arr[i - 1] + dif[i];
low = low < arr[i] ? low : arr[i];
}
cout << low << endl;
return 0;
}
//增减序列:https://www.acwing.com/problem/content/102/
//给定数组a[n],每次可选一个区间[l,r]内的数都+1或-1,求使所有数都一样的最小操作次数和最终序列有多少种
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100005;
using ll = long long;
int n;
ll a[N],dif[N];
int main(){
cin >> n;
for(int i = 1;i <= n;i++){
cin >> a[i];
dif[i] = a[i] - a[i-1];
}
ll pos = 0,neg = 0;
//如果这个数列的值都是一样的,最后我们的差分数组一定是b[1]=一个常数,b[2]~b[n]都等于0
for(int i = 2;i <= n;i++){
if(dif[i] > 0) pos += dif[i];//pos表示sum(正数->0)
if(dif[i] < 0) neg += -dif[i];//neg表示sum(负数->0)
}//正负两个数可以相消二者取最小min,最后差分就只剩同符号的数abs(pos-neg)
cout << min(pos,neg) + abs(pos - neg) << endl;
cout << abs(pos - neg) + 1;
return 0;
}
二维差分
//https://www.acwing.com/problem/content/800/
//给定n*m的矩阵和q次插入操作,每次操作将子矩阵(x1,y1,x2,y2)的值加上c,求q次操作后的矩阵
#include <iostream>
using namespace std;
int a[1006][1006]; int dif[1006][1006];
int n, m, q;
void insert(int x1, int y1, int x2, int y2, int c) {
dif[x1][y1] += c;
dif[x2 + 1][y1] -= c;
dif[x1][y2 + 1] -= c;
dif[x2 + 1][y2 + 1] += c;
}
int main() {
cin >> n >> m >> q;
for (int i = 1; i <= n; i++){
for (int j = 1; j <= m; j++){
scanf("%d", &a[i][j]);
insert(i, j, i, j, a[i][j]);//初始化插入a[i][j]
}
}
while (q--) {
int x1, y1, x2, y2, c; //进行q次插入操作
scanf("%d%d%d%d%d", &x1, &y1, &x2, &y2, &c);
insert(x1, y1, x2, y2, c);
}
for (int i = 1; i <= n; i++)//利用前缀和求改变后的数组
for (int j = 1; j <= m; j++)
dif[i][j] += dif[i-1][j] + dif[i][j-1] - dif[i-1][j-1];
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++)
printf("%d ", dif[i][j]);
printf("\n");
}
}
二分
二分查找
目标数组需要为非降序排列
#include <iostream>
using namespace std;
int n, x, arr[1000006];
bool check1(int mid) {
return arr[mid] >= x;
}
bool check2(int mid) {
return arr[mid] <= x;
}
int main() {
scanf("%d%d", &n, &x);
for (int i = 0; i < n; i++) {
scanf("%d", &arr[i]);
}
int l = 0, r = n - 1;//找到第一个>=x值的下标 (与lower_bound略有不同)
while (l < r) { //0000x1111型 (x为目标)
int mid = l + r >> 1;
if (check1(mid)) r = mid;
else l = mid + 1;
}
if(arr[l] < x) cout << -1 << endl;//诺不存在>=x的值,返回的是最后一个元素下标,而lb返回的是end()
else cout << l << endl;
l = 0, r = n - 1;//找到最后一个<=x值的下标 (与upper_bound不同)
while (l < r) { //1111x0000型 (x为目标)
int mid = l + r + 1 >> 1;
if (check2(mid)) l = mid;
else r = mid - 1;
}
if(arr[l] > x) cout << -1 << endl;//诺不存在<=x的值,返回的是第一个元素的下标
cout << l << endl;
return 0;
}
二分答案
单调区间中,每次查找去掉不符合条件的一半区间,直到找到答案(整数二分)或者和答案十分接近
//模版与二分查找一样
//check(mid)为:...00001111...型 (第一个1为目标)
int l = 0, r = 1e9;
while (l < r) {
int mid = l + r >> 1;
if (check(mid)) r = mid;
else l = mid + 1;
}
cout << l;
//check(mid)为:...111110000...型 (最后一个1为目标)
int l = 0, r = 1e9;
while (l < r){
int mid = l + r + 1 >> 1;
if (check(mid)) l = mid ;
else r = mid - 1;
}
cout << l;
//最小化极值:https://codeforces.com/contest/2013/problem/D
//题意:对于数组a,可以任意次选择i(1~n-1),使a[i]--,a[i+1]++,请最小化极差
//思路:分别二分最小的最大值,最大的最小值,二者之差即为答案
#include <bits/stdc++.h>
using ll = long long;
using namespace std;
const int N = 200005;
int n;
bool check1(ll mid,vector<ll>&a){
ll cnt = 0;
for(int i = 1;i <= n;i++){
if(a[i] > mid) cnt+=a[i]-mid;
if(a[i] < mid) cnt = max((ll)0,cnt - (mid-a[i]));
}
return cnt == 0;
}
bool check2(ll mid,vector<ll>&a){
ll cnt = 0;
for(int i = 1;i <= n;i++){
if(a[i] > mid) cnt += a[i]-mid;
if(a[i] < mid) cnt -= mid-a[i];
if(cnt < 0) return 0;
}
return 1;
}
void sol(){
cin >> n;
vector<ll>a(n+1);
for_each(a.begin()+1,a.begin()+n+1,[](auto &x){cin >> x;});
ll l = 0,r = 1e18;
while(l < r){
ll mid = l+r>> 1;
if(check1(mid,a)) r=mid;
else l=mid+1;
}
ll ans1 = l;
l = 0,r = 1e18;
while(l < r){
ll mid = l+r+1 >> 1;
if(check2(mid,a)) l = mid;
else r = mid-1;
}
ll ans2 = l;
cout << ans1 - ans2 << endl;
}
int main() {
int T = 1; //fastio;
cin >> T;
while(T--){ sol(); }
return 0;
}
实数域二分
//一般实现为限制二分次数,或达到某个精度就停止
for(int ti = 1;ti <= 100;ti++){
double mid = (l + r) / 2;
if(check(mid)) r = mid;
else l = mid;
}
std::cout << l << '\n';
//例如:求一个数的开三次方
const double eps = 1e-8;
double n;cin >> n;
double l = -10000,r = 10000;
while(r-l >= eps){
double mid = (l+r)/2;
if(mid*mid*mid >= n) r = mid;
else l = mid;
}
printf("%.6lf",r);
分数规划
分数规划用来求一个分式的极值。 每种物品有两个权值ai和bi,求一组w$\in${0,1},选出若干个物品使得$\frac{\sum_{i=1}^naiwi}{\sum_{i=1}^nbiwi}$最小/最大。 一般分数规划问题还会有一些奇怪的限制,比如『分母至少为k』。
假如我们要求最大值,二分check一个mid,然后推柿子 $\frac{\sum aiwi}{\sum biwi} > mid$ ==>$\sum aiwi - mid * \sum biwi > 0$ ==>$\sum wi(ai-midbi) > 0$ //诺不等式大于0说明mid可行
主要难点在于如何求$\sum wi(ai-midbi)$的最大值/最小值
//https://vjudge.net/problem/POJ-2976#author=0
//n门课至少选k门,使得平均学分最大
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
const int N = 1003;
int n,k;
vector<double>a(N),b(N);
bool cmp(double x,double y){
return x > y;
}
bool check(double mid){//判断是否存在k个物品,其累计平均分>mid
double s = 0;
vector<double>c(n);
for(int i = 0;i < n;i++){
c[i] = a[i]-mid*b[i];//把c[i] = a[i]-mid*b[i]作为第i个物品的权值
}
sort(c.begin(),c.begin()+n,cmp);
for(int i = 0;i < k;i++){
s+=c[i];//贪心地选择权值最大的k个
}
return s > 0;
}
void uuz(){
for(int i = 0;i < n;i++){cin >> a[i];}
for(int i = 0;i < n;i++){cin >> b[i];}
double l = 0,r = 1e9;
while(r-l > 1e-6){
double mid = (l+r)/2;
//cout << mid << endl;
if(check(mid)) l = mid;
else r = mid;
}
int ans = r*100;
cout << ans+(r*100-ans >= 0.5) << endl;
}
int main(){
while(cin >> n >> k,n||k){
k = n-k;
uuz();
}
}
子段和问题
无长度限制
求一个子段,它的和最大,没有“长度大于等于F”这个限制 无长度限制的最大子段和问题是一个经典问题,只需要O(n)扫描该序列,不断 地把新数加入子段,当子段和变为负数的时候,就把当前整个子段清空。扫描过程 中出现过的最大的子段和即为所求
区间[l,r]的最大子段和:详见线段树
有长度限制
求一个子段,他的和最大,长度不超过k:135. 最大子段和
详见 单调队列优化
求一个子段,他的和最大,长度不小于k:
子段可以转化为前缀和相减的形式,则有
\[\max_{i-j>=k}\{A_{j+1}+A_{j+2}+...+A_i\} = \max_{k<=i<=n}\{sum_i-\min_{0<=j<=i-k}\{sum_j\}\}\]
//最佳牛围栏:https://www.acwing.com/problem/content/104/
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
const int N = 100005;
int n,f;
int a[N];
double s[N];
bool check(double mid){//判断是否存在连续子段(长度>=f),其最大平均数max_avg >= 当前mid
for(int i = 1;i <= n;i++){//相当于判断是否存在 max_avg - mid >= 0
s[i] = s[i-1]+(a[i] - mid);//a[i]-mid 的前缀和
}
double avg = 0;
for(int i = f;i <= n;i++){
avg = min(avg,s[i-f]);
if(s[i]-avg >= 0) return 1;//诺s[i]-mins >= 0,说明存在子段其平均数>mid
}
return 0;
}
int main(){
cin >> n >> f;
for(int i = 1;i <= n;i++){cin >> a[i];}
double l = 0,r = 2000;
while(r-l > 1e-6){
double mid = (l+r)/2;
if(check(mid)) l = mid;//将问题转变为判定问题
else r = mid;
}
r*=1000;//r为结果
cout << (int)r << endl;
}
三分
如果需要求出单峰函数的极值点,通常使用二分法衍生出的三分法求单峰函数的极值点
三分法每次操作会舍去两侧区间中的其中一个。为减少三分法的操作次数,应使两侧区间尽可能大。因此,每一次操作时的 $lmid$ 和 $rmid$ 分别取 $mid-\varepsilon$ 和 $mid+\varepsilon$ 是一个不错的选择。
//https://www.luogu.com.cn/problem/P3382
//给出一个N次函数,保证在范围[𝑙,𝑟]内存在一点𝑥,使得[l,𝑥]上单调增,[𝑥,𝑟]上单调减。试求出𝑥的值。
#include <iostream>
#include <cmath>
using namespace std;
const int N = 20;
const double eps = 1e-7;
int n;
double l,r,a[N];
double f(double x){
double ans = 0;
for(int i = n;i >= 0;i--){
ans+=a[i]*powl(x,i);
}
return ans;
}
int main(){
cin >> n >> l >> r;
for(int i = n;i >= 0;i--){ cin >> a[i]; }
while(r-l > eps){
double mid = (l+r)/2;
double lmid = mid - eps;
double rmid = mid + eps;
if(f(lmid) > f(rmid)) r = mid;//诺要求凹函数峰值,把符号换成 < 即可
else l = mid;
}
printf("%.6lf",l);
return 0;
}
双指针
for(int i = 0,j = 0;i < n;i++){ while(j < i && check[i] [j]) { j++; //每道题的逻辑 } } 可以将O(n^2)优化到O(n);
//最长连续无重复子序列
#include <iostream>
using namespace std;
const int N = 1000006;
int a[N], s[N];//s[a[i]]判断a[i]出现的次数
int n, res;
int main() {
cin >> n;
for (int i = 0;i < n;i++)
cin >> a[i];
for (int i = 0,j = 0;i < n;i++){
s[a[i]] ++;
while (s[a[i]] > 1) {
//当右端点i的数出现次数>1,s[a[j]]--,左端点j右移
s[a[j]]--;
j++;
}
res = max(res, i - j + 1);
}
cout << res << endl;
return 0;
}
排序
sort
需包含头文件
平均复杂度为O(NlogN),不保证稳定性
语法:sort(begin, end, cmp);
其中begin为指向待sort()的数组的
第一个元素的指针,end为指向待sort()的数组的最后一个元素的下一个位置的指针,cmp参数为排序准则(不写默认从小到大进行排序);
//默认从小到大:
sort(arr, arr+n);//数组下标从0开始
sort(arr+1,arr+n+1)//数组下标从1开始
sort(v.begin(),v.end());
//从大到小:
sort(str.begin(),str.end(),greater<int>());
sort(str.rbegin(),str.rend());
sort(str.begin(),str.end(),cmp);//bool cmp(int a,int b){return a > b;}以a,b大小为依据排序
//返回值为真,则a排在b前面
sort(e+1,e+n+1,[](auto &x,auto &y){return x.a > y.b;});//lambda表达式,结构体数组以a为权重排序
stable_sort()
stable_sort() 也是一种O(n log n)时间复杂度的排序算法,但它保证稳定性,即相等的元素将保持其原始顺序。这使得它在需要保持相等元素顺序的场景中很有用。注意,稳定排序的代价是额外的空间复杂度。
快速排序
不稳定
快速排序的最优时间复杂度和平均时间复杂度为 $O(n\log n)$,最坏时间复杂度为 $O(n^2)$。
#include<iostream>
using namespace std;
const int N = 1e6 + 5;
int n;
int q[N];
void quick_sort(int q[], int l, int r) {
if (l >= r) return;
int x = q[l], i = l - 1, j = r + 1;
while (i < j) {
do i++; while (q[i] < x);
do j--; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j); //注意边界问题
quick_sort(q, j + 1, r);
}
int main() {
scanf("%d", &n);
for (int i = 0; i < n; i++) scanf("%d", &q[i]);
quick_sort(q, 0, n - 1);
for (int i = 0; i < n; i++)printf("%d", q[i]);
}
第k小的数
//https://www.luogu.com.cn/problem/P1923
//k从第0小开始,诺要从1开始则++k即可,时间复杂度O(N)
#include<iostream>
using namespace std;
const int N = 5e6 + 5;
int n,k;
int q[N];
void quick_sort(int q[], int l, int r) {
if (l >= r) return;
int x = q[l], i = l - 1, j = r + 1;
while (i < j) {
do i++; while (q[i] < x);
do j--; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
if(k <= j)quick_sort(q, l, j);//每次判断条件,只需排一边
else quick_sort(q, j + 1, r);
}
int main() {
scanf("%d %d", &n,&k);
for (int i = 0; i < n; i++) scanf("%d", &q[i]);
quick_sort(q, 0, n - 1);
//stl函数实现了类似功能:nth_element(q,q+k,q+n);
//诺下标从1开始:++k; nth_element(a+1,a+k,a+n+1);
cout << q[k];
}
归并排序
稳定
时间复杂度在最优、最坏与平均情况下均为 $\Theta (n \log n)$,空间复杂度为 $\Theta (n)$。
先排左半边,再排右半边,最后合并。
void merge_sort(int q[], int l, int r){
//递归的终止条件
if(l >= r) return;
//第一步:分成子问题
int mid = l + r >> 1;
//第二步:递归处理子问题
merge_sort(q, l, mid ), merge_sort(q, mid + 1, r);
//第三步:合并子问题
int i = l, j = mid + 1, k = 0, tmp[r - l + 1];
while(i <= mid && j <= r){
if(q[i] <= q[j]) tmp[k++] = q[i++];
else tmp[k++] = q[j++];
}
while(i <= mid) tmp[k++] = q[i++];
while(j <= r) tmp[k++] = q[j++];
for(k = 0, i = l; i <= r; k++, i++) q[i] = tmp[k];
}
逆序对
//https://www.luogu.com.cn/problem/P1908
//O(NlogN)归并排序求逆序对数量、冒泡排序需要交换的次数
//也可离散化后用树状数组或线段树求逆序对
#include <iostream>
using namespace std;
const int N = 500005;
int n,a[N];
long long ans;
void merge_sort(int a[],int l,int r){
if(l == r) return;
int mid = l + r >> 1;
merge_sort(a,l,mid);merge_sort(a,mid+1,r);
int i = l,j = mid+1,t[r-l+1],k = 0;
while(i <= mid && j <= r){
if(a[i] <= a[j]) t[k++] = a[i++];
else t[k++] = a[j++],ans += mid-i+1;//核心代码
}
while(i <= mid) t[k++] = a[i++];
while(j <= r) t[k++] = a[j++];
for(k = 0,i = l;i <= r;k++,i++){
a[i] = t[k];
}
}
int main(){
cin >> n;
for(int i = 1;i <= n;i++){ scanf("%d",&a[i]); }
merge_sort(a,1,n);
cout << ans;
}
//奇数码问题 https://www.acwing.com/problem/content/110/
//n*n (n为奇数) 二维按行化为一维(不包括0),归并排序1 ~ n*n-1求逆序对数量;
//诺两个数码逆序对奇偶性相同则可以转变。
对于一个排列,交换任意两个元素的位置,必然改变逆序对奇偶性。
分治
就是把一个复杂的问题分成两个或更多的相同或相似的子问题,直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
大概的流程可以分为三步:分解 -> 解决 -> 合并。
- 分解原问题为结构相同的子问题。
- 分解到某个容易求解的边界之后,进行递归求解。
- 将子问题的解合并成原问题的解。
分治法能解决的问题一般有如下特征:
- 该问题的规模缩小到一定的程度就可以容易地解决。
- 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质,利用该问题分解出的子问题的解可以合并为该问题的解。
- 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子问题。
P7883 平面最近点对(加强加强版) - 洛谷 (luogu.com.cn)
给定平面内n个点对p(x,y),求距离最近的两个点的距离(的平方)。由于输入的点为整点,因此这个值一定是整数。
将所有点排序后,将整个区间一分为二,分别递归处理,$d = min(sol(S1),sol(S2))$,再处理两个区间交界范围的点,假设当前交界点x坐标为midx,我们只需要处理$x\in[midx-d,midx+d]$范围内的点即可。将这个区域的点按照y坐标升序排列,然后二重循环枚举$(p_i,p_j)$,$d = min(d,dist(p_i,p_j))$,如果当前两个点之间的$\Delta y$ >= d,则可以停止枚举第二个点。
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 400005;
int b[N];
struct node{
long long x,y;
bool operator < (const node& e2){
return x != e2.x ? x < e2.x : y < e2.y;
}
}a[N];
long long pow2(long long x) {return x*x;}
long long dist(node p1,node p2){
return pow2(p1.x-p2.x) + pow2(p1.y-p2.y);
}
void merge(int l,int r){
int mid = l + r >> 1;
int i = l,j = mid+1,k = 0;
node temp[r-l+1];
while(i <= mid && j <= r){
if(a[i].y < a[j].y) temp[k++] = a[i++];
else temp[k++] = a[j++];
}
while(i <= mid) temp[k++] = a[i++];
while(j <= r) temp[k++] = a[j++];
for(i = l,k = 0;i <= r;i++,k++){
a[i] = temp[k];
}
}
long long sol(int l,int r){
if(l >= r) return 8e18;
if(l+1 == r){//边界:当前区间仅有两个点,直接计算即可。
merge(l,r);
return dist(a[l],a[r]);
}
int mid = l + r >> 1;
long long midx = a[mid].x,cnt = 0;//因为合并时a[mid]会变,需要提前记录
long long d = min(sol(l,mid),sol(mid+1,r));
merge(l,r);
for(int i = l;i <= r;i++){
if(pow2(a[i].x - midx) < d){
b[++cnt] = i;
}
}
for(int i = 1;i <= cnt;i++){
for(int j = i+1;j <= cnt && pow2(a[b[i]].y - a[b[j]].y) < d;j++){
d = min(d,dist(a[b[i]],a[b[j]]));
}
}
return d;
}
int main(){
int n;cin >> n;
for(int i = 1;i <= n;i++){
cin >> a[i].x >> a[i].y;
}
sort(a+1,a+n+1);
cout << sol(1,n);
// printf("%.4lf",sqrt(sol(1,n)));
}
二进制
//求n的二进制第k位 从0开始数
#include <iostream>
using namespace std;
//10 = (1010)2
int main() {
int n, k;
cin >> n >> k;
cout << (n >> k & 1); //右k移位,再&1,k的值不会改变
return 0;
}
lowbit
求n的二进制 第一次出现的1对应的值:
368: n = 1011==1==0000 -n = 010001111 -n+1 = 0100==1==0000 //以补码形式储存 n&-n = 10000 = 16
int lowbit(int n) {return n&-n;}
lowbit的应用:
//求n的二进制中出现了多少个1
int lowbit(int n) { return n & -n; }
int main() {
int n,res = 0;cin >> n;
while (n) {
n -= lowbit(n);
res++;
}
cout << res << endl;
}
//判断一个数是不是2的倍数
int lowbit(int n) {return n&-n;}
int main(){
if(n == lowbit(n)) "yes"
else "no"
}
求正整数n的二进制长度
$(100101)_2 = 6$
int len = log2(n)+1;
求正整数n的二进制第k位代表的十进制数($2^k$或0)
long long deg(long long num, int deg) { return num & (1LL << deg); }
//25 = {1,0,0,8,16}
状态压缩
用二进制表示状态 例如,a[ ] = {1,2,3,4,5,6,7,8}; 则v[22]表示10110 = a[5]+a[3]+a[2]
const int N = 1 << 10;
int a[] = {1,2,3,4,5,6,7,8};
for(int i = 1;i < 1 << 10;i++){
for(int k = 0;k < 10;k++){
if(i >> k & 1) v[i]+=a[k];
}
}
//费解的5*5开关:https://www.acwing.com/problem/content/97/
//先固定第一行状态(暴力枚举00000~11111),每一行的暗灯都由下面一行去点亮,此时已经固定了当前状态的最终答案
//再枚举第i=(2,3,4,5)行,诺第a[i-1][j]为0,则需要turn[i][j]开关,统计能否点亮所有灯和turn的次数即可
#include <iostream>
#include <cstring>
using namespace std;
const int N = 7;
bool a[N][N],b[N][N];
int di[] = {0,-1,1,0,0},dj[] = {0,0,0,-1,1};
int cnt,ans;
void turn(int i,int j){
for(int w = 0;w < 5;w++){
int x = i + di[w],y = j + dj[w];
if(x >= 1 && x <= 5 && y >= 1 && y <= 5){
if(a[x][y]){cnt--;}
else {cnt++;}
a[x][y]^=1;
}
}
}
void sol(){
ans = 0x3f3f3f3f,cnt = 0;
for(int i = 1;i <= 5;i++){
string s;cin >> s;
for(int j = 1;j <= 5;j++){
a[i][j] = s[j-1] - '0';
if(a[i][j]) cnt++;
}
}
memcpy(b,a,sizeof b);
int temp = cnt;
for(int q = 0;q < 1 << 5;q++){//q表示第一行状态,从00000~11111
cnt = temp;//cnt统计亮灯的个数
int step = 0;//step记录开关操作次数
for(int k = 0;k < 5;k++){
if(q >> k & 1){ step++;turn(1,k+1); }
}//用当前状态q固定第一行
for(int i = 2;i <= 5;i++){//枚举第2~5行
if(step > 6) break;
for(int j = 1;j <= 5;j++){
if(a[i-1][j] == 0){ step++; turn(i,j); }//每一行的暗灯都由下面一行去点亮
if(cnt == 25){ans = min(ans,step);}//更新答案
}
}
memcpy(a,b,sizeof a);//还原数组a
}
if(ans > 6) cout << -1 << endl;
else cout << ans << endl;
}
int main(){
int tt; cin >> tt;
while(tt--) {sol();}
return 0;
}
位运算
a+b = a|b + a&b = a^b + (a&b)*2
^ 异或
相同为0,不同为1,可以看做不进位加法
0^0 = 01^0 = 10^1 = 11^1 = 0
A ^ A = 0A ^ 0 = Aa ^ b ^ b = a自反性a ^ b ^ c ^ d = b ^ d ^ a ^ c无序性a^b = c可移项为a = b^c,移项时无需改变符号
如果i为偶数,则有
i^(i+1) = 1
比较两数值是否同号,
a^b > 0替换掉a*b > 0
a ^= b ^= a ^= b相当于swap(a,b)
判断成对的数中只出现一次的数
//给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现**两次**。找出那个只出现了一次的元素。
int ans = 0;
for(int i = 1;i <= n;i++) {ans ^= a[i];}
cout << ans;
异或前缀和
for(int i = 1;i <= n;i++){
s[i] = s[i-1]^a[i];
}
int query(int l,int r){
return s[r]^s[l-1];
}
如果
(n-1)%4 == 0,则0~n-1的异或前缀和为0,S[0,3,7,11,15...] = 0
& 与
判断奇偶
int n;cin >> n;
if(n&1) //则为奇数
» 移位
n » k 相当于 $n/2^k$
n « k 相当于 $n\times 2^k$
//十进制转二进制
int n; cin >> n;//32位
for (int i = 31; i >= 0;i--) {
cout << (n >> i & (1));
}
离散化
数组下标跨度长,但只用到了部分下标
vector<int>arr; //储存所有待离散化的值
sort(arr.begin(),arr.end()); //将所有值排序
arr.erase(unique(arr.begin(),arr.end()),arr.end()); //去掉重复元素
int find(int x){
return lower_bound(arr.begin(),arr.end(),x)-arr.begin()+1;//加1从下标为1开始映射,不加则从0开始
}
for(int i = 1;i <= n;i++){
cin >> a[i];
hs[i] = a[i];
}
sort(hs+1,hs+n+1);
int m = unique(hs+1,hs+n+1) - hs - 1;//a[1~m]即为去重后的元素(离散至1~m(<=n)),不去重也没关系(离散至1~n)
for(int i = 1;i <= n;i++){
a[i] = lower_bound(hs+1,hs+m+1,a[i]) - hs + 1;//a[i]即为离散后的数值,hs[a[i]]为a[i]原来的值
}
部分涉及区间染色的题目,对于区间[l,r]离散化时,需要将[l-1,r-1]也一起加入离散化数组并去重,否则可能出现以下情况:例如用区间[1,3]和[6,10]覆盖区间[1,10]时,常规离散化会导致[1,10]整个区间被覆盖。例题:[P3740 HAOI2014] 贴海报 - 洛谷 (luogu.com.cn)
搜索
DFS
深度优先搜索,递归实现
在深度优先搜索中,对于最新发现的顶点,如果它还有以此为顶点而未探测到的边,就沿此边继续探测下去,当顶点v的所有边都已被探寻过后,搜索将回溯到发现顶点v有起始点的那些边。这一过程一直进行到已发现从源顶点可达的所有顶点为止。如果还存在未被发现的顶点,则选择其中一个作为源顶点,并重复上述过程。整个过程反复进行,直到所有的顶点都被发现时为止。
括号序列
//按字典序输出长度为n的所有合法括号序列 1 <= n <= 20
//https://vjudge.net/problem/AtCoder-typical90_b#author=DeepSeek_zh
#include <iostream>
using namespace std;
int n;
void dfs(string s,int l,int r){//当前序列为s,且用了l个左括号的r个右括号
if(l == n && r == n){
cout << s << '\n';
return ;
}
if(l < n) dfs(s+'(',l+1,r);
if(r < l) dfs(s+')',l,r+1);//对于所有位置i而言,其左括号的数量>=右括号的数量
}
int main(){
cin >> n;
if(n&1) return 0;
n/=2;
dfs("",0,0);
}
全排列
//n选m的全排列,标记数组写法
void dfs(int cnt){//dfs(1)
if(cnt > m){
for(int i = 1;i <= m;i++){
cout << path[i] << ' ';
}
cout << '\n';
return;
}
for(int i = 1;i <= n;i++){
if(!st[i]){
path[cnt] = i;
st[i] = 1;
dfs(cnt+1);
st[i] = 0;
}
}
}
//n选m的全排列,u表示二进制状态替换标记数组
void dfs(int u,int cnt){//dfs(1,1)
if(cnt > m){
for(int i = 1;i <= m;i++){
cout << path[i] << ' ';
}
cout << '\n';
return;
}
for(int i = 1;i <= n;i++){
if(u>>i&1) continue;
path[cnt] = i;
dfs(u|1<<i,cnt+1);
}
}
//n选m的全组合
void dfs(int u,int cnt){//dfs(1,1)
if(cnt > m){
for(int i = 1;i <= m;i++){
cout << path[i] << ' ';
}
cout << '\n';
return;
}
for(int i = u;i <= n;i++){
path[cnt] = i;
dfs(i+1,cnt+1);
}
}
//n选m的全排列&全组合(1~n)
//(t.path[]可以从任意合法排列开始)
#include <iostream>
#include <vector>
using namespace std;
struct PC{//PC t(n,m); 1_idx
int n,m;
vector<int>path;
PC(int n,int m){
this->n = n;this->m = m;
path.resize(n+1);
for(int i = 1;i <= n;i++) path[i] = i;
}
bool next_comb(){
int j = m;
while (j >= 1 && path[j] == n - m + j) j--;
if (j == 0) return 0;
path[j]++;
for (int i = j + 1; i <= m; i++) path[i] = path[i - 1] + 1;
return 1;
}
bool next_perm(){
for (int i = m,used = 0; i >= 1; i--,used = 0) {
for (int j = 1; j < i; ++j) used |= 1 << path[j];
for (int x = path[i]+1;x <= n;x++){
if((used >> x & 1)) continue;
path[i] = x; used = ~ (used | 1 << x) ^ 1;
for(int j = i+1;j <= m;j++){
int w = __builtin_ctz(used);
path[j] = w;
used ^= 1 << w;
}
return 1;
}
}
return 0;
}
};
int main(){
int n,m; cin >> n >> m;
PC t(n,m);//初始化
do{
for(int i = 1;i <= t.m;i++){
cout << t.path[i] << ' ';
}
cout << '\n';
}while(t.next_perm());
}
剪枝
优化搜索顺序
搜索前排序,减小搜索规模、优先搜索分支较少的节点
排除等效冗余
如果沿着几条不同分支到达的子树是等效的,那么只需要对其中一条分支进行搜索
可行性剪枝 (上下界剪枝)
对当前状态进行检查,如果当前分支已经无法到达递归的边界,就进行回溯
最优化剪枝
在最优化问题的搜索过程中,如果当前花费的代价超过了已经搜到的最优解,此时可以停止搜索,直接回溯
记忆化
记录每个状态的搜索结果,在重复遍历一个状态时直接检索并返回
其它优化
使用数据结构、状态压缩、位运算等优化
//导弹防御系统 https://www.luogu.com.cn/problem/P10490
//dfs+剪枝+全局最小值
#include <iostream>
using namespace std;
const int N = 55;
int n;
int arr[N];
int up[N],down[N];
int ans;
void dfs(int u,int su,int sd){//前u个导弹,已经使用su个up系统,sd个down系统
if(su + sd >= ans) return;//如果已经超过了当前最优答案,直接剪枝
if(u == n){ans = su + sd;return;}//所有导弹都考虑过了,并且没有超过当前最优答案,则更新最优答案
//方案一:使用up系统拦截第u个导弹
int i = 0;
while(i < su && up[i] >= arr[u]) i++;//贪心找到当前低于u导弹的最高的up系统i (up[]为降序数组)
int temp = up[i];//temp用于回溯时恢复现场
up[i] = arr[u];
if(i >= su)dfs(u+1,su+1,sd);//诺i没找到则新建一个up系统拦截
else dfs(u+1,su,sd);//否则使用原来的up系统拦截
up[i] = temp;//恢复现场
//方案二:使用down系统拦截第u个导弹
i = 0;
while(i < sd && down[i] <= arr[u]) i++;
temp = down[i];
down[i] = arr[u];
if(i >= sd)dfs(u+1,su,sd+1);
else dfs(u+1,su,sd);
down[i] = temp;
}
int main(){
while(cin >> n,n){
ans = n;
for(int i = 0;i < n;i++){ cin >> arr[i]; }
dfs(0,0,0);
cout << ans <<endl;
}
}
//数独 https://www.luogu.com.cn/problem/P10481
#include <iostream>
using namespace std;
const int N = 9,M = 1 << N;
int a[N][N];
int mp[M];//预处理每个lowbit对应的数
int ones[M];//预处理每个状态可填的数,优先搜索分支最小的状态
int sx[N],sy[N],sz[N];//状态压缩,表示每行、每列、每块方格还能填的数
int get(int x,int y){
return sx[x]&sy[y]&sz[x/3*3+y/3];
}
bool dfs(int cnt){
if(!cnt) return 1;
int mn = 10;
int x,y;
for(int i = 0;i < N;i++){//优先找分支较少的进行拓展
for(int j = 0;j < N;j++){
if(a[i][j] == 0){
int now = ones[get(i,j)];
if(now < mn){
mn = now;
x = i,y = j;
}
}
}
}
for(int i = get(x,y);i;i -= i&-i){
int k = mp[i&-i];
a[x][y] = k+1;
sx[x] ^= 1 << k;
sy[y] ^= 1 << k;
sz[x/3*3+y/3] ^= 1 << k;
if(dfs(cnt-1)) return 1;
a[x][y] = 0;
sx[x] ^= 1 << k;
sy[y] ^= 1 << k;
sz[x/3*3+y/3] ^= 1 << k;
}
return 0;
}
void sol(){
for(int i = 0;i < N;i++) sx[i] = sy[i] = sz[i] = (1<<N)-1;
int cnt = 0;
for(int i = 0;i < N;i++){
for(int j = 0;j < N;j++){
if(a[i][j]){
int k = a[i][j]-1;
sx[i] ^= 1 << k;
sy[j] ^= 1 << k;
sz[i/3*3+j/3] ^= 1 << k;
}
else cnt++;
}
}
dfs(cnt);
}
int main(){
for(int i = 0;i < N;i++) mp[1<<i] = i;
for(int i = 0;i < 1 << N;i++){
for(int j = i;j;j -= j&-j){
ones[i]++;
}
}
int mt;cin >> mt;
while(mt--) {
for(int i = 0;i < N;i++){
string s;cin >> s;
for(int j = 0;j < N;j++){
char x = s[j];
if(x == '.') a[i][j] = 0;
else a[i][j] = x - '0';
}
}
sol();
for(int i = 0;i < N;i++){
for(int j = 0;j < N;j++){
cout << a[i][j];
}cout << '\n';
}
}
}
迭代加深
即每次限制搜索深度的深度优先搜索。
迭代加深搜索的本质还是深度优先搜索,只不过在搜索的同时带上了一个深度  ,当 达到设定的深度时就返回,一般用于找最优解。如果一次搜索没有找到合法的解,就让设定的深度加一,重新从根开始。
,当 达到设定的深度时就返回,一般用于找最优解。如果一次搜索没有找到合法的解,就让设定的深度加一,重新从根开始。
当状态随着深度增加比较多时,BFS队列的空间复杂度会很大。当BFS在空间上不够优秀,而且问题要找最优解时,应该考虑迭代加深搜索,迭代加深也可以近似看做BFS。
过程
首先设定一个较小的深度作为全局变量,进行 DFS。每进入一次 DFS,将当前深度加一,当发现 $d$ 大于设定的深度 $\textit{limit}$ 就返回。如果在搜索的途中发现了答案就可以回溯,同时在回溯的过程中可以记录路径。如果没有发现答案,就返回到函数入口,增加设定深度,继续搜索。
IDDFS(u,d)
if (d > limit) return
for each edge (u,v){
IDDFS(v,d+1)
}
return
BFS
广度优先搜索,队列实现,求最短路径
每次都尝试访问同一层的节点。 如果同一层都访问完了,再访问下一层。
//走迷宫 https://www.acwing.com/problem/content/description/846/
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int N = 110;
int n,m;
int g[N][N];//存图
int d[N][N];//存点到起点的距离
queue<pair<int, int>>q;//队列实现
int dfs() {
memset(d, -1, sizeof d);//初始化为-1表示没有走过
q.push({ 0,0 });//表示起点走过了
d[0][0] = 0;
int dx[4] = { -1,1,0,0 }, dy[4] = { 0,0,-1,1 };
while (q.size()) {//队列不为空
auto t = q.front();//取队头
q.pop();
for (int i = 0; i < 4;i++) {//枚举四个方向,扩展t
int x = t.first + dx[i], y = t.second + dy[i];
if (x >= 0 && x < n && y >= 0 && y < m && d[x][y] == -1 && g[x][y] == 0) {
//在边界内 是空地 且之前没有走过
d[x][y] = d[t.first][t.second] + 1;//则到起点的距离+1
q.push({ x,y });//新坐标入队
}
}
}
return d[n - 1][m - 1];
}
int main() {
cin >> n >> m;
for (int i = 0; i < n;i++) {
for (int j = 0; j < m;j++) {
cin >> g[i][j];
}
}
cout << dfs();
}
双端队列BFS
时间复杂度为严格的O(N+M)
对于一张边权为0或1的无向图。搜索时如果边权为0则将该新节点从队头入队,如果为1则从队尾入队
//电车 https://www.acwing.com/problem/content/4252/
#include <iostream>
#include <cstring>
#include <deque>
const int N = 105,M = N*N;
int n,s,t;
int h[N],e[M],ne[M],w[M],idx;
int dist[N];
bool vis[N];
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void uuz(){
std::memset(dist,0x3f,sizeof dist);
std::deque<int>dq;
dq.push_back(s);
dist[s] = 0;
while(dq.size()){
int x = dq.front();
dq.pop_front();
if(x == t) return;
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(dist[y] > dist[x] + w[i]){
dist[y] = dist[x] + w[i];
if(w[i] == 0) { dq.push_front(y); }
else { dq.push_back(y); }
}
}
}
}
int main(){
std::memset(h,-1,sizeof h);
std::cin >> n >> s >> t;
for(int i = 1;i <= n;i++){
int k;
std::cin >> k;
for(int j = 1;j <= k;j++){
int x;std::cin >> x;
if(j == 1) add(i,x,0);
else add(i,x,1);
}
}
uuz();
if(dist[t] == 0x3f3f3f3f) std::cout << -1;
else std::cout << dist[t];
}
[P1948 USACO08JAN] Telephone Lines S - 洛谷 (luogu.com.cn)
求出一条路径,使点1到n中第k+1长的边最短,输出这条边的长度。 二分一个答案x,搜索时诺当前w > x则权值看作1,代表由通信公司免费报销。 诺最终需要报销的边数 <= k 则说明当前 x 符合条件。
#include <iostream>
#include <cstring>
#include <deque>
using namespace std;
const int N = 1003,M = 20004;
int n,m,k;
int h[N],e[M],ne[M],w[M],idx;
int dist[N];
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
bool check(int x){
memset(dist,0x3f,sizeof dist);
dist[1] = 0;
deque<int>q;
q.push_back(1);
while(q.size()){
int t = q.front();
q.pop_front();
for(int i = h[t];~i;i = ne[i]){
int k = e[i];
int val = w[i] > x ? 1 : 0;
if(dist[k] > dist[t] + val){
dist[k] = dist[t] + val;
if(val) q.push_back(k);
else q.push_front(k);
}
}
}
return dist[n] <= k;
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m >> k;
for(int i = 1;i <= m;i++){
int a,b,c;cin >> a >> b >> c;
add(a,b,c);add(b,a,c);
}
int l = 0,r = 1e6;
while(l < r){
int mid = l + r >> 1;
if(check(mid)) r = mid;
else l = mid + 1;
}
if(dist[n] == 0x3f3f3f3f) cout << -1;
else cout << l;
}
Maze Challenge with Lack of Sleep(★4) - AtCoder typical90_aq - Virtual Judge (vjudge.net)
给定一个N*M的网格,
#代表障碍,.代表路径,求从起点(rs,cs)到终点(rt,ct),最少转向次数。
设定状态(x,y,dir)表示当前位置为(x,y),方向为dir,拓展到下一个节点(nx,ny,i)时,如果dir与i方向一致,则入队首,否则入队尾。
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int N = 1003;
int n,m,rs,cs,rt,ct;
string s[N];
int dx[] = {-1,0,1,0},dy[] = {0,1,0,-1};
int dist[N][N][4];
int ans = 0x3f3f3f3f;
struct node{
int x,y,dir;
};
void uuz(){
memset(dist,0x3f,sizeof dist);
deque<node>q;
for(int i = 0;i < 4;i++){
q.push_back(node{rs,cs,i});
dist[rs][cs][i] = 0;
}
while(q.size()){
auto [x,y,dir] = q.front();
q.pop_front();
if(x == rt && y == ct) ans = min(ans,dist[x][y][dir]);
for(int i = 0;i < 4;i++){
int nx = x + dx[i],ny = y + dy[i];
if(nx < 1 || nx > n || ny < 1 || ny > m || s[nx][ny] == '#') continue;
if(dist[nx][ny][i] > dist[x][y][dir] + (i != dir)){
dist[nx][ny][i] = dist[x][y][dir] + (i != dir);
if(i == dir)q.push_front(node{nx,ny,i});
else q.push_back(node{nx,ny,i});
}
}
}
}
int main(){
cin >> n >> m;
cin >> rs >> cs >> rt >> ct;
for(int i = 1;i <= n;i++){
cin >> s[i];s[i] = ' ' + s[i];
}
uuz();
cout << ans;
}
优先队列BFS
每次从队列中取出当前代价状态最小的进行扩展,当每个状态第一次从队列中被取出时,就得到了起点到该状态的最小状态,之后再被取出时则可直接忽略。
UVA11367 Full Tank? - 洛谷 (luogu.com.cn)
有N个城市M条无向边,每个城市都有一个加油站,加每单位油花费p[i]。 回答q次询问,每次给定油箱容量为c,起始点为st,终点为ed。求st到ed的最小花费?
#include <iostream>
#include <vector>
#include <cstring>
#include <queue>
using namespace std;
const int N = 1003,M = 20004;
int n,m,q;
int p[N];
int h[N],e[M],ne[M],w[M],idx;
struct node{
int x,oil,cost;
bool operator < (const node &e2)const{
return cost > e2.cost;//小根堆,cost小的在堆顶,每次用花费最小的进行拓展,类似dijkstra
}
};
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void query(){
int c,st,ed;cin >> c >> st >> ed;//dist[x][oil]表示当前位于点x,油量为oil的最小花费
vector<vector<int>>dist(n+2,vector<int>(c+2,0x3f3f3f3f)),vis(n+2,vector<int>(c+2));
priority_queue<node>pq;
pq.push({st,0,0});
dist[st][0] = 0;
while(pq.size()){
auto [x,oil,cost] = pq.top();
pq.pop();
if(x == ed){cout << cost << '\n';return;}
if(oil < c){//诺油量没满,则可以选择原地不动加油
if(dist[x][oil+1] > dist[x][oil] + p[x]){
dist[x][oil+1] = dist[x][oil] + p[x];
pq.push({x,oil+1,dist[x][oil+1]});
}
}
for(int i = h[x];~i;i = ne[i]){
if(oil < w[i]) continue;//诺oil < w[i],则可以更新其它点
int y = e[i];
if(dist[y][oil-w[i]] > dist[x][oil]){
dist[y][oil-w[i]] = dist[x][oil];
pq.push({y,oil-w[i],dist[y][oil-w[i]]});
}
}
}
cout << "impossible\n";
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
for(int i = 0;i < n;i++) cin >> p[i];
for(int i = 1;i <= m;i++){
int a,b,c;cin >> a >> b >> c;
add(a,b,c);add(b,a,c);
}
cin >> q;
while(q--) query();
}
双向搜索
诺问题有明确的“初态”和“终态”,可以从两端同时进行BFS或DFS,在中间交汇,组成最终答案。
双向BFS
P10487 Nightmare II - 洛谷 (luogu.com.cn)
给定一个N*M的网格,“M”代表男孩每秒可以走3格,“G”代表女孩每秒可以走1格,“Z”代表鬼每秒拓展2格,“X”代表墙,求在不进入鬼的占领区的前提下,男孩和女孩能否会合,诺能则输出最短会合时间。
从起始状态和目标状态分别开始,两边轮流进行,每次各扩展一整层,当两边各自有一个状态发生重复时,就说明这两个搜索过程相遇了,就可以合并出起点到终点的最少步数。
#include <iostream>
#include <queue>
#include <vector>
using namespace std;
const int N = 805;
string s[N];
int dx[] = {-1,1,0,0},dy[] = {0,0,-1,1};
int sol(){
int n,m,time = 0;cin >> n >> m;
vector<pair<int,int>>z;
vector<vector<int>>vis1(n+5,vector<int>(m+5)),vis2(n+5,vector<int>(m+5));//分别表示男孩和女孩访问过点的状态,诺同时为1则说明相遇了。
queue<pair<int,int>>q1,q2;
auto check = [&](int x,int y,int time)->bool{//判断当前点是否合法(未进入鬼区)
auto dis = [&](int x1,int y1,int x2,int y2){
return abs(x1-x2) + abs(y1-y2);
};
for(int i = 0;i < 2;i++){
if(2*time >= dis(x,y,z[i].first,z[i].second)) return 0;
}
return 1;
};
for(int i = 1;i <= n;i++){
cin >> s[i];s[i] = ' ' + s[i];
for(int j = 1;j <= m;j++){
if(s[i][j] == 'M') {q1.push({i,j});vis1[i][j] = 1;}
if(s[i][j] == 'G') {q2.push({i,j});vis2[i][j] = 1;}
if(s[i][j] == 'Z') z.push_back({i,j});
}
}
while(q1.size() || q2.size()){
time++;
for(int t = 1;t <= 3;t++){//q1每次拓展3层
int siz = q1.size();
while(siz--){
auto [x,y] = q1.front();
q1.pop();
if(!check(x,y,time)) continue;
for(int i = 0;i < 4;i++){
int nx = x + dx[i],ny = y + dy[i];
if(nx < 1 || nx > n || ny < 1 || ny > m || s[nx][ny] == 'X' || vis1[nx][ny]) continue;
if(vis2[nx][ny]) return time;
vis1[nx][ny] = 1;
q1.push({nx,ny});
}
}
}
for(int t = 1;t <= 1;t++){//q2每次拓展一层
int siz = q2.size();
while(siz--){
auto [x,y] = q2.front();
q2.pop();
if(!check(x,y,time)) continue;
for(int i = 0;i < 4;i++){
int nx = x + dx[i],ny = y + dy[i];
if(nx < 1 || nx > n || ny < 1 || ny > m || s[nx][ny] == 'X' || vis2[nx][ny]) continue;
if(vis1[nx][ny])return time;
vis2[nx][ny] = 1;
q2.push({nx,ny});
}
}
}
}
return -1;
}
int main(){
int t;cin >> t;
while(t--) cout << sol() << '\n';
}
双向DFS
P10484 送礼物 - 洛谷 (luogu.com.cn)
给定N个物品,每个物品体积为a[i],和一个容量为M背包,请问最多能装多少体积的物品? 其中$N \leqslant 45,1 \leqslant a[i],M \leqslant 2^{31-1}$
本题使用背包求解的话体积过大,指数型枚举的话复杂度过高$2^{45}$。
我们可以把礼物分成两半,对每一半分别搜索,将其能达到的体积分别存放于两个数组A,B中,对B数组进行排序,然后遍历A数组中的每一个元素x1,在B数组中二分找到x2,使得x1+x2 <= m,用二者之和更新答案。时间复杂度为$O(2^{\frac{n}{2}+1})$
#include <iostream>
#include <set>
#include <vector>
#include <algorithm>
using namespace std;
int n,m;
void dfs(vector<int>&v,vector<long long>&w,int id,long long sum){
if(sum > m) return;
if(id == v.size()){
w.emplace_back(sum);
return;
}
dfs(v,w,id+1,sum+v[id]);
dfs(v,w,id+1,sum);
}
int main(){
cin >> m >> n;
vector<int>v1,v2;
vector<long long>w1,w2;
int mid = (n+1)/2;
for(int i = 1;i <= mid;i++){
int x;cin >> x;
v1.emplace_back(x);
}
for(int i = mid+1;i <= n;i++){
int x;cin >> x;
v2.emplace_back(x);
}
dfs(v1,w1,0,0);
dfs(v2,w2,0,0);
sort(w2.begin(),w2.end());
long long ans = 0;
for(auto x1:w1){
auto x2 = --upper_bound(w2.begin(),w2.end(),m-x1);
ans = max(ans,x1+*x2);
}
cout << ans;
}
A*
为了提高搜索效率,我们设计一个“估价函数”,将“当前代价+未来估价”的最小状态作为堆顶进行拓展。 为了保证第一次从堆中取出目标状态时得到的就是最优解,我们设计的估价函数f(state)不能大于未来的实际代价g(state)。 这种带有估价函数的优先队列BFS就称为A*算法。
给定N个点,M条边的有向图,求从起点st到终点ed的第k短路(允许经过重复点或边)。
在优先队列BFS中,当节点x第k次被取出时,当前代价即为第k小代价。考虑A*优化。
- 我们以点x到终点ed的最短距离作为估价函数f(x),建反图以ed为起点求单源最短路即可求得f(x)。
- 建立二叉堆,存储二元组
(x,dist + f(x)),x表示当前节点,dist代表当前实际代价,f(x)表示预估代价。最初堆中只有(st,0+f(st)) - 从堆顶取出
dist + f(x)的最小二元组进行拓展,如果节点y被取出的次数尚未达到k次,就把新的二元组(y,(dist+w[i])+f(y))插入堆中。 - 重复3操作,直到终点ed被取出了k次,此时的dist即为从st到ed的第k短路。
A*算法的时间复杂度上界仍与优先队列BFS相同$O(K(N+M)log(N+M))$,不过由于估价函数的作用,图中很多节点访问的次数都远小于k,对于大多数数据,能比较快地求出结果,但能构造出数据,使得算法超时/超空间,正解应为可持久化可并堆做法。
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int N = 1003,M = 10004;
int n,m,st,ed,k;
int h[N],e[M],ne[M],w[M],idx;
int f[N];
int vis[N];
struct edge{
int a,b,c;
}in[M];
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dijkstra(){
memset(f,0x3f,sizeof f);
priority_queue<pair<int,int>,vector<pair<int,int>>,greater<pair<int,int>>>pq;
pq.push({0,ed});
f[ed] = 0;
while(pq.size()){
int x = pq.top().second;
pq.pop();
if(vis[x]) continue;
else vis[x] = 1;
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(f[y] > f[x] + w[i]){
f[y] = f[x] + w[i];
pq.push({f[y],y});
}
}
}
}
struct node{
int x,dist;
bool operator < (const node &e2)const{
return dist + f[x] > e2.dist + f[e2.x];
}
};
int astar(){
memset(vis,0,sizeof vis);
priority_queue<node>pq;
pq.push({st,0});
while(pq.size()){
auto [x,dist] = pq.top();
pq.pop();
vis[x]++;
if(vis[ed] == k) return dist;
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(vis[y] <= k) pq.push({y,dist+w[i]});
}
}
return -1;
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
for(int i = 1;i <= m;i++){
auto &[a,b,c] = in[i]; cin >> a >> b >> c;
add(b,a,c);
}
cin >> st >> ed >> k;
if(st == ed) k++;
dijkstra();
idx = 0;
memset(h,-1,sizeof h);
for(int i = 1;i <= m;i++){
auto [a,b,c] = in[i];
add(a,b,c);
}
cout << astar();
}
IDA*
IDA* 为采用了迭代加深算法的 A* 算法。
Dancing Links
时间复杂度与矩阵中1的个数有关,与矩阵r,c等参数无关,时间复杂度是指数级的$O(c^n)$,其中c为某个非常接近1的常数,n为矩阵中1的个数,尤其擅长处理稀疏矩阵。

精确覆盖
P4929 【模板】舞蹈链(DLX) - 洛谷 (luogu.com.cn)
给定N行M列的矩阵,每个元素要么是1,要么是0。请从中挑选诺干行,使得每列有且仅有一行有1。输出任意一个方案即可,顺序随意。$N,M \le 500$,保证1的个数不超过5000。
#include <iostream>
#include <vector>
std::vector<int>res;
struct DLX{//1_idx
int n,m,idx;
std::vector<int>first,siz,stk;//siz[c]存第c列的元素个数,stk存答案,first[r]指向第r行的第一个元素
std::vector<int>L,R,U,D;//十字循环链表
std::vector<int>col,row;//存放第idx个元素的列左边和行坐标
int ans;
void init(const int &r,const int &c){
ans = 1e9;
n = r,m = c;
first.resize(n+1),siz.resize(m+1);
L.resize(m+1),R.resize(m+1),U.resize(m+1),D.resize(m+1);
col.resize(m+1),row.resize(m+1);
for(int i = 0;i <= m;i++){
L[i] = i-1,R[i] = i+1;
U[i] = D[i] = i;
}
L[0] = m,R[m] = 0;
idx = m+1;
}
void remove(const int &c){//删除第c列,以及其它与它相关的行
L[R[c]] = L[c],R[L[c]] = R[c];
for(int i = D[c];i != c;i = D[i]){
for(int j = R[i];j != i;j = R[j]){
U[D[j]] = U[j];
D[U[j]] = D[j];
siz[col[j]]--;
}
}
}
void recover(const int &c){//还原第c列,以及其它与它相关的行,即remove的逆操作
for(int i = U[c];i != c;i = U[i]){
for(int j = L[i];j != i;j = L[j]){
U[D[j]] = D[U[j]] = j;
siz[col[j]]++;
}
}
L[R[c]] = R[L[c]] = c;
}
bool dance(){//精确覆盖
if(stk.size() >= ans) return 0;//剪枝:如果当前已经超过最优解,直接返回
if(!R[0]){//如果0号节点没有右节点,那么矩阵为空,记录答案并返回
ans = stk.size(); //当前stk[]即为一组解
res = stk;
return 1;
}
int c = R[0];
for(int i = R[0];i != 0;i = R[i]){
if(siz[i] < siz[c]) c = i;
}
remove(c);//优先选择元素个数最少得一列c,并删除这一列
for(int i = D[c];i != c;i = D[i]){//遍历这一列其它所有有1的行,递归枚举是否选择它
stk.push_back(row[i]);
for(int j = R[i];j != i;j = R[j]) remove(col[j]);
if(dance()) return 1; //任意解
// dance();//最小解
for(int j = L[i];j != i;j = L[j]) recover(col[j]);
stk.pop_back();
}
recover(c);
return 0;
}
void remove2(const int &c){//重复覆盖问题中只需要删除当前列
for(int i = D[c];i != c;i = D[i]){
L[R[i]] = L[i]; R[L[i]] = R[i];
}
}
void recover2(const int &c){
for(int i = U[c];i != c;i = U[i]){
L[R[i]] = R[L[i]] = i;
}
}
int f(){//估价函数
int res = 0;
std::vector<int>vis(m+1);
for(int i = R[0];i != 0;i = R[i]){
if(vis[i]) continue;
vis[i] = 1;
res++;
for(int j = D[i];j != i;j = D[j]){
for(int k = R[j];k != j;k = R[k]){
vis[col[k]] = 1;
}
}
}
return res;
}
bool dance2(){//重复覆盖
if(stk.size() + f() >= ans) return 0;
if(!R[0]) {
ans = stk.size();
return 1;
}
int c = R[0];
for(int i = R[0];i != 0;i = R[i]){
if(siz[i] < siz[c]) c = i;
}
for(int i = D[c];i != c;i = D[i]){
for(int j = R[i];j != i;j = R[j]) remove2(j);
remove2(i);
stk.push_back(row[i]);
// if(dance2()) return 1; 任意解
dance2();//最小解
stk.pop_back();
recover2(i);
for(int j = L[i];j != i;j = L[j]) recover2(j);
}
return 0;
}
void insert(const int &r,const int &c){//在第r行,第c列插入一个节点
col.push_back(c),row.push_back(r);
siz[c]++;
U.push_back(c),D.push_back(D[c]);
U[D[c]] = idx; D[c] = idx;
if(first[r] == 0){//如果第r行没有元素,那么直接插入一个元素,并使first[r]指向该元素
first[r] = idx;
L.push_back(idx),R.push_back(idx);
}
else{//否则把idx插入到c的正下方,把idx插入到first(r)的正右方
R.push_back(R[first[r]]);
L[R[first[r]]] = idx;
L.push_back(first[r]);
R[first[r]] = idx;
}
idx++;
}
};
int main() {
int n,m; std::cin >> n >> m;
DLX dlx;
dlx.init(n,m);
for(int i = 1;i <= n;i++){
for(int j = 1;j <= m;j++){
int x;std::cin >> x;
if(x) dlx.insert(i,j);
}
}
dlx.dance();
if(dlx.ans == 1e9) {
std::cout << "No Solution!";
}
else{
for(auto x:res){
std::cout << x << ' ';
}
}
}
求解大小为w*w的数独
#include <iostream>
#include <vector>
const int N = 10;
int w = 9;
int sw = 3;//sqrt(w)
int a[N][N];
int main(){
DLX dlx;
dlx.init(w*w*w,w*w*4);
for(int i = 0;i < w;i++){
for(int j = 0;j < w;j++){
std::cin >> a[i][j];
for(int k = 1;k <= w;k++){
if(a[i][j] != 0 && a[i][j] != k) continue;
int id = i*w*w + j*w + k;
dlx.insert(id,i*w + j + 1);
dlx.insert(id,i*w + w*w + k);
dlx.insert(id,j*w + w*w*2 + k);
dlx.insert(id,w*w*3 + (i/sw*sw + j/sw)*w + k);
}
}
}
dlx.dance();
for(int i = 0;i < w;i++){
for(int j = 0;j < w;j++){
std::cout << a[i][j] << ' ';
}
std::cout << '\n';
}
}
重复覆盖
remove、recover、dance操作略有不同。 调用dlx.dance2()即可。
因为重复覆盖问题方案一般比精确覆盖多,搜索基于IDA*优化,加入了估价函数f()。
倍增
倍增法(英语:binary lifting),顾名思义就是翻倍。它能够使线性的处理转化为对数级的处理,大大地优化时间复杂度。
这个方法在很多算法中均有应用,其中最常用的是 RMQ 问题和求 LCA(最近公共祖先)。
ST表
ST表(Sparse Table,稀疏表)基于倍增思想,用于解决[可重复贡献问题][区间重合区域不影响结果,如「RMQ 」、「区间按位与」、「区间按位或」、「区间 GCD」]的数据结构,不支持修改 O($N\log N$)预处理 O(1)查询

令$st(i,j)$表示区间$[i,i+2^j-1]$的最大值,显然$st(i,0)=a_i$ 根据定义式,第二维就相当于倍增的时候「跳了 $2^j-1$ 步」,依据倍增的思路,写出状态转移方程:$st(i,j)=\max(st(i,j-1),st(i+2^{j-1},j-1))$
对于每个询问 $[l,r]$,我们把它分成两部分:$[l,l+2^s-1]$ 与 $[r-2^s+1,r]$,其中 $s=\left\lfloor\log_2(r-l+1)\right\rfloor$。两部分的结果的最大值就是回答。
//https://www.luogu.com.cn/problem/P2880
#include <bits/stdc++.h>
using namespace std;
namespace S_T{ //1_idx
const int N = 1000006;
int lg2[N];
struct info{
long long mx,mn; //mn,gcd,and,or;
info(){}
info(const int &x) { //init_info
mx = mn = x;
}
info friend operator + (const info &e1,const info &e2) { //updaet_info
info ans;
ans.mx = std::max(e1.mx,e2.mx);
ans.mn = std::min(e1.mn,e2.mn);
return ans;
}
};
void init_lg2(){ //下取整
lg2[0] = -1;
for(int i = 1;i < N;i++){
lg2[i] = lg2[i>>1]+1;
}
}
template<typename T>
struct ST{
int n,m;
std::vector<std::vector<info>>st;
ST(){}
ST(const T &v) {
if(~lg2[0]) init_lg2();
n = v.size()-1,m = lg2[v.size()];
st = std::vector<std::vector<info>>(n+1,std::vector<info>(m+1));
for(int i = 1;i < v.size();i++){ st[i][0] = v[i]; }
for(int j = 1;(1<<j) < v.size();j++){
int pj = 1 << (j-1);
for(int i = 1;i+(1<<j)-1 < v.size();i++){
st[i][j] = st[i][j-1] + st[i+pj][j-1];
}
}
}
info query(int l,int r) {
int x = lg2[r-l+1];
info ans = st[l][x] + st[r-(1<<x)+1][x];
return ans;
}
};
}
using S_T::ST,S_T::info;
int main() {
int n,q; std::cin >> n >> q;
vector<int> a(n+1);
for(int i = 1;i <= n;i++){
std::cin >> a[i];
}
ST t(a);
while(q--){
int l,r; std::cin >> l >> r;
auto ans = t.query(l,r);
std::cout << ans.mx - ans.mn << '\n';
}
}
根号分治
根号分治,是一种对数据进行点分治的分治方式,它的作用是优化暴力算法,类似与分块,但应用范围比分块更广。
具体来说,对于所进行的操作,按照某个点B划分,分为大于B以及小于B两个部分,两部分使用不同的方式处理。(一般以根号为分界$B = \sqrt{N}$,这样复杂度最平衡)。将两个暴力算法“拼接在一起”,实现优化复杂度的作用。
Colorful Graph(★6) - AtCoder typical90_ce - Virtual Judge (vjudge.net)
给定N个点M条边的无向图,初始时每个点颜色为1。再给定Q次查询,每次查询给定两个整数{x,c},输出当前点x的颜色,然后将点x及其所有相邻的点颜色改为c。$1 \le N,M,Q \le 2e5$
ans[x]={time,color}表示当前点最后被更新时的时间戳和颜色,flag[x]={time,color}flag状态标记,表示当前节点在time时更新应周围节点为color。
以度数是否大于$\sqrt{N}$为分界,将点划分为重点和轻点。轻点直接枚举,重点打标记。
查询当前点:对于轻点,直接枚举所有邻接点更新自身。对于重点,本身已经被其它点更新。
更新邻接点:只需要更新周围的重点。
#include <bits/stdc++.h>
int main(){
int n,m;std::cin >> n >> m;
int sn = sqrt(m<<1);
std::vector<std::vector<int>>e(n+1);
std::vector<int>du(n+1);
for(int i = 1;i <= m;i++){
int x,y;std::cin >> x >> y;
e[x].emplace_back(y);
e[y].emplace_back(x);
du[x]++; du[y]++;
}
for(int i = 1;i <= n;i++){
std::sort(e[i].begin(),e[i].end(),[&](int x,int y){return du[x] > du[y];});
}
std::vector<std::pair<int,int>>ans(n+1,{0,1}),flag(n+1,{0,1});
int q;std::cin >> q;
for(int i = 1;i <= q;i++){
int x,c;std::cin >> x >> c;
if(du[x] <= sn){
for(auto& y:e[x]){
ans[x] = std::max(ans[x],flag[y]);
}
}
std::cout << ans[x].second << '\n';
ans[x] = flag[x] = {i,c};
for(auto& y:e[x]){
if(du[y] <= sn) break;
ans[y] = flag[x];
}
}
}
数据结构
基本数据结构
链表
单链表
const int N = 100010;
//head 表示头节点的下标
//e[i] 表示节点i的值
//ne[i] 表示节点i的next指针是多少
//idx 储存当前已经用到了哪个点
int head, e[N], ne[N], idx;
//初始化
void init() {
head = -1;
idx = 0;
}
//将x插到头节点
void add_to_head(int x) {
e[idx] = x;
ne[idx] = head; //x指向开头
head = idx; //x的位置变为新的开头
idx++;
}
//将x插到下标是k的点的后面(注意下标从0开始)
void add(int k, int x) {
e[idx] = x;
ne[idx] = ne[k]; //x指向k的后一位
ne[k] = idx; //k再指向x
idx++;
}
//将下标是k的点的后面一个点删掉
void remove(int k) {
ne[k] = ne[ne[k]];//原来指向k的后位改为指向k后位的后位
}
//遍历链表
for(int i = head;i != -1;i = ne[i]){
cout << e[i] << " ";
}
//https://www.acwing.com/problem/content/828/
#include <bits/stdc++.h>
using namespace std;
const int N = 100005;
int e[N], ne[N], idx,h = -1;
void add_to_head(int x) {
e[idx] = x;
ne[idx] = h;
h = idx++;
}
void add(int k, int x) {
e[idx] = x;
ne[idx] = ne[k];
ne[k] = idx++;
}
void del(int k) {
ne[k] = ne[ne[k]];
}
int main() {
int t; cin >> t;
for (int i = 1; i <= t;i++) {
char op; cin >> op;
if (op == 'I') {
int k, x; cin >> k >> x;
add(k - 1, x);//第k个数,下标为k-1
}
if (op == 'H') {
int x; cin >> x;
add_to_head(x);
}
if (op == 'D') {
int k; cin >> k;
if (k == 0) h = ne[h];//k == 0 表示删除头结点
else del(k-1);
}
}
for (int i = h; i != -1; i = ne[i]) cout << e[i] << " ";
return 0;
}
双链表
const int N = 100010;
int e[N], l[N], r[N], idx;
//初始化
void init() {
//0表示左端点,1表示右端点
r[0] = 1, l[1] = 0;
idx = 2; //从2开始
}
//在下标为k的右边插入值x
void addr(int k, int x) {
e[idx] = x;
r[idx] = r[k]; //x的右边指向k的下一位
l[idx] = k; //x的左边指向k
l[r[k]] = idx; //k的下一位的左边指向x (注意与下一条语句顺序不能写反)
r[k] = idx; //k的右边指向x
}
//在下标为k的左边插入值x
void addl(int k, int x) {
addr(l[k], x); //相当于在k左边一个数的右边插入x
}
//删除下标为k的点
void remove(int k) {
r[l[k]] = r[k]; //让原来右边指向k的指针 指向k的右边
l[r[k]] = l[k]; //让原来左边指向k的指针 指向k的左边
}
问题转化为差分数组 $a_1$ ~ $a_{n-1}$ 中选则各不相邻的k个数
#include <iostream>
#include <queue>
using ll = long long;
using namespace std;
const ll inf = 1e18;
const int N = 100005;
int n,k;
ll a[N];
ll ne[N],la[N],s[N];//双链表
bool del[N];//标记当前节点是否已经删除
ll ans;
struct Edge{
ll id,x;
bool operator < (const Edge &e) const {
return x > e.x;//优先队列小根堆
}
};
int main(){
cin >> n >> k;
priority_queue<Edge>pq;
for(int i = 1;i <= n;i++){
cin >> a[i];
if(i > 1) s[i-1] = a[i] - a[i-1];
}
s[0] = s[n] = inf;//左右两边设置哨兵
for(int i = 1;i < n;i++){
pq.push({i,s[i]});
ne[i] = i+1;
la[i] = i-1;
}
while(k--){
while(del[pq.top().id]) pq.pop();//诺该点已经被删除,则直接弹出
auto [id,x] = pq.top();
pq.pop();
ans += x;//选择当前节点
//删除当前节点和左右两边的节点,在当前节点位置新建一个节点
//诺未来选了该新节点,则相当于不选当前节点,选择当前节点左右两边的节点
s[id] = s[la[id]] + s[ne[id]] - s[id];
Edge e = {id,s[id]};
pq.push(e);
del[ne[id]] = del[la[id]] = 1;//删除左右两边的节点
la[id] = la[la[id]];
ne[id] = ne[ne[id]];
ne[la[id]] = id;
la[ne[id]] = id;
}
cout << ans;
}
栈
先进后出
#include <iostream>
using namespace std;
const int N = 100010;
//tt表示栈尾
int stk[N], tt;
//插入
stk[++tt] = x;
//弹出
tt--;
//判断栈是否为空
if (tt > 0) not empty
else empty
//栈顶
stk[tt];
//带最小值的栈
//新建一个栈B,每次A入栈x时,B入栈min(B.top(),x);
stack<int>A,B;
void push(int x){
A.push(x);
if(B.empty()) B.push(x);
else B.push(min(x,B.top()));
}
void pop(){
A.pop();
B.pop();
}
int top(){
return A.top();
}
int getmin(){
return B.top();
}
//火车进站方案 https://www.acwing.com/problem/content/131/
#include <iostream>
#include <vector>
#include <stack>
using namespace std;
const int N = 30;
int n,rest;
vector<int>p;//p存已经出站的序列
stack<int>st;//栈
void dfs(int u){
if(rest >= 20) return;
if(p.size() == n){//边界条件,如果全部出站则输出序列
rest++;
for(auto &x:p) cout << x;
cout << endl;
return;
}
if(st.size()){//情况一:栈中元素出站
p.push_back(st.top());
st.pop();
dfs(u);
st.push(p.back());//还原现场
p.pop_back();
}
if(u <= n){//情况二:火车入栈
st.push(u);
dfs(u+1);
st.pop();//还原现场
}
}
int main(){
cin >> n;
dfs(1);
return 0;
}
表达式计算
中缀表达式:A op B 前缀表达式:op A B (波兰式) 后缀表达式:A B op (逆波兰式)
后缀表达式求值
后缀表达式对于计算机来讲容易实现
建立一个用于存储数的栈,逐一扫描该后缀表达式中的元素
如果遇到一个数,则把该数入栈。
如果遇到运算符,则取出栈顶两个数进行计算,把结果入栈。
扫描完成后,栈中恰好剩下一个数,即为该后缀表达式的答案
if(c[k]>='0' && c[k]<='9') q.push(c[k]-'0'); //假设表达式都是1位数
if(c[k]=='-') i=q.top(),q.pop(),j=q.top(),q.pop(), q.push(j-i);
if(c[k]=='+') i=q.top(),q.pop(),j=q.top(),q.pop(), q.push(j+i);
if(c[k]=='*') i=q.top(),q.pop(),j=q.top(),q.pop(), q.push(j*i);
if(c[k]=='/') i=q.top(),q.pop(),j=q.top(),q.pop(), q.push(j/i);
单调栈
//输出每个数左边第一个比它小的数,如果不存在则输出-1;
#include <iostream>
#include <stack>
using namespace std;
const int N = 100005;
int n,a[N];
stack<int>sk;
int ans[N];
int main(){
cin >> n;
for(int i = 1;i <= n;i++) { cin >> a[i]; }
for(int i = 1;i <= n;i++){
while(sk.size() && sk.top() >= a[i]) sk.pop();
if(sk.size()) ans[i] = sk.top();
else ans[i] = -1;
sk.push(a[i]);
}
for(int i = 1;i <= n;i++){ cout << ans[i] << ' '; }
}
//https://www.acwing.com/problem/content/133/
#include <iostream>
#include <stack>
using namespace std;
using ll = long long;
const int N = 100005;
ll a[N];
ll l[N],r[N];//l[i]记录左边最后一个大于等于本身的下标,r[i]记录右边最后一个大于等于本身的下标
//对于每一个高度a[i],能组成的最大面积为a[i]*(r[i]-l[i]+1)
int main(){
int n;
while(cin >> n,n){
a[0] = a[n+1] = -1;//在边界设置哨兵
for(int i = 1;i <= n;i++) cin >> a[i];
stack<ll>sk;
for(int i = 0;i <= n+1;i++){
while(sk.size() && a[sk.top()] >= a[i]) sk.pop();
if(sk.size()) l[i] = sk.top()+1;
else l[i] = i;
sk.push(i);
}
sk = stack<ll>();
for(int i = n+1;i >= 0;i--){
while(sk.size() && a[sk.top()] >= a[i]) sk.pop();
if(sk.size()) r[i] = sk.top()-1;
else r[i] = i;
sk.push(i);
}
ll ans = 0;
for(int i = 1;i <= n;i++){
ans = max(ans,a[i]*(r[i] - l[i] + 1));
}
cout << ans << endl;
}
return 0;
}
队列
| ql | ← | ← | ← | ← | qr |
|---|---|---|---|---|---|
| hh | tt |
先进先出
//双端队列
//hh表示队首front,tt表示队尾back
int q[N], hh = 0, tt = -1;
//入队(队尾)
q[++tt] = x;
//弹出(队首)
hh++;
//判断队列是否非空
if (hh <= tt) return 1;
q[hh]//队首元素
q[tt]//队尾元素
单调队列
滑动窗口
| 窗口位置 | 最小值 | 最大值 |
|---|---|---|
| [1 3 -1] -3 5 3 6 7 | -1 | 3 |
| 1 [3 -1 -3] 5 3 6 7 | -3 | 3 |
| 1 3 [-1 -3 5] 3 6 7 | -3 | 5 |
| 1 3 -1 [-3 5 3] 6 7 | -3 | 5 |
| 1 3 -1 -3 [5 3 6] 7 | 3 | 6 |
| 1 3 -1 -3 5 [3 6 7] | 3 | 7 |
此处的 “队列” 跟普通队列的一大不同就在于可以从队尾进行操作,STL 中有类似的数据结构 deque
//滑动窗口之最值
#include <iostream>
using namespace std;
const int N = 1000010;
int a[N], q[N]; //a[N]为数组,q[N]队列存下标
int main() {
int n, k;
cin >> n >> k;
for (int i = 1; i <= n; i++) scanf("%d", &a[i]);
int hh = 0, tt = -1;
for (int i = 1;i <= n;i++){//hh<=tt判断队列是否为空,相当于!q.empty()或q.size()
if (hh <= tt && i-k >= q[hh]) hh++;//i-k>=q[hh]窗口已经形成,则每次循环队首右移
while (hh <= tt && a[q[tt]] > a[i]) tt--;//求最小,把队列中>a[i]的数都弹出
q[++tt] = i;
if (i >= k) printf("%d ", a[q[hh]]);//队首即为最小值
}
puts("");
hh = 0, tt = -1;
for (int i = 1; i <= n; i++){
if (hh <= tt && i-k >= q[hh]) hh++;
while (hh <= tt && a[q[tt]] < a[i]) tt--;//求最大类似
q[++tt] = i;
if (i >= k) printf("%d ", a[q[hh]]);
}
return 0;
}
//STL的deque实现,比数组模拟要慢
#include <iostream>
#include <deque>
using namespace std;
const int N = 1000006;
int a[N];
int main(){
int n,k;cin >> n >> k;
for(int i = 1;i <= n;i++) {cin >> a[i];}
deque<int>dq;
for(int i = 1;i <= n;i++){
if(dq.size() && i - k >= dq.front()) dq.pop_front();
while(dq.size() && a[dq.back()] >= a[i]) dq.pop_back();
dq.push_back(i);
if(i >= k) cout << a[dq.front()] << ' ';
}
cout << '\n';
dq.clear();
for(int i = 1;i <= n;i++){
if(dq.size() && i - k >= dq.front()) dq.pop_front();
while(dq.size() && a[dq.back()] <= a[i]) dq.pop_back();
dq.push_back(i);
if(i >= k) cout << a[dq.front()] << ' ';
}
}
最大子段和
给定一个长度为 n 的整数序列,从中找出一段长度不超过 m 的连续子序列,使得子序列中所有数的和最大。
最优策略是,下标递增,对应前缀和也递增
#include <iostream>
#include <cstring>
using namespace std;
const int N = 300005;
int n,m,a[N];
int q[N],hh,tt;//tt = -1;q[++tt] = 0;
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++){
cin >> a[i];
a[i] += a[i-1];
}
int ans = 0x80000000; //初始化为负无穷
for(int i = 1;i <= n;i++){
ans = max(ans,a[i]-a[q[hh]]);
if(hh <= tt && i - q[hh] >= m) hh++;
while(hh <= tt && a[q[tt]] >= a[i]) tt--;//单调递增队列,队首a[q[hh]]为最小值
q[++tt] = i;
}
cout << ans;
return 0;
}
堆
堆是一棵树,其每个节点都有一个键值,且每个节点的键值都大于等于/小于等于其父亲的键值。
堆主要支持的操作有:插入一个数、查询最小值、删除最小值、合并两个堆、减小一个元素的值。
一些功能强大的堆(可并堆)还能(高效地)支持 merge 等操作。
一些功能更强大的堆还支持可持久化,也就是对任意历史版本进行查询或者操作,产生新的版本。
二叉堆
//下标从1开始比较方便:第k个数,左儿子为2k,右儿子为2k+1
| 操作 | 实现 |
|---|---|
| 1.插入一个数 | heap[++size] = x; up(size); |
| 2.求集合当中最小值 | heap[1]; |
| 3.[删除最小值][将第一个数等于最后一个数,删掉最后一个数,再下沉第一个数] | heap[1] = heap[size]; size–; down[1]; |
| 4.[删除任意一个元素][将第k个数等于最后一个数,删掉最后一个数,再上下这个数] | heap[k] = heap[size]; size–; down[k]; up[k]; |
| 5.修改任意一个元素 | heap[k] = x; down[k]; up[k]; |
int h[100010],cnt;
void down(int u) {
int t = u;
if (u * 2 <= cnt && h[u * 2] < h[t]) t = u * 2;
if (u * 2 + 1 <= cnt && h[u * 2 + 1] < h[t]) t = u * 2 + 1;//令t为u及其子节点中的最小节点
if (u != t) {//判断u是不是最小节点,不是则与最小节点t交换,继续下沉(递归处理)
swap(h[u], h[t]);
down(t);
}
}
void up(int u) {
if (u / 2 && h[u / 2] > h[u]) {//诺比父节点小,则二者交换
swap(h[u / 2], h[u]);
u /= 2;
}
}
给定 m 个序列,每个包含 n 个非负整数。 现在我们可以从每个序列中选择一个数字以形成具有 m 个整数的序列。 很明显,我们一共可以得到 n^m 个这种序列,然后我们可以计算每个序列中的数字之和,并得到 n^m 个值。 求出这些序列和之中最小的 n 个值。
思路:第一个数组a[]依次与其他数组合并,每次将a[]更新最小的n个数
#include <iostream>
#include <algorithm>
#include <queue>
using namespace std;
using pii = pair<int,pair<int,int>>;
const int N = 2003;
int n,m;
int a[N],b[N],c[N];
struct Edge{
int s,x,y;//s为a[x]+b[y]的值
bool operator < (const Edge &e)const {
return s > e.s;//运算符重载,小根堆
}
};
void merge(){//数组a[]与数组b[]合并
priority_queue<Edge>pq;//a[]为有序数组,a[x],b[y]为n*n的组合,y一定时a[x]+b[y]有序
for(int i = 1;i <= n;i++){
pq.push({a[1]+b[i],1,i});
}
vector<int>ans;
for(int i = 1;i <= n;i++){
auto [s,x,y] = pq.top();//a[x]+b[y]出队,a[x+1]+b[y]入队
pq.pop();
c[i] = s;
x++;
pq.push({a[x]+b[y],x,y});
}
for(int i = 1;i <= n;i++){
a[i] = c[i];
}
}
void sol(){
cin >> m >> n;
for(int i = 1;i <= n;i++){ cin >> a[i]; }
sort(a+1,a+n+1);
m--;
while(m--){
for(int i = 1;i <= n;i++){ cin >> b[i]; }
merge();
}
for(int i = 1;i <= n;i++){ cout << a[i] << ' '; }
cout << endl;
}
int main(){
int T;cin >> T;
while(T--){ sol(); }
}
左偏树
左偏树(leftist tree)是一种可并堆,具有堆的性质,可以快速合并,支持可持久化。
| 插入 | 查询最小值 | 删除最小值 | 合并 | |
|---|---|---|---|---|
| O(logN) | O(1) | O(logN) | O(logN) |
配对堆
配对堆是一个支持插入,查询/删除最小值,合并,修改元素等操作的数据结构,是一种可并堆。有速度快和结构简单的优势,但由于其为基于势能分析的均摊复杂度,不支持可持久化。
| 插入 | 查询最小值 | 删除最小值 | 合并 | |
|---|---|---|---|---|
| O(1) | O(1) | O(logN) | O(1) |
配对堆是一棵满足堆性质的带权多叉树,即每个节点的权值都小于或等于他的所有儿子。每个节点储存第一个儿子的指针,即链表的头节点;和他的右兄弟的指针。
查询最小值:根节点即为最小值。
合并:令两个根节点较小的作为一个新的根节点,然后将较大的作为它的儿子插进去。
插入:新建一个节点然后与原堆合并即可。
删除:删除操作较为麻烦,为了保证总的均摊复杂度,需要使用一个两步走的合并方法
- 把儿子们两两配成一对,在把配成一对的儿子合并到一起。
- 将新产生的堆从右往左(即老儿子到新儿子的方向)挨个合并到一起。
//封装实现,堆顶为最小值. 未经过严谨测试,可能尚存bug
template<typename type>
class heap{
size_t heap_size;
struct node{
node *s,*t;//s指向该节点的第一个儿子,t指向该节点的下一个兄弟
type val;
}*root;
node *merge_bros(node *p){//辅助函数,合并一个节点的所有兄弟
if(p==nullptr || p->t==nullptr) return p;//如果该节点为空或它没有下一个兄弟,就不需要合并了
node *q=p->t;node *d=q->t;p->t=q->t=nullptr;
return merge(merge_bros(d),merge(p,q));
}
inline node *merge(node *p,node *q){//合并两个节点
if(p==nullptr) return q;
if(q==nullptr) return p;
if(p->val > q->val) swap(p,q);
q->t=p->s,p->s=q;
return p;
}
public:
inline heap<type>(){root=nullptr;}
inline void merge(node *p){
if(root==nullptr){root=p;return;}
if(p==nullptr) return;
if(root->val > p->val) swap(p,root);
p->t=root->s,root->s=p;
}
inline void merge(heap x){//合并两个堆,将堆x并入当前堆(不会清空x)
node *p=x.root;
heap_size += x.size();
if(root==nullptr){root=p;return;}
if(p==nullptr) return;
if(root->val > p->val) swap(p,root);
p->t=root->s,root->s=p;
}
inline void push(type x){
heap_size++;
node *p=new node;
p->val=x;p->s=nullptr,p->t=nullptr;
merge(p);
}
inline void pop(){
heap_size--;
node *T=root;
root=merge_bros(root->s);
delete T;
}
inline type top(){return root->val;}
inline bool empty(){return !heap_size;}
inline size_t size(){return heap_size;}
inline void clear(){root=nullptr;}
};
int main(){
heap<int> pq1,pq2;
pq1.push(2);pq2.push(1);
pq1.merge(pq2);
std::cout << pq1.top() << ' ' << pq1.size() << '\n';
}
哈希
开放寻址法
#include <iostream>
using namespace std;
const int N = 2000003, null = 0x3f3f3f3f;//N取大于所给范围两~三倍的一个质数,null取一个取不到的数
int h[N];
int find(int x) {
int k = (x % N + N) % N;
//如果x存在则返回x在哈希表中的位置,否则返回x应该在哈希表中插入的位置
while (h[k] != null && h[k] != x) {//如果这个位置有值且不是x,则k++,直到找到一个空位(null)
k++;
if (k == N) k = 0;//诺k为N,则重新从0开始找
}
return k;
}
int main() {
memset(h, 0x3f, sizeof h);//初始化,memset按字节初始化,int类型只要填一个0x3f
int x; cin >> x;
int k = find(x);
//插入x
h[k] = x;
//查询x是否存在
if (h[k] == x) cout << "YES";
else cout << "NO";
return 0;;
}
拉链法
#include <iostream>
#include <cstring>
using namespace std;
const int N = 100003;//N取大于所给范围的第一个质数
int h[N], e[N], ne[N],idx;//e,ne为单链表用法,h为头结点
void insert(int x) {
int k = (x % N + N) % N;//k为哈希值
e[idx] = x;
ne[idx] = h[k];
h[k] = idx++;
}
bool find(int x) {
int k = (x % N + N) % N;
for (int i = h[k]; i != -1;i = ne[i]) {
if (e[i] == x) return true;
}
return false;
}
int main() {
memset(h, -1, sizeof h);//初始化为-1(空指针一般用-1表示)
}
定义Hash函数$H(a_1…a_6) = (\sum_{i=1}^6a_i + \prod_{i=1}^6a_i)\%mod$
#include <iostream>
#include <cstring>
using namespace std;
using ll = long long;
const int N = 100005,mod = 100003;//取接近N的质数
int h[N],ne[N],idx;
int snow[N][6];//第idx个位置对应的雪花snow[idx][6]
int n;
int hs(int a[]){//哈希函数
ll sum = 0,mul = 1;
for(int i = 0;i < 6;i++){
sum = (sum+a[i])%mod;
mul = mul*a[i]%mod;
}
return (sum+mul)%mod;
}
bool equal(int a[],int b[]){//判断两片雪花是否相等
for(int i = 0;i < 6;i++){
for(int j = 0;j < 6;j++){
bool eq = 1;
for(int k = 0;k < 6;k++){
if(a[(i+k)%6] != b[(j+k)%6]) eq = 0;
}
if(eq) return 1;
eq = 1;
for(int k = 0;k < 6;k++){
if(a[(i+k)%6] != b[(j-k+6)%6]) eq = 0;
}
if(eq) return 1;
}
}
return 0;
}
bool insert(int a[]){
int key = hs(a);
for(int i = h[key];i != -1;i = ne[i]){//诺发生哈希冲突
if(equal(snow[i],a)) return 1;//且出现两片雪花相等,返回1
}
//否则在哈希值对应链表位置接上该雪花
memcpy(snow[idx],a,6*sizeof(int));
ne[idx] = h[key];
h[key] = idx++;
return 0;
}
int main(){
cin >> n;
memset(h,-1,sizeof h);
for(int i = 1;i <= n;i++){
int a[10];
for(int j = 0;j < 6;j++) cin >> a[j];
if(insert(a)){
cout << "Twin snowflakes found.";
return 0;
}
}
cout << "No two snowflakes are alike.";
}
并查集
并查集(DSU)是一种用于管理元素所属集合的数据结构,实现为一个森林,其中每棵树表示一个集合,树中的节点表示对应集合中的元素
int p[N],siz[N];//p[i]存节点i的根节点,siz[i]存以i为根的集合大小
int find(int x){//查找x的根节点+路径压缩
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
void merge(int a,int b){//将a所在集合并入b所在集合
int pa = find(a),pb = find(b);
if(pa == pb) return;
p[pa] = pb;
siz[pb] += siz[pa];
}
int main(){
for(int i = 1;i <= n;i++) p[i] = i,siz[i] = 1;//初始化每个节点的父节点为自身
}
i == p[i] 父节点等于自身的数量即为连通块的数量How Many Tables - HDU 1213 - Virtual Judge (vjudge.net)
//二维矩阵类型并查集(也可以改用pair<int,int>,或者将二维坐标[x,y]映射为一维)
struct node {
int x,y;
bool operator == (const node&e2)const{
return x == e2.x && y == e2.y;
}
bool operator != (const node&e2)const{
return x != e2.x || y != e2.y;
}
}p[N][N];
node find(node x){
if(p[x.x][x.y] != x) p[x.x][x.y] = find(p[x.x][x.y]);
return p[x.x][x.y];
}
void merge(node x1,node x2){
node pa = find(x1),pb = find(x2);
if(pa == pb) return;
else p[pa.x][pa.y] = pb;
}
边带权并查集
并查集实际上是由诺干棵树构成的森林,我们可以在树中的每条边上记录一个权值,即维护一个数组d[ ],用d[x]保存节点x到父亲节点p[x]之间的边权。在每次路径压缩后,每个访问过的节点都会直接指向树根,如果我们同时更新这些节点的d值,就可以利用路径压缩过程来统计每个节点到树根之间的路径上的一些信息。

关系的传递可以看做向量。
如果pa == pb那么我们可以检查d[a] + s是否等于d[b]来判断是否矛盾,或者求出相对关系大小s。
否则可以合并两者:p[pb] = pb, d[pb] = d[a] + s - d[b]。
[P1196 NOI2002] 银河英雄传说 - 洛谷 (luogu.com.cn)
有N只飞船,M条指令,每条指令为以下之一:
1.
M i j,表示让i号飞船所在的队列全部飞船保持原有顺序,接在第j号飞船所在队列的尾部 2.C i j,表示询问第i号飞船与第j号飞船当前是否处于同一列中,如果在,输出他们之间间隔了多少飞船
#include <iostream>
const int N = 30004;
int n = 30000,q;
int p[N],d[N],siz[N];//d[x]代表x与其父节点(路径压缩后即根结点)之间的边的权值,即位于x之前的飞船数量
int find(int x){//带权并查集模版,路径压缩时维护d[]
if(p[x] != x) {
int root = find(p[x]);
d[x] += d[p[x]];
p[x] = root;
}
return p[x];
}
int main(){
for(int i = 1;i <= n;i++) p[i] = i,siz[i] = 1;
std::cin >> q;
while(q--){
char op;int a,b;std::cin >> op >> a >> b;
int pa = find(a),pb = find(b);
if(op == 'M'){
if(pa == pb) continue;
else{
p[pa] = pb;//将a所在队列并入b所在队列
int s = siz[pb]-d[b] + d[a];//s即为(b到队列pb尾部的距离)+(队列pa头部到a的距离)
d[pa] = d[b] + s - d[a];
siz[pb] += siz[pa];
}
}
if(op == 'C'){
if(pa == pb) std::cout << std::max(0,std::abs(d[b] - d[a])-1) << '\n';
else std::cout << -1 << '\n';
}
}
}
拓展域并查集
用于解决具有多个相互关系集合的问题。它是传统并查集的扩展,能够处理集合间的不同关系,如相互排斥或相互独立的关系。
[P1525 NOIP 2010 提高组] 关押罪犯 - 洛谷 (luogu.com.cn)
n 个点有 m 对关系,把 n 个节点放入两个集合里,要求每对存在关系的两个节点不能放在同一个集合。问能否成功完成?
我们使用拓展域并查集,将u和u+n分别表示u的两个相反状态,将(u,v+n)连边表示(u,v)不应在一个集合里(也可以看作u和v的反状态在一个集合里)。相应的(v,u+n)也应该连边。诺(u,u+n)在同一个集合里则说明发生了矛盾。
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 40004,M = 100005;
int n,m;
int p[N];
struct node{
int a,b,c;
bool operator < (const node &e2)const{
return c > e2.c;
}
}e[M];
int find(int x){
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
void merge(int x,int y){
int px = find(x),py = find(y);
if(px != py) p[px] = py;
}
int main(){
cin >> n >> m;
for(int i = 1;i <= n << 1;i++) p[i] = i;
for(int i = 1;i <= m;i++){
cin >> e[i].a >> e[i].b >> e[i].c;
}
sort(e+1,e+m+1);
for(int i = 1;i <= m;i++){
auto [a,b,c] = e[i];
merge(a,b+n); merge(a+n,b);
if(find(a) == find(a+n) || find(b) == find(b+n)) {//发生矛盾
cout << c;
return 0;
}
}
cout << 0;
}
[P2024 NOI2001] 食物链 - 洛谷 (luogu.com.cn)
每个动物都是A,B,C的一种,三者形成环形食物链,依次给出m个句话,为以下两种形式之一
1 x y表示x和y是同类2 x y表示x吃y诺当前话与前面的话产生矛盾,则当前话为假话。求有多少假话。
我们用(x)表示同类域,(x+n)表示捕食域,(x+2n)表示天敌域
#include <iostream>
const int N = 50004*3;
int n,q;
int p[N],d[N];
int find(int x){
if(p[x] != x) {
int root = find(p[x]);
d[x] += d[p[x]];
p[x] = root;
}
return p[x];
}
void merge(int x,int y){
int px = find(x),py = find(y);
if(px == py) return;
p[px] = py;
}
int main(){
int ans = 0;
std::cin >> n >> q;
for(int i = 1;i <= n*3;i++) p[i] = i;
while(q--){
int op,x,y;std::cin >> op >> x >> y;
if(x > n || y > n) {ans++;continue;}
if(op == 1){//x与y是同类
if(find(x) == find(y+n) || find(x) == find(y+n+n)) ans++;//如果y是x的食物或y是x的天敌,矛盾
else{
merge(x,y);
merge(x+n,y+n);
merge(x+n+n,y+n+n);
}
}
else{//x吃y
if(find(x) == find(y+n+n) || find(x) == find(y)) ans++;//如果y是x的天敌或y是x的同类,矛盾
else{
merge(x,y+n);
merge(x+n,y+n+n);
merge(x+n+n,y);
}
}
}
std::cout << ans;
}
分块
O($N$)预处理,O($\sqrt N$)修改/查询,支持区间修改,单点插入,区间查询等操作,较为灵活
| 元素个数n (1~n) | |
|---|---|
| 每一块的最长长度m | m = sqrt(n) |
| 块的个数num | num = (n/m)+bool(n%m) |
| 第i个元素所在的块id[i] | id[i] = (i-1)/m + 1 |
| 第i个元素所在块的左端点b[id[i]].l | if(b[id[i]].l == 0) b[id[i]].l = i |
| 第i个元素所在块的右端点b[id[i]].r | b[id[i]].r = max( b[id[i]].r , i ) |
//数据定义
int id[N];//第i个元素在哪个块中
struct Block{//存每一块的属性
int l,r;//该块的左右端点
ll lazy;//lazy标记
ll sum;//区间和
ll add;//区间加标记
ll mul;//区间乘标记
ll cnt;//块中元素个数标记
//...
}b[N];
vector<int>v[N]; //如果需要对块进行排序、拷贝等操作,可以开vector数组将每一个元素放入对应块中
//初始化
void initi(){
m = sqrt(n);
for(int i = 1;i <= n;i++){
id[i] = (i-1)/m + 1;//第i个元素在第id[i]块
if(b[id[i]].l == 0) b[id[i]].l = i;//第id[i]块的左右端点
b[id[i]].r = max(b[id[i]].r,(ll)i);
//v[id[i]].emplace_back(a[i]);
}
}
//修改/查询
//如果l和r在同一块
if(id[l] == id[r]){
for(int i = l;i <= r;i++){
//直接枚举l~r所有元素
}
}
//如果l和r不在同一块
else{
for(int i = l;id[i] == id[l];i++){
//枚举l所在块
}
for(int i = r;id[i] == id[r];i--){
//枚举r所在块
}
for(int i = id[l]+1;i < id[r];i++){
//l~r之间所有完整块利用区间属性快速操作
}
}
//区间修改,区间求小于x的数的个数:https://loj.ac/p/6278
//区间修改,区间求大于等于x的数的个数:https://www.luogu.com.cn/problem/P2801
#include <iostream>
#include <algorithm>
#include <cmath>
#include <vector>
using namespace std;
using ll = long long;
const ll N = 100005;
ll n,m,cnt;
ll a[N];
ll id[N];
vector<ll>v[N];//v[i]存第i块排序后的序列
struct Bolck{
ll l,r,lazy;
}b[N];
void initi(){
m = sqrt(n);
for(int i = 1;i <= n;i++){
id[i] = (i-1)/m + 1;
v[id[i]].emplace_back(a[i]);
if(b[id[i]].l == 0) b[id[i]].l = i;
b[id[i]].r = max(b[id[i]].r,(ll)i);
}
for(int i = 1;i <= id[n];i++){
sort(v[i].begin(),v[i].end());
}
}
void bsort(int i){//块排序
v[i].clear();
for(int j = b[i].l;j <= b[i].r;j++){
v[i].emplace_back(a[j]);
}
sort(v[i].begin(),v[i].end());
}
void add(ll l,ll r,ll c){
if(id[l] == id[r]){
for(int i = l;i <= r;i++){
a[i]+=c;
}
bsort(id[l]);
}
else{
for(int i = l;id[i] == id[l];i++){
a[i]+=c;
}
for(int i = r;id[i] == id[r];i--){
a[i]+=c;
}
for(int i = id[l]+1;i < id[r];i++){
b[i].lazy += c;
}
bsort(id[l]);
bsort(id[r]);
}
}
ll query(int l,int r,int c){
ll ans = 0;
if(id[l] == id[r]){
for(int i = l;i <= r;i++){
ans+=(a[i] < c-b[id[i]].lazy);
}
}
else{
for(int i = l;id[i] == id[l];i++){
ans+=(a[i] < c-b[id[i]].lazy);
}
for(int i = r;id[i] == id[r];i--){
ans+=(a[i] < c-b[id[i]].lazy);
}
for(int i = id[l]+1;i < id[r];i++){//l~r之间每个完整块v[i]二分查找
ans+=lower_bound(v[i].begin(),v[i].end(),c-b[i].lazy)-v[i].begin();
}
}
return ans;
}
int main(){
cin >> n;
for(int i = 1;i <= n;i++){ cin >> a[i]; }
initi();
for(int i = 1;i <= n;i++){
ll op,l,r,c;cin >> op >> l >> r >> c;
if(op == 0){ add(l,r,c);}
else{ cout << query(l,r,c*c) <<endl; }
}
}
//单点插入,单点查询
#include <iostream>
#include <vector>
#include <cmath>
using namespace std;
const int N = 100005<<1;
int n,m,all,num;//n:初始元素数量,all:插入后元素数量,m:块长度,num:块数量
int a[N];
vector<int>v[N];
int id[N];
void initi(){
m = sqrt(all);
num = all/m + bool (all%m);
for(int i = 1;i <= all;i++){
id[i] = (i-1)/m + 1;
v[id[i]].emplace_back(a[i]);
}
}
void reint(){//重新分块,保证每块都接近sqrt(all),否则可能退化为普通数组
int cnt = 1;
for(int i = 1;i <= num;i++){
for(int j = 0;j < v[i].size();j++){
a[cnt++] = v[i][j];
}
v[i].clear();
}
}
void ins(int l,int x){
int cnt = 1;
while(l > v[cnt].size()){//根据每个块的长度推出第l个元素的位置
l -= v[cnt].size();
cnt++;
}
v[cnt].insert(v[cnt].begin()+ l-1,x);
all++;
if(v[id[l]].size() > 2*m){//如果插入后,块的长度>2*m,则清空v[]还原到a[],重新初始化分块
reint();
initi();
}
}
int query(int r){
int cnt = 1;
while(r > v[cnt].size()){
r -= v[cnt].size();
cnt++;
}
return v[cnt][r-1];
}
int main(){
cin >> n;
all = n;
for(int i = 1;i <= n;i++){
cin >> a[i];
}
initi();
for(int i = 1;i <= n;i++){
int op,l,r,c;cin >> op >> l >> r >> c;
if(op == 0){ ins(l,r); }
else{ cout << query(r) << endl; }
}
}
树状数组
树状数组是(Fenwick Tree)一种支持单点修改和区间查询,代码量小的数据结构,树状数组能解决的问题是线段树能解决的问题的子集
普通树状数组维护的信息及运算要满足 结合律 且 可差分,如加法、乘法、异或等。
一维树状数组

template<typename T>
struct Fenwick{
int n;
vector<T>t;
Fenwick(int n_ = 0){
init(n_);
}
void init(int n_){
n = n_ + 1;
t.assign(n,T{});
}
void add(int i,const T &x){
while(i <= n){
t[i] += x;
i += i&-i;
}
}
T sum(int i){
T ans = 0;
while(i){
ans += t[i];
i -= i&-i;
}
return ans;
}
T sum(int l,int r){
return sum(r) - sum(l-1);
}
int kth(int k){
int sum = 0,x = 0;
for(int i = log2(n);i >= 0;i--){
int nx = x + (1 << i);
if(nx < n && sum + t[nx] < k){
x = nx;
sum += t[x];
}
}
return x + 1;
}
};
Fenwick<int>t(n);
区间修改,单点查询
//利用差分及前缀和数组,t[]建树为差分数组
#include <iostream>
using namespace std;
using ll = long long;
const int N = 1000006;
int n,q;
ll a[N],t[N];
ll lowbit(ll x){return x&-x;}
void add(ll i,ll x){
while(i <= n){
t[i] += x;
i += lowbit(i);
}
}
ll getsum(int i){
ll ans = 0;
while(i > 0){
ans += t[i];
i -= lowbit(i);
}
return ans;
}
int main(){
cin >> n >> q;
for(int i = 1;i <= n;i++){
cin >> a[i];
}
while(q--){
int op;cin >> op;
if(op == 1){//区间l~r加上x
int l,r,x;cin >> l >> r >> x;
add(l,x);add(r+1,-x);
}
else{//查询下标为x的数所在的值
int x;cin >> x;
cout << a[x] + getsum(x) << '\n';
}
}
}
权值树状数组
诺题目允许离线,则离散化后空间复杂度为O(N),否则需要开到O(值域)的大小。
单点修改,全局第k小
// 权值树状数组查询全局第 k 小,倍增代替二分,O(logN)
int kth(int k){
int sum = 0,x = 0;
for(int i = log2(n);i >= 0;i--){//要注意n应为b[]的值域而非数组大小
int nx = x + (1 << i);
if(nx < n && sum + t[nx] < k){//诺成功扩展
x = nx;
sum += t[x];
}
}
return x + 1;
}
P3369 【模板】普通平衡树 - 洛谷 (luogu.com.cn)
您需要动态地维护一个可重集合 $M$,并且提供以下操作:
- 向 $M$ 中插入一个数 $x$。
- 从 $M$ 中删除一个数 $x$(若有多个相同的数,应只删除一个)。
- 查询 $M$ 中有多少个数比 $x$ 小,并且将得到的答案加一。
- 查询如果将 $M$ 从小到大排列后,排名位于第 $x$ 位的数。
- 查询 $M$ 中 $x$ 的前驱(前驱定义为小于 $x$,且最大的数)。
- 查询 $M$ 中 $x$ 的后继(后继定义为大于 $x$,且最小的数)。
对于操作 3,5,6,不保证当前可重集中存在数 $x$。
本题中我们只需要关心的是每个数之间的相对关系,且允许离线,因此可以离散化处理。
#include <iostream>
#include <cmath>
#include <algorithm>
#include <vector>
using namespace std;
const int N = 100005;
int op[N],a[N];
int n;
vector<int>hs;
template<typename T>
struct Fenwick{
int n;
vector<T>t;
Fenwick(int n_ = 0){
init(n_);
}
void init(int n_){
n = n_ + 1;
t.assign(n,T{});
}
void add(int i,const T &x){
while(i <= n){
t[i] += x;
i += i&-i;
}
}
T sum(int i){
T ans = 0;
while(i){
ans += t[i];
i -= i&-i;
}
return ans;
}
T sum(int l,int r){
return sum(r) - sum(l-1);
}
int kth(int k){
int sum = 0,x = 0;
for(int i = log2(n);i >= 0;i--){
int nx = x + (1 << i);
if(nx < n && sum + t[nx] < k){
x = nx;
sum += t[x];
}
}
return x + 1;
}
};
int main(){
int q;cin >> q;
for(int i = 1;i <= q;i++){
cin >> op[i] >> a[i];
if(op[i] != 4) hs.emplace_back(a[i]);
}
hs.emplace_back(-1e9);
sort(hs.begin(),hs.end());
hs.erase(unique(hs.begin(),hs.end()),hs.end());
n = hs.size()-1;
for(int i = 1;i <= q;i++){
if(op[i] != 4) a[i] = lower_bound(hs.begin(),hs.end(),a[i])-hs.begin();
}
Fenwick<int>t(n+5);
for(int i = 1;i <= q;i++){
if(op[i] == 1) t.add(a[i],1);//插入一个数x
if(op[i] == 2) t.add(a[i],-1);//删除一个数x
if(op[i] == 3) cout << t.sum(a[i]-1)+1 << '\n';//a[i]的排名,即区间[1,q[i]-1]的数的个数再加1
if(op[i] == 4) cout << hs[t.kth(a[i])] << '\n';//查询全局第k小的数(下标从1开始)
if(op[i] == 5) cout << hs[t.kth(t.sum(a[i]-1))] << '\n';//前驱(诺不存在则返回x)
if(op[i] == 6) cout << hs[t.kth(t.sum(a[i])+1)] << '\n';//后继(诺不存在则返回x)
}
}
静态区间颜色数
给点一个长度为n的数组a[ ],q个询问:区间[l,r]不同元素的个数。
思路:对于询问多个区间 [L,R] 中出现不同数字个数,当 R 相同时,如果区间出现了重复数字,那么我们只需要关心最右端的这个数字就可以了。换言之,重复出现的数字在左端将无任何贡献。例如 {1 2 3 1 4},在询问 区间[1,4] 时,第一个 1 无任何贡献,并且当询问的 R 不断右移的过程中,第一个 1 都无任何意义,被第四位置的替代掉。
于是把询问离线下来,按照询问的右端点排序。
当出现一个数字时,如果这个数字曾经出现,则 add(lst[pos[i]],-1),把这个数在上一个位置的标记清掉,add(pos[i],1) 来更新这个数字的新位置。只需要维护第i个位置上有没有数,求区间[l,r]内有多少个数。
用树状数组单点修改、区间查询。用前缀和 query(R)-query(L-1) 把区间[L,R]的数的个数出来。
//HH的项链 https://www.luogu.com.cn/problem/P1972
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1000006;
int n,q;
int a[N];//本题a[i] <= 1e6,不用离散化
int pos[N];
int ans[N];
struct Ask{
int l,r,id;
bool operator < (Ask &e2){
return r < e2.r;
}
}ask[N];
int t[N];
void add(int i,int x){
while(i <= n){
t[i] += x;
i += i&-i;
}
}
int query(int i){
int ans = 0;
while(i > 0){
ans += t[i];
i -= i&-i;
}
return ans;
}
int main(){
cin >> n;
for(int i = 1;i <= n;i++) cin >> a[i];
cin >> q;
for(int i = 1;i <= q;i++){
cin >> ask[i].l >> ask[i].r;
ask[i].id = i;
}
sort(ask+1,ask+q+1);//按右端点升序排序
for(int i = 1,j = 1;i <= q;i++){//处理每个询问ask[i],j为当前右端点。
auto &[l,r,id] = ask[i];
while(j <= r){//更新j到ask[i].r的值
if(pos[a[j]]) add(pos[a[j]],-1);//诺a[j]之前已经出现过则删去
pos[a[j]] = j;
add(j,1);
j++;
}
ans[id] = query(r) - query(l-1);
}
for(int i = 1;i <= q;i++) cout << ans[i] << '\n';
}
线段树
线段树是常用的用来维护 区间信息 的数据结构。
可以在 $O(\log N)$ 的时间复杂度内实现单点/区间修改、区间查询(sum、max、min)等操作。

建树
struct ST{
int l,r;
int dat;//lazy,mx,mn,sum,gcd...
}t[N<<2];//至少要开 4*N 空间
void build(int p,int l,int r){//build(1,1,n);
t[p] = {l,r,0};
if(l == r){t[p].dat = a[l];return;}
int mid = l + r >> 1;
build(p+p,l,mid);build(p+p+1,mid+1,r);//递归建树
//t[p].dat = f(t[p+p].dat,t[p+p+1].dat);
}
单点修改,区间查询
单点修改:从根节点开始遍历,递归找到需要修改的叶子节点,然后修改,然后向上传递信息。
区间查询: 1.若当前节点所表示的区间已经被询问区间所完全覆盖,则立即回溯,并传回该点的信息。 2.若当前节点的左儿子所表示的区间已经被询问区间所完全覆盖,就递归访问它的左儿子。 3.若当前节点的右儿子所表示的区间已经被询问区间所完全覆盖,就递归访问它的右儿子。
//单点修改,区间最值 http://acm.hdu.edu.cn/showproblem.php?pid=1754
void change(int p,int i,int x){//change(1,i,x);
if(t[p].l == t[p].r) {t[p].mx = x;return;}
int mid = t[p].l + t[p].r >> 1;
if(i <= mid) change(p+p,i,x);
else change(p+p+1,i,x);
t[p].mx = max(t[p+p].mx,t[p+p+1].mx);
}
int query_max(int p,int l,int r){//query(1,l,r);
if(l <= t[p].l && r >= t[p].r) return t[p].mx;
int mid = t[p].l + t[p].r >> 1;
int ans = -1e9;
if(l <= mid) ans = max(ans,query(p+p,l,r));
if(r > mid) ans = max(ans,query(p+p+1,l,r));
return ans;
}
int query(int p,int i){//单点查询
if(t[p].l == t[p].r) return t[p].mx;
int mid = t[p].l + t[p].r >> 1;
if(i <= mid) return query(p<<1,i);
else return query(p<<1|1,i);
}
//单点修改,求区间最大子段和 https://www.luogu.com.cn/problem/SP1716
//单点修改,求区间最大值出现次数 https://ac.nowcoder.com/acm/contest/90296/E
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 50004;
int n,q;
int a[N];
struct ST{
int l,r;
int ls,rs;//紧靠左端点和紧靠右端点的最大子段和
int ans,sum;//sum为区间和,ans为最长子段和
}t[N<<2];
void pushup(ST &p,ST &pl,ST &pr){
p.sum = pl.sum + pr.sum;
p.ls = max(pl.ls,pl.sum+pr.ls);//紧靠左端点不跨越中间和跨越中间取最大值
p.rs = max(pr.rs,pr.sum+pl.rs);
p.ans = max({pl.ans,pr.ans,pl.rs+pr.ls});//答案在{左区间答案,右区间答案,跨中间的最长子段}取最值
}
void build(int p,int l,int r){
t[p] = {l,r};
if(l == r){
t[p].ls = t[p].rs = t[p].ans = t[p].sum = a[l];
return;
}
int mid = l + r >> 1;
build(p<<1,l,mid);build(p<<1|1,mid+1,r);
pushup(t[p],t[p<<1],t[p<<1|1]);
}
void change(int p,int i,int x){
if(t[p].l == t[p].r){
t[p].ls = t[p].rs = t[p].ans = t[p].sum = x;
return;
}
int mid = t[p].l + t[p].r >> 1;
if(i <= mid) change(p<<1,i,x);
else change(p<<1|1,i,x);
pushup(t[p],t[p<<1],t[p<<1|1]);
}
ST query(int p,int l,int r){//更加通用的query写法,返回的是一个节点包含了区间[l,r]的ans、sum等信息
if(l <= t[p].l && r >= t[p].r){
return t[p];
}
int mid = t[p].l + t[p].r >> 1;
if(r <= mid) return query(p<<1,l,r);//要查询的区间在mid左边,答案在左区间,注意l,r位置
if(l > mid) return query(p<<1|1,l,r);//要查询的区间在mid右边,答案在右区间
ST pl = query(p<<1,l,r);
ST pr = query(p<<1|1,l,r);
ST ans;
pushup(ans,pl,pr);
return ans;
}
int main(){
cin >> n;
for(int i = 1;i <= n;i++){
cin >> a[i];
}
build(1,1,n);
cin >> q;
while(q--){
int op,l,r;cin >> op >> l >> r;
if(op == 0){
change(1,l,r);
}
else{
cout << query(1,l,r).ans << '\n';
}
}
}
F - Palindrome Query (atcoder.jp)
单点修改,查询区间是否为回文串(字符串哈希)
$h(abcd) = s[0]p^3 + s[1]p^2 + s[2]*p^1 + s[3]$
我们只需要单点修改,求区间和即可得到子串哈希值。比较正反串的哈希值是否一致判断回文串。
#include <iostream>
using namespace std;
using ull = unsigned long long;
const ull P = 131;
const int N = 1000006;
int n,q;
ull f[N];
string s;
struct ST{
int l,r;
ull kl,kr;
}t[N<<2];
void pushup(ST &p,ST &pl,ST &pr){
p.kl = pl.kl + pr.kl;
p.kr = pl.kr + pr.kr;
}
void pushup(int p){
pushup(t[p],t[p<<1],t[p<<1|1]);
}
void update(ST &p,char x){
p.kl = f[n-p.l]*x;
p.kr = f[p.l-1]*x;
}
void build(int p,int l,int r){
t[p] = {l,r};
if(l == r){
update(t[p],s[l-1]);
return;
}
int mid = l + r >> 1;
build(p<<1,l,mid);build(p<<1|1,mid+1,r);
pushup(p);
}
void modify(int p,int i,char x){
if(t[p].l == t[p].r){
update(t[p],x);
return;
}
int mid = t[p].l + t[p].r >> 1;
if(i <= mid) modify(p<<1,i,x);
else modify(p<<1|1,i,x);
pushup(p);
}
ST query(int p,int l,int r){
if(l <= t[p].l && r >= t[p].r){
return t[p];
}
int mid = t[p].l + t[p].r >> 1;
if(r <= mid) return query(p<<1,l,r);
if(l > mid) return query(p<<1|1,l,r);
ST pl = query(p<<1,l,r);
ST pr = query(p<<1|1,l,r);
ST ans;
pushup(ans,pl,pr);
return ans;
}
int main(){
f[0] = 1;
for(int i = 1;i < N;i++){
f[i] = f[i-1]*P;
}
cin >> n >> q;
cin >> s;
build(1,1,n);
while(q--){
int op;cin >> op;
if(op == 1){
int x; char op; cin >> x >> op;
modify(1,x,op);
}
else{
int l,r;cin >> l >> r;
auto ans = query(1,l,r);
ull kl = ans.kl,kr = ans.kr;
int k1 = l-1,k2 = n-r;
if(k1 > k2) kl *= f[k1-k2];
else kr *= f[k2-k1];
if(kl == kr){ cout << "Yes\n"; }
else{ cout << "No\n"; }
}
}
}
//区间修改,区间公约数 https://www.luogu.com.cn/problem/P10463
//利用gcd辗转相减法性质,将a[]数组变为差分数组d[],区间修改(a[l~r]+x)变为单点修改(a[l]+x,d[r-1]-x)
//答案为 gcd(a[l],d[l+1],...,d[r]) 的绝对值
#include <iostream>
using namespace std;
using ll = long long;
const int N = 500005;
int n,q;
ll a[N];
ll gcd(ll a,ll b){return b?gcd(b,a%b):a;}
struct ST{
int l,r;
ll dat,sum;
}t[N<<2];
void pushup(ST &p,ST &pl,ST &pr){
p.dat = gcd(pl.dat,pr.dat);
p.sum = pl.sum + pr.sum;
}
void build(int p,int l,int r){
t[p] = {l,r};
if(l == r){
t[p].dat = t[p].sum = a[l] - a[l-1];
return;
}
int mid = l + r >> 1;
build(p<<1,l,mid);build(p<<1|1,mid+1,r);
pushup(t[p],t[p<<1],t[p<<1|1]);
}
void add(int p,int i,ll x){
if(t[p].l == t[p].r){
t[p].dat += x;
t[p].sum += x;
return;
}
int mid = t[p].l + t[p].r >> 1;
if(i <= mid) add(p<<1,i,x);
else add(p<<1|1,i,x);
pushup(t[p],t[p<<1],t[p<<1|1]);
}
ll query_sum(int p,int l,int r){
if(l <= t[p].l && r >= t[p].r){
return t[p].sum;
}
ll ans = 0;
int mid = t[p].l + t[p].r >> 1;
if(l <= mid) ans += query_sum(p<<1,l,r);
if(r > mid) ans += query_sum(p<<1|1,l,r);
return ans;
}
ll query_gcd(int p,int l,int r){
if(l <= t[p].l && r >= t[p].r){
return t[p].dat;
}
ll ans = 0;
int mid = t[p].l + t[p].r >> 1;
if(l <= mid) ans = gcd(ans,query_gcd(p<<1,l,r));
if(r > mid) ans = gcd(ans,query_gcd(p<<1|1,l,r));
return ans;
}
int main(){
cin >> n >> q;
for(int i = 1;i <= n;i++){
cin >> a[i];
}
build(1,1,n);
while(q--){
char op;cin >> op;
if(op == 'C'){
ll l,r,x;cin >> l >> r >> x;
add(1,l,x);
if(r+1 <= n) add(1,r+1,-x);
}
else{
int l,r;cin >> l >> r;
cout << abs(gcd(query_gcd(1,l+1,r),query_sum(1,1,l))) << '\n';
}
}
}
区间修改,区间查询,lazy标记
通过延迟对节点信息的更改,从而减少可能不必要的操作次数。每次执行修改时,我们通过打标记的方法表明该节点对应的区间在某一次操作中被更改,但不更新该节点的子节点的信息。实质性的修改则在下一次访问带有标记的节点时才进行。叶子结点无需下放标记。
Transformation - HDU 4578 - Virtual Judge (vjudge.net)
对数组
a[]实现以下操作1 x y z将区间[x,y]之间的每个元素增加z。$1\le z \le 10000$2 x y z将区间[x,y]之间的每个元素乘以z。$1\le z \le 10000$3 x y z将区间[x,y]之间的每个元素变为z。$1\le z \le 10000$4 x y z输出$a_x^z + a_{x+1}^z + \dots + a_y^z$对10007取模后的结果。$1\le z\le3$
#include <iostream>
const int mod = 10007;
const int N = 100005;
int n,m;
struct ST{
int l,r;
long long d[4];
long long add,mul;
}t[N<<2];
void build(int p,int l,int r){
t[p] = {l,r};
if(l == r){
t[p].add = 0;
t[p].mul = 1;
return;
}
int mid = l + r >> 1;
build(p<<1,l,mid);build(p<<1|1,mid+1,r);
}
void pushup(ST &p,ST &pl,ST &pr){
p.d[1] = (pl.d[1] + pr.d[1]) % mod;
p.d[2] = (pl.d[2] + pr.d[2]) % mod;
p.d[3] = (pl.d[3] + pr.d[3]) % mod;
}
void pushup(int p){
pushup(t[p],t[p<<1],t[p<<1|1]);
}
void update(ST &p,long long add,long long mul){//注意答案、数据的更新顺序
int len = p.r - p.l + 1;
p.add = (p.add * mul + add) % mod;
p.mul = (p.mul * mul) % mod;
p.d[3] = (mul*mul%mod*mul%mod*p.d[3]%mod + 3*mul*mul%mod*add%mod*p.d[2]%mod + 3*add*add%mod*mul%mod*p.d[1]%mod + add*add%mod*add%mod*len%mod) % mod;
p.d[2] = (p.d[2]*mul%mod*mul%mod + 2*mul*add%mod*p.d[1]%mod + add*add%mod*len%mod) % mod;
p.d[1] = (p.d[1]*mul + len*add) % mod;
}
void pushdown(int p){
auto &add = t[p].add,&mul = t[p].mul;
if(add || mul != 1){//同时下传所有标记
update(t[p<<1],add,mul);
update(t[p<<1|1],add,mul);
add = 0,mul = 1;
}
}
void modify(int p,int l,int r,int x,int op){//用当前标记更新答案(和更新其它标记(如果有且需要更新))
if(l <= t[p].l && r >= t[p].r){
if(op == 1){//add
update(t[p],x,1);
}
if(op == 2){//mul
update(t[p],0,x);
}
if(op == 3){//same 相当于区间乘0再加x
update(t[p],x,0);
}
return;
}
pushdown(p);
int mid = t[p].l + t[p].r >> 1;
if(l <= mid) modify(p<<1,l,r,x,op);
if(r > mid) modify(p<<1|1,l,r,x,op);
pushup(p);
}
ST query(int p,int l,int r){//比较通用的query写法
if(l <= t[p].l && r >= t[p].r){
return t[p];
}
pushdown(p);
int mid = t[p].l + t[p].r >> 1;
if(r <= mid) return query(p<<1,l,r);
if(l > mid) return query(p<<1|1,l,r);
ST pl = query(p<<1,l,r),pr = query(p<<1|1,l,r),ans;
pushup(ans,pl,pr);
return ans;
}
void sol(){
build(1,1,n);
while(m--){
int op,x,y,z;std::cin >> op >> x >> y >> z;
if(op == 4)std::cout << query(1,x,y).d[z] << '\n';
else modify(1,x,y,z,op);
}
}
int main(){
std::ios::sync_with_stdio(false);std::cin.tie(0);
while(std::cin >> n >> m,n|m) sol();
}
SP2713 GSS4 - Can you answer these queries IV - 洛谷 (luogu.com.cn)
区间开平方,求区间和
对于区间开平方,由于我们无法在不更新叶子节点时更新区间,因此无法使用lazy标记优化区间修改。考虑到每个数最多被开平方有限次之后就会变为1,于是我们在修改时,一直修改到 叶子节点 或者 当前区间所有数都为1。
const int N = 100005;
int n,q;
long long a[N];
struct ST{
int l,r;
long long dat;
}t[N<<2];
void pushup(ST &p,ST &pl,ST &pr){
p.dat = pl.dat + pr.dat;
}
void pushup(int p){
pushup(t[p],t[p<<1],t[p<<1|1]);
}
void build(int p,int l,int r){
t[p] = {l,r};
if(l == r){
t[p].dat = a[l];
return;
}
int mid = l + r >> 1;
build(p<<1,l,mid);build(p<<1|1,mid+1,r);
pushup(p);
}
void modify(int p,int l,int r){
if(t[p].dat == t[p].r - t[p].l + 1) {//当前区间所有数都为1时,直接返回
return;
}
if(t[p].l == t[p].r) {//当前为叶子节点时,直接修改
t[p].dat = std::sqrt(t[p].dat);
return;
}
int mid = t[p].l + t[p].r >> 1;
if(l <= mid) modify(p<<1,l,r);
if(r > mid) modify(p<<1|1,l,r);
pushup(p);
}
ST query(int p,int l,int r){
if(l <= t[p].l && r >= t[p].r){
return t[p];
}
int mid = t[p].l + t[p].r >> 1;
if(r <= mid) return query(p<<1,l,r);
if(l > mid) return query(p<<1|1,l,r);
ST pl = query(p<<1,l,r),pr = query(p<<1|1,l,r),ans;
pushup(ans,pl,pr);
return ans;
}
void sol(){
for(int i = 1;i <= n;i++) std::cin >> a[i];
build(1,1,n);
std::cin >> q;
while(q--){
int op,l,r;std::cin >> op >> l >> r;
if(l > r) std::swap(l,r);
if(op == 0) modify(1,l,r);
else std::cout << query(1,l,r).dat << '\n';
}
}
权值线段树
对权值作为维护对象而开的线段树,每个点存的是区间内对应数字的某种值(如出现次数等),操作跟线段树类似。
诺题目允许离线,则离散化后空间复杂度为O(N),否则需要开到O(max_val)的大小。
P3369 【模板】普通平衡树 - 洛谷 (luogu.com.cn)
与权值树状数组实现类似。
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
const int N = 100005;
int op[N],a[N];
vector<int>hs;
struct st{
int l,r;
int dat;
}t[N<<2];
void pushup(int p){
t[p].dat = t[p<<1].dat + t[p<<1|1].dat;
}
void build(int p,int l,int r){
t[p] = {l,r};
if(l == r){
t[p].dat = 0;
return;
}
int mid = l + r >> 1;
build(p<<1,l,mid);build(p<<1|1,mid+1,r);
pushup(p);
}
void modify(int p,int l,int r,int x){//单点修改
if(l <= t[p].l && r >= t[p].r){
if(t[p].dat + x >= 0) t[p].dat += x;
return;
}
int mid = t[p].l + t[p].r >> 1;
if(l <= mid) modify(p<<1,l,r,x);
if(r > mid) modify(p<<1|1,l,r,x);
pushup(p);
}
int rnk(int p,int l,int r){//查询区间[l,r]的和
if(l <= t[p].l && r >= t[p].r){
return t[p].dat;
}
int mid = t[p].l + t[p].r >> 1;
int ans = 0;
if(l <= mid) ans += rnk(p<<1,l,r);
if(r > mid) ans += rnk(p<<1|1,l,r);
return ans;
}
int kth(int p,int k){//线段树上二分,查询全局第k小的数的下标(只能查全局)
if(t[p].l == t[p].r){
return t[p].l;
}
if(k <= t[p<<1].dat) return kth(p<<1,k);
else return kth(p<<1|1,k-t[p<<1].dat);
}
int main(){
int q;cin >> q;
for(int i = 1;i <= q;i++){
cin >> op[i] >> a[i];
if(op[i] == 4) continue;
hs.emplace_back(a[i]);
}
hs.emplace_back(-1e9);
sort(hs.begin(),hs.end());
hs.erase(unique(hs.begin(),hs.end()),hs.end());
int m = hs.size()-1;
for(int i = 1;i <= q;i++){
if(op[i] == 4) continue;
a[i] = lower_bound(hs.begin(),hs.end(),a[i])-hs.begin();
}
build(1,1,m);
for(int i = 1;i <= q;i++){
if(op[i] == 1){//插入一个数x
modify(1,a[i],a[i],1);
}
if(op[i] == 2){//删除一个数x(如有多个,只删除一个)
modify(1,a[i],a[i],-1);
}
if(op[i] == 3){//a[i]的排名,即区间[1,a[i]-1]的数的个数再加1
if(a[i] == 1) {cout << 1 << '\n';continue;}
cout << rnk(1,1,a[i]-1)+1 << '\n';
}
if(op[i] == 4){//查询全局第k小的数(下标从1开始)
cout << hs[kth(1,a[i])] << '\n';
}
if(op[i] == 5){//查找x的前驱(诺不存在则返回x)
int rk = rnk(1,1,a[i]-1);
cout << hs[kth(1,rk)] << '\n';
}
if(op[i] == 6){//查找x的后继(诺不存在则返回x)
int rk = rnk(1,1,a[i])+1;
cout << hs[kth(1,rk)] << '\n';
}
}
}
霍夫曼树
从根结点到各叶结点的路径长度与相应叶节点权值的乘积之和称为 树的带权路径长度(Weighted Path Length of Tree,WPL)。
设 $w_i$ 为二叉树第 $i$ 个叶结点的权值,$l_i$ 为从根结点到第 $i$ 个叶结点的路径长度,则 WPL 计算公式如下:
\[WPL=\sum_{i=1}^nw_il_i\](也等于所有非叶子节点之和)对于给定一组具有确定权值的叶结点,可以构造出不同的树,其中,WPL 最小的树 称为 霍夫曼树(Huffman Tree)。霍夫曼树不唯一。
如果每个字符的 使用频率相等,那么等长编码无疑是空间效率最高的编码方法,而如果字符出现的频率不同,则可以让频率高的字符采用尽可能短的编码,频率低的字符采用尽可能长的编码,来构造出一种 不等长编码,从而获得更好的空间效率。
在设计不等长编码时,要考虑解码的唯一性,如果一组编码中任一编码都不是其他任何一个编码的前缀,那么称这组编码为 前缀编码,其保证了编码被解码时的唯一性。
霍夫曼树可用于构造 最短的前缀编码,即 霍夫曼编码(Huffman Code)
不建树直接求n个节点k叉树的最小WPL
让n满足==(n-1)%(k-1) == 0==,否则不断填0,n++ 建立小根堆,每次取堆顶的k个求和s,再将s入堆,直到小根堆只剩一个元素
#include <iostream>
#include <queue>
using namespace std;
priority_queue<int,vector<int>,greater<int>>pq;
int main(){
int n,k;cin >> n >> k;
for(int i = 1;i <= n;i++){
int x;cin >> x;
pq.push(x);
}
while((n-1)%(k-1) != 0){
pq.push(0);
n++;
}
int ans = 0;
while(pq.size() > 1){
int sum = 0;
for(int i = 0;i < k;i++){
int x = pq.top();
pq.pop();
sum += x;
}
pq.push(sum);
ans += sum;
}
cout << ans;
}
//合并果子加强版:https://www.luogu.com.cn/problem/P6033
//简化版为n个节点2叉树的WPL;n<=1e5
//加强版n<=1e7,但a[i]比较小,可以用O(N)的桶排
//使用两个queue代替优先队列(保证单调性)
#include <iostream>
#include <queue>
using namespace std;
using ll = long long;
const int N = 100005;
int a[N],idx;
queue<ll>q1,q2;//q1为排序后的原数组,q2为合并的果子数组,可以证明q2为单调递增
int read(){
int x = 0,f = 1;
char ch = getchar();
while(!isdigit(ch)){ if(ch == '-') f = -1; ch = getchar(); }
while(isdigit(ch)){ x = x*10 + ch - '0'; ch = getchar(); }
return x*f;
}
ll get_top(){
ll x;
if(q2.empty() || (q1.size() && q1.front() < q2.front())){
x = q1.front(); q1.pop();
}
else{
x = q2.front(); q2.pop();
}
return x;
}
int main(){
int n;cin >> n;
for(int i = 1;i <= n;i++){
int x = read();
a[x]++;//直接使用O(N)的桶排
}
for(int i = 1;i < N;i++){
for(int j = 0;j < a[i];j++){
q1.emplace(i);
}
}
ll ans = 0;
while(q1.size() + q2.size() > 1){
ll x = get_top();//每次从q1和q2中选最小的两个取出
ll y = get_top();
ans += x+y;
q2.push(x+y);//累加到答案后,加入q2队尾
}
cout << ans;
}
求最短WPL,并且要让最长的霍夫曼编码最短
只需在合并时,对于权值相同的节点,优先考虑当前深度最小(已合并次数最少)的进行合并即可
 两种霍夫曼树WPL均为12,但右图最长编码更小
两种霍夫曼树WPL均为12,但右图最长编码更小
#include <iostream>
#include <queue>
using namespace std;
using ll = long long;
using pii = pair<ll,ll>;
int n,k;
priority_queue<pii,vector<pii>,greater<pii>>pq;
ll ans;
int main(){
cin >> n >> k;
for(int i = 1;i <= n;i++){
ll x;cin >> x;
pq.push({x,0});
}
while((n-1)%(k-1) != 0){
pq.push({0,0});
n++;
}
while(pq.size() > 1){
ll sum = 0;
ll dep = 0;
for(int i = 0;i < k;i++){
auto [x,y] = pq.top();
pq.pop();
sum += x;
dep = max(dep,y);
}
pq.push({sum,dep+1});
ans += sum;
}
cout << ans << endl << pq.top().second << endl;
}
字符串
string s = “ABCDE”
子串(substring):s[i]~s[j] 连续的一段,如:BCD 子序列(subsequence):s[i]~s[j] 将若干元素提取出来并不改变相对位置形成的序列,如:ACD
前缀s[0~i]:A、AB、ABC、ABCD、ABCDE 真前缀:不包括本身的前缀 A、AB、ABC、ABCD
后缀s[i~n-1]:E、DE、CDE、BCDE、ABCDE 真后缀:不包括本身的后缀 E、DE、CDE、BCDE
回文串 :是正着写和倒着写相同的字符串,如aba、aa、abcba
字典序:以第i个字符作为第i关键字进行大小比较,空字符小于字符集内任何字符
如:abc < adc、a < aa、abcd < adcd
border:字符串中真前缀和真后缀相等的一段: 如f[a] = 0、f[aba] = a、f[abab] = ab、f[ababa] = a,aba、f[aaaa] = a,aa,aaa
字符串哈希
只能匹配子串,不能匹配子序列
全称字符串前缀哈希法,把字符串变成一个p进制数字(哈希值),实现不同的字符串映射到不同的数字。 对形如 $X_1X_2X_3···X_{n-1}X_n$的字符串, 采用字符的ascii码乘上 P 的次方来计算哈希值。 映射公式: $(X_1 × P^{n-1} + X_2 × P^{n-2} +…+ X_{n-1} × P^1 + X_n × P^0)mod\ Q$ \(h(S) := (\sum_{i=0}^{n-1}{P^{n-i-1}*s[i]})\ mod\ Q\) 注意点: 1.任意字符不可以映射成0,否则会出现不同的字符串都映射成0的情况,比如A, AA, AAA皆为0 2.冲突问题:通过巧妙设置底数P(131或 13331),模数[Q(2^64)][ull,自然溢出]的值,减少冲突
问题是比较不同区间的子串是否相同,就转化为对应的哈希值是否相同。 求一个字符串的哈希值就相当于求前缀和,求一个字符串的子串哈希值就相当于求部分和。
前缀和公式 $h[i+1] = h[i] × P + s[i],0 <=i<=n-1$,h为前缀和数组,s为字符串数组 区间和公式$h[l,r] = h[r+1] - h[l] × P^{r-l+1}$
区间和公式的理解:ABCDE 与 ABC 的前三个字符值是一样,只差两位, 乘上 P² 把 ABC 变为 ABC00,再用 ABCDE-ABC00得到 DE 的哈希值。
#include <iostream>
#include <set>
#include <vector>
namespace Hash{
const unsigned long long base = 131,mod = 1e9+7;
std::vector<unsigned long long>p(1,1),p2(1,1);//p[]建议开定长数组提前预处理
template<typename T>
struct hx{
std::vector<unsigned long long>h;
hx(){}
hx(const T &s){
init(s.size());
h = std::vector<unsigned long long>(s.size()+1);
for(int i = 0;i < s.size();i++){
h[i+1] = h[i] * base + s[i];
}
}
unsigned long long query(int l,int r){
return h[r+1] - h[l]*p[r-l+1];
}
void init(int id){
while(p.size() <= id){
p.emplace_back(p.back()*base);
}
}
};
template<typename T>
struct hx2{
std::vector<unsigned long long>h,h2;
hx2(){}
hx2(const T &s){
int n = s.size();
init(s.size());
h.resize(n+1);h2.resize(n+1);
for(int i = 0;i < s.size();i++){
h[i+1] = h[i]*base + s[i];
h2[i+1] = (h2[i]*base + s[i]) % mod;
}
}
std::pair<unsigned long long,unsigned long long> query(int l,int r){
unsigned long long k1 = h[r+1] - h[l]*p[r-l+1];
unsigned long long k2 = (h2[r+1] - h2[l]*p2[r-l+1]%mod + mod) % mod;
return std::pair{k1,k2};
}
void init(int id){
while(p.size() <= id){
p.emplace_back(p.back()*base);
p2.emplace_back(p2.back()*base%mod);
}
}
};
};
using Hash::hx,Hash::hx2;
int main(){
std::ios::sync_with_stdio(false); std::cin.tie(0);
int n,q; std::cin >> n >> q;
std::string s; std::cin >> s;
s = ' ' + s;
hx hs(s);
while(q--){
int l1,r1,l2,r2; std::cin >> l1 >> r1 >> l2 >> r2;
if(hs.query(l1,r1) == hs.query(l2,r2)) {
std::cout << "Yes\n";
}
else std::cout << "No\n";
}
}
//简单求整个字符串的哈希值
const ull mod = 212370440130137957;
ull hs(string &s){ // 0_idx
ull ans = 0;
for(auto &x:s){
ans = (ans*131+x)%mod;
}
return ans;
}
双哈希
单哈希如大模数哈希/自然溢出哈希仍然可能会被hack 使用两个模数进行哈希得出两个不同哈希值,减少冲突概率
//常用模数取值 1e9+7 ull自然溢出 212370440130137957 1111111111111111111 //19个1 (1LL << 31) - 1 998244353
//字符串哈希 数据加强版 https://www.luogu.com.cn/problem/U461211
//诺TLE,则尽量开固定数组且预处理p[]和p2[],减小常数
//query(l,r)返回子串s[l~r]的哈希值
namespace Hash{
const unsigned long long base = 131,mod = 1e9+7;
std::vector<unsigned long long>p(1,1),p2(1,1);
template<typename T>
struct hx{ //单哈希 hx hs(s);
std::vector<unsigned long long>h;
hx(){}
hx(const T &s){
init(s.size());
h = std::vector<unsigned long long>(s.size()+1);
for(int i = 0;i < s.size();i++){
h[i+1] = h[i] * base + s[i];
}
}
unsigned long long query(int l,int r){
return h[r+1] - h[l]*p[r-l+1];
}
void init(int id){
while(p.size() <= id){
p.emplace_back(p.back()*base);
}
}
};
template<typename T>
struct hx2{//双哈希 hx2 hs(s);
std::vector<unsigned long long>h,h2;
hx2(){}
hx2(const T &s){
int n = s.size();
init(s.size());
h.resize(n+1);h2.resize(n+1);
for(int i = 0;i < s.size();i++){
h[i+1] = h[i]*base + s[i];
h2[i+1] = (h2[i]*base + s[i]) % mod;
}
}
std::pair<unsigned long long,unsigned long long> query(int l,int r){
unsigned long long k1 = h[r+1] - h[l]*p[r-l+1];
unsigned long long k2 = (h2[r+1] - h2[l]*p2[r-l+1]%mod + mod) % mod;
return std::pair{k1,k2};
}
void init(int id){
while(p.size() <= id){
p.emplace_back(p.back()*base);
p2.emplace_back(p2.back()*base%mod);
}
}
};
};
using Hash::hx,Hash::hx2;
KMP
一个模式串匹配一个/多个文本串
能够在线性时间内判定字符串 A[1~N] 是否为字符串 B[1~M] 的子串,并求出字符串A在字符串B中各次出现的位置。能比字符串哈希更高效准确地处理这个问题,并且能提供一些额外的信息
next[i]数组求的是子串s[1~i]的最长border(真前缀==真后缀)
//下标从1开始
#include <iostream>
using namespace std;
const int N = 1000006;
int ne[N],f[N];
int main(){
string a,b;
int n,m;
cin >> n >> a >> m >> b;
a = ' ' + a;b = ' ' +b;
ne[0] = 0;
for(int i = 2,j = 0;i <= n;i++){//自身匹配,i从2开始
while(j > 0 && a[i] != a[j+1]) j = ne[j];
if(a[i] == a[j+1]) j++;
ne[i] = j;
}
for(int i = 1,j = 0;i <= m;i++){//对目标字符串匹配,求a在b的所有出现下标
while(j > 0 && b[i] != a[j+1]) j = ne[j];
if(b[i] == a[j+1]) j++;
f[i] = j;//f[i]表示文本串以b[i]结尾的子串的后缀和模式串的前缀的最长匹配长度
if(f[i] == n){ cout << i - n << ' '; }
}
}
//https://vjudge.net/problem/HDU-1711
#include <iostream>
#include <vector>
template<typename T>
struct KMP{
T a;
std::vector<int> ne;
KMP(){}
KMP(const T&v){ init(v); }
void init(const T&v){//1_idx
a = v;
ne.assign(a.size(),{});
for(int i = 2,j = 0;i < a.size();i++){
while(j > 0 && a[i] != a[j+1]) j = ne[j];
if(a[i] == a[j+1]) j++;
ne[i] = j;
}
}
std::vector<int> kmp(const T&b){
std::vector<int>ans;
for(int i = 1,j = 0;i < b.size();i++){
while(j > 0 && b[i] != a[j+1]) j = ne[j];
if(b[i] == a[j+1]) j++;
//f[i] = j;
if(j == a.size()-1) ans.push_back(i-a.size()+2);//此处再令j=0,即为求不可重复的匹配
}
return ans;
}
};
void sol(){
int n,m; std::cin >> n >> m;
std::vector<int>a(n+1),b(m+1);
for(int i = 1;i <= n;i++){ std::cin >> a[i]; }
for(int i = 1;i <= m;i++){ std::cin >> b[i]; }
KMP<std::vector<int>> kmp(b);
auto ans = kmp.kmp(a);//求a中出现模版串的所有下标
if(ans.size()) std::cout << ans[0] << '\n';
else std::cout << -1 << '\n';
}
int main(){
std::ios::sync_with_stdio(false);std::cin.tie(0);
int t; std::cin >> t;
while(t--) sol();
}
前缀统计
统计每个前缀的出现次数
string s = abab; f(s) = a* 2 + ab*2 + aba + abab = 6
//原题数据较弱 https://acm.hdu.edu.cn/showproblem.php?pid=3336
#include <iostream>
#include <vector>
template<typename T>
struct KMP{ //1_idx
T a;
std::vector<int> ne;
KMP(){}
KMP(const T&v){ init(v); }
void init(const T&v){
a = v;
ne.assign(a.size(),{});
for(int i = 2,j = 0;i < a.size();i++){
while(j > 0 && a[i] != a[j+1]) j = ne[j];
if(a[i] == a[j+1]) j++;
ne[i] = j;
}
}
std::vector<int> kmp(const T&b){
std::vector<int>ans;
for(int i = 1,j = 0;i < b.size();i++){
while(j > 0 && b[i] != a[j+1]) j = ne[j];
if(b[i] == a[j+1]) j++;
//f[i] = j;
if(j == a.size()-1) ans.push_back(i-a.size()+2);
}
return ans;
}
};
const int mod = 10007;
void sol(){
int n; std::cin >> n;
std::string s; std::cin >> s;
s = ' ' + s;
KMP<std::string>t(s);
auto ne = t.ne;
std::vector<int>f(n+1);
for(int i = 1;i <= n;i++) {
f[i] = f[ne[i]] + 1;
}
int ans = 0;
for(int i = 1;i <= n;i++) {
ans = (ans + f[i]) % mod;
}
std::cout << ans << '\n';
}
int main(){
std::ios::sync_with_stdio(false); std::cin.tie(0);
int t; std::cin >> t;
while(t--) sol();
}
循环节
字符串的循环节
诺字符串S可以由子串A循环而成,则子串A是S的周期,如S = “abababab”,则周期=ab 、abab
如果(ne[i] > 0 && i%[i-ne[i]] == 0),则前缀s[1~i]的最小循环节k = i-ne[i]
//https://www.acwing.com/problem/content/143/
//给定字符串s,求具有循环节的前缀长度i和其最小循环节对应的循环次数
#include <iostream>
using namespace std;
const int N = 1000006;
int ne[N];
int main(){
int n,idx = 0;;
while(cin >> n,n){
cout << "Test case #" << ++idx << endl;
string s;cin >> s;
s = ' ' + s;
for(int i = 2,j = 0;i <= n;i++){
while(j > 0 && s[i] != s[j+1]) j = ne[j];
if(s[i] == s[j+1]) j++;
ne[i] = j;
}
for(int i = 1;i <= n;i++){
if(ne[i] && i%(i-ne[i]) == 0){
cout << i << ' ' << i/(i-ne[i]) << endl;//子串s[1~i]的最短循环节循环的次数
}
}
cout << endl;
}
}
最长公共子串
求多个字符串的最长公共子串
二分+KMP
//https://vjudge.net/problem/HDU-2328
//求长公共子串,诺不唯一,输出字典序最小的
#include <iostream>
#include <algorithm>
#include <vector>
template<typename T>
struct KMP{ //1_idx
T a;
std::vector<int> ne;
KMP(){}
KMP(const T&v){ init(v); }
void init(const T&v){
a = v;
ne.assign(a.size(),{});
for(int i = 2,j = 0;i < a.size();i++){
while(j > 0 && a[i] != a[j+1]) j = ne[j];
if(a[i] == a[j+1]) j++;
ne[i] = j;
}
}
std::vector<int> kmp(const T&b){
std::vector<int>ans;
for(int i = 1,j = 0;i < b.size();i++){
while(j > 0 && b[i] != a[j+1]) j = ne[j];
if(b[i] == a[j+1]) j++;
//f[i] = j;
if(j == a.size()-1) {
ans.push_back(i-a.size()+2);
return ans;//匹配成功一次直接返回即可
}
}
return ans;
}
};
const int N = 4003;
int n;
std::string s[N];
std::string ans;
bool check(int len){
bool ok = 0;
for(int i = 1;i+len-1 < s[1].size();i++){
auto now = s[1].substr(i,len);
if(ok && (ans <= now)) continue;//剪枝
KMP<std::string>t(' ' + now);
bool flag = 1;
for(int j = 2;j <= n;j++){
if(t.kmp(s[j]).empty()) {
flag = 0;
break;
}
}
if(flag) {
ok = 1;
if(ans.size() < now.size()) ans = now;
else if(ans.size() == now.size()) ans = std::min(ans,now);
}
}
return ok;
}
void sol(){
ans = "";
int mn = N,p = 1;
for(int i = 1;i <= n;i++) {
std::cin >> s[i];
if(s[i].size() < mn) {
mn = s[i].size();
p = i;
}
s[i] = ' ' + s[i];
}
std::swap(s[1],s[p]);
int l = 0,r = mn;
while(l < r){
int mid = l + r + 1 >> 1;
if(check(mid)) l = mid;
else r = mid - 1;
}
if(ans.size()) std::cout << ans << '\n';
else std::cout << "IDENTITY LOST\n";
}
int main(){
std::ios::sync_with_stdio(false); std::cin.tie(0);
while(std::cin >> n,n) sol();
}
exKMP
也被称之为 $Z Algorithm$ 或 $扩展KMP$ 。
对于一个长度为n的字符串s(1_idx),定义z[i]表示s和s[i,n](即以s[i]开头的后缀)的最长公共前缀,我们将z称之为s的z函数。考虑到z[1]的特殊性质,一般将其设置为z[1]=0。 例如z("aaaba") = {0,2,1,0,1}。
时间复杂度$O(N)$
template<typename T>
struct EXKMP{ //1_idx
T a;
std::vector<int>z;
EXKMP(){}
EXKMP(const T&v){ init(v); }
void init(const T &v) {
a = v;
z = std::vector<int>(a.size());
for(int i = 2,k = 1;i < a.size();i++){
if(k+z[k]-i <= z[i-k+1]) {
z[i] = k+z[k]-i;
if(z[i] < 0) z[i] = 0;
while(i+z[i] < a.size() && a[z[i]+1] == a[z[i]+i]) ++z[i];
k = i;
}
else{
z[i] = z[i-k+1];
}
}
z[1] = 0; //or a.size()-1?
}
std::vector<int> exkmp(const T&v){//ans[i]表示v的后缀子串v.substr(i)与字符串a的最长公共前缀
std::vector<int>ans(v.size());
for(int i = 1,k = 1;i < v.size();i++){
if(k+ans[k]-i <= z[i-k+1]) {
ans[i] = k+ans[k]-i;
if(ans[i] < 0) ans[i] = 0;
while(i+ans[i] < v.size() && ans[i] < a.size() && a[ans[i]+1] == v[ans[i]+i]) ++ans[i];
k = i;
}
else{
ans[i] = z[i-k+1];
}
}
return ans;
}
};
Trie字典树
高效地存储和查找字符串集合的数据结构

字符串统计
#include <iostream>
#include <cstring>
namespace TRIE{//0_idx
const int N = 100005,M = 26;//max_s.length
int son[N][M],cnt[N],idx;
struct Trie{
Trie(){idx = 0;init(idx);}
void init(int p){
cnt[p] = 0;
memset(son[p], 0, sizeof(son[p]));
}
int get(char x){//
if(x >= 'a' && x <= 'z') return x - 'a';
if(x >= 'A' && x <= 'Z') return x - 'A' + 26;
if(x >= '0' && x <= '9') return x - '0' + 52;
return -1;
}
void insert(const std::string &s){
int p = 0;
for(int i = 0;i < s.size();i++){
int u = get(s[i]);
if(!son[p][u]) {
son[p][u] = ++idx;
init(idx);
}
p = son[p][u];
//cnt[p]++; //前缀++
}
cnt[p]++; //字符串++;
}
int query(const std::string &s){
int p = 0;
for(int i = 0;i < s.size();i++){
int u = get(s[i]);
if(!son[p][u]) return 0;
p = son[p][u];
}
return cnt[p];
}
};
};
using TRIE::Trie;
int main(){
Trie t;
int q; std::cin >> q;
while(q--){
char op; std::string s;
std::cin >> op >> s;
if(op == 'I') { t.insert(s); }
else { std::cout << t.query(s) << '\n'; }
}
}
前缀统计
给定 N 个字符串 $S_1,S_2…S_N$,接下来进行 M 次询问,每次询问给定一个字符串 T,求 $S_1∼S_N$ 中多少个字符串是 T 的前缀。
//https://www.acwing.com/problem/content/144/
#include <iostream>
#include <cstring>
namespace TRIE{//0_idx
const int N = 1000006,M = 26;//max_s.length
int son[N][M],cnt[N],idx;
struct Trie{
Trie(){init();}
void init(){
idx = cnt[0] = 0;
memset(son[0], 0, sizeof(son[0]));
}
int get(char x){
if(x >= 'a' && x <= 'z') return x - 'a';
if(x >= 'A' && x <= 'Z') return x - 'A' + 26;
if(x >= '0' && x <= '9') return x - '0' + 52;
return 0;
}
void insert(const std::string &s){
int p = 0;
for(int i = 0;i < s.size();i++){
int u = get(s[i]);
if(!son[p][u]) {
son[p][u] = ++idx;
cnt[idx] = 0;
std::memset(son[idx],0,sizeof son[idx]);
}
p = son[p][u];
//cnt[p]++; //suff++
}
cnt[p]++; //string++;
}
int query(const std::string &s){
int ans = 0;
int p = 0;
for(int i = 0;i < s.size();i++){
int u = get(s[i]);
if(!son[p][u]) return ans;
p = son[p][u];
ans += cnt[p];
}
// return cnt[p];
return ans;
}
};
};
using TRIE::Trie;
int main(){
Trie t;
int n,q; std::cin >> n >> q;
while(n--){
std::string s; std::cin >> s;
t.insert(s);
}
while(q--){
std::string s; std::cin >> s;
std::cout << t.query(s) << '\n';
}
}
给定 N 个字符串 $S_1,S_2…S_N$,接下来进行 M 次询问,每次询问给定一个字符串 T,求 $S_1∼S_N$ 中 T 是多少个字符串的前缀
//https://www.luogu.com.cn/problem/P8306
#include <iostream>
#include <cstring>
namespace TRIE{//0_idx
const int N = 3000006,M= 70;//max_s.length
int son[N][M],cnt[N],idx;
struct Trie{
Trie(){init();}
void init(){
cnt[0] = 0;
memset(son[0], 0, sizeof(son[0]));
idx = 0;
}
int get(char x){
if(x >= 'a' && x <= 'z') return x - 'a';
if(x >= 'A' && x <= 'Z') return x - 'A' + 26;
if(x >= '0' && x <= '9') return x - '0' + 52;
return 0;
}
void insert(const std::string &s){
int p = 0;
for(int i = 0;i < s.size();i++){
int u = get(s[i]);
if(!son[p][u]) {
son[p][u] = ++idx;
cnt[idx] = 0;
std::memset(son[idx],0,sizeof son[idx]);
}
p = son[p][u];
cnt[p]++;
}
}
int query(const std::string &s){
int p = 0;
for(int i = 0;i < s.size();i++){
int u = get(s[i]);
if(!son[p][u]) return 0;
p = son[p][u];
}
return cnt[p];
}
};
};
using TRIE::Trie;
void sol(){
Trie t;
int n,q; std::cin >> n >> q;
while(n--){
std::string s; std::cin >> s;
t.insert(s);
}
while(q--){
std::string s; std::cin >> s;
std::cout << t.query(s) << '\n';
}
}
int main(){
std::ios::sync_with_stdio(false); std::cin.tie(0);
int t; std::cin >> t;
while(t--) sol();
}
最大异或对
在给定的 𝑁 个整数 𝐴1,𝐴2……𝐴𝑁 中选出两个进行 𝑥𝑜𝑟(异或)运算,得到的结果最大是多少?
//https://www.luogu.com.cn/problem/P10471
#include <iostream>
#include <cstring>
namespace TRIE{//0_idx
const int N = 100005*32;
int son[N][2],cnt[N],idx;
struct Trie{
Trie(){init();}
void init(){
idx = cnt[0] = 0;
memset(son[0], 0, sizeof(son[0]));
}
int get(char x){
if(x >= 'a' && x <= 'z') return x - 'a';
if(x >= 'A' && x <= 'Z') return x - 'A' + 26;
if(x >= '0' && x <= '9') return x - '0' + 52;
return 0;
}
void insert(const int &x){
int p = 0;
for(int i = 30;i >= 0;i--){
bool u = x >> i & 1;
if(!son[p][u]) {
son[p][u] = ++idx;
cnt[idx] = 0;
std::memset(son[idx],0,sizeof son[idx]);
}
p = son[p][u];
}
cnt[p]++;
}
int query(const int &x){
int ans = 0;
int p = 0;
for(int i = 30;i >= 0;i--){
bool u = x >> i & 1;
if(son[p][!u]) {//高位开始,每次找与当前位相反的
ans = ans<<1|1;
p = son[p][!u];
}
else{
ans = ans<<1;
p = son[p][u];
}
}
return ans;
}
};
};
using TRIE::Trie;
int main(){
Trie t;
int n; std::cin >> n;
int ans = 0;
while(n--){
int x; std::cin >> x;
ans = std::max(ans,t.query(x));
t.insert(x);
}
std::cout << ans;
}
给定一棵 n 个点的带边权树,求树中最大的异或路径值。
思路:设d[x]表示根节点到x的路径异或值,则有d[x] = d[father[x]] ^ weight(x,father[x]),DFS一遍可以求出所有d[i],x到y的路径异或值就等于d[x]^d[y] (x到根 和 y到根,重叠部分异或抵消了,就相当于x到y),问题就变为d[N]中求最大异或对
#include <iostream>
#include <cstring>
using namespace std;
const int N = 200005;
int n;
int a[N];
int h[N],ne[N],e[N],w[N],idx;
int son[N*32][2],tot;
int d[N];
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dfs(int u,int fa){
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(k != fa){
d[k] = d[u] ^ w[i];
dfs(k,u);
}
}
}
void insert(int x){
int p = 0;
for(int i = 31;i >= 0;i--){
bool u = x >> i & 1;
if(!son[p][u]) son[p][u] = ++tot;
p = son[p][u];
}
}
int query(int x){
int p = 0;
int ans = 0;
for(int i = 31;i >= 0;i--){
bool u = x >> i & 1;
if(son[p][!u]) {
ans = ans*2 + 1;
p = son[p][!u];
}
else{
ans = ans*2;
p = son[p][u];
}
}
return ans;
}
int main(){
memset(h,-1,sizeof h);
cin >> n;
for(int i = 1;i < n;i++){
int a,b,c;cin >> a >> b >> c;
add(a,b,c);
add(b,a,c);
}
dfs(1,1);
int ans = 0;
for(int i = 1;i <= n;i++){
ans = max(ans,query(d[i]));
insert(d[i]);
}
cout << ans;
}
AC自动机
多个模式串匹配一个/多个文本串

-
构建Trie前缀树
-
构建失配指针:状态 $u$ 的 faile指针 指向另一个状态 $v$ ,其中 $v\in Trie$ ,且 $v$ 是 $u$ 的最长后缀(即在诺干个后缀状态中取最长的一个作为 fail指针)。
-
查询文本串:例如,当前要匹配的文本串为
shers,在字典树上找到状态9:she时,此时无后续节点,失配,直接跳转到状态9:she的最长后缀状态2:he,然后继续匹配。
//模版题 AC自动机(简单版) https://www.luogu.com.cn/problem/P3808
//给定n个模式串和一个文本串,求文本串中出现了多少个模式串
#include <iostream>
#include <queue>
#include <cstring>
namespace ACAM{//0_idx
const int N = 1000006, M = 26;//N:所有模式串的总长度
int son[N][M],cnt[N],fail[N],idx;
struct Trie{
Trie(){idx = 0;init(idx);}
void init(int p){
fail[p] = cnt[p] = 0;
std::memset(son[p], 0, sizeof(son[p]));
}
int get(char x){
if(x >= 'a' && x <= 'z') return x - 'a';
if(x >= 'A' && x <= 'Z') return x - 'A' + 26;
if(x >= '0' && x <= '9') return x - '0' + 52;
return -1;
}
void insert(const std::string &s){
int p = 0;
for(int i = 0;i < s.size();i++){
int u = get(s[i]);
if(!son[p][u]) {
son[p][u] = ++idx;
init(idx);
}
p = son[p][u];
}
cnt[p]++;
}
void get_fail(){//构建失配指针
fail[0] = 0;
std::queue<int>q;
for(int i = 0;i < M;i++){//第二层的fail全部指向根节点
if(son[0][i]) {
fail[son[0][i]] = 0;
q.push(son[0][i]);
}
}
while(q.size()){
int p = q.front();
q.pop();
for(int u = 0;u < M;u++){
if(son[p][u]) {//如果子节点存在
fail[son[p][u]] = son[fail[p]][u];//子节点的fail指针指向当前节点的fail指针指向的相同子节点
q.push(son[p][u]);//子节点入队
}
else {//如果子节点不存在
son[p][u] = son[fail[p]][u];//直接让子节点指向当前节点的fail指针指向的相同子节点
}
}
}
}
int query(const std::string &s){
int p = 0,ans = 0;
for(int i = 0;i < s.size();i++){
int u = get(s[i]);
p = son[p][u];//依次读入单词,然后指针跳转到子节点
ans += cnt[p];
cnt[p] = 0;
// for(int t = p;t && cnt[t] != -1;t = fail[t]){//不断跳失配指针并沿路统计答案
// ans += cnt[t];
// cnt[t] = -1;//清空,本题出现多次只算一次,诺多文本串匹配,可以开个vis数组标记状态t
// }
}
return ans;
}
};
};
using ACAM::Trie; //Trie t;
int main(){
Trie t;
int n; std::cin >> n;
std::string s;
for(int i = 1;i <= n;i++){
std::cin >> s;
t.insert(s);
}
t.get_fail();
std::cin >> s;
std::cout << t.query(s) << '\n';
}
拓扑排序优化
fail 指针的一个性质:一个 AC 自动机中,如果只保留 fail 边,那么剩余的图一定是一棵树。这样 AC 自动机的匹配就可以转化为在 fail 树上的链求和问题
观察到时间主要浪费在在每次都要跳 fail。如果我们可以预先记录,最后一并求和,那么效率就会优化。
于是我们按照 fail 树,做一次内向树上的拓扑排序,就能一次性求出所有模式串的出现次数。
//https://www.luogu.com.cn/problem/P5357
//给定n个模式串和一个文本串,分别求出每个模式串在文本串中出现的次数(可重叠)
#include <bits/stdc++.h>
using namespace std;
int id;
std::vector<int>vis,mp;
namespace ACAM{//0_idx
const int N = 200005, M = 26;
int son[N][M],cnt[N],fail[N],idx;
int du[N],ans[N];
struct Trie{
Trie(){idx = 0;init(idx);}
void init(int p){
ans[p] = du[p] = 0;
fail[p] = cnt[p] = 0;
std::memset(son[p], 0, sizeof(son[p]));
}
int get(char x){
if(x >= 'a' && x <= 'z') return x - 'a';
if(x >= 'A' && x <= 'Z') return x - 'A' + 26;
if(x >= '0' && x <= '9') return x - '0' + 52;
return -1;
}
void insert(const std::string &s){
int p = 0;
for(int i = 0;i < s.size();i++){
int u = get(s[i]);
if(!son[p][u]) {
son[p][u] = ++idx;
init(idx);
}
p = son[p][u];
}
if(!cnt[p]) cnt[p] = id;//状态p对应字符串id+去重
mp[id] = cnt[p];//字符串id对应状态p的id
}
void get_fail(){
std::queue<int>q;
for(int i = 0;i < M;i++){
if(son[0][i]) {
fail[son[0][i]] = 0;
q.push(son[0][i]);
}
}
while(q.size()){
int p = q.front();
q.pop();
for(int u = 0;u < M;u++){
if(son[p][u]) {
fail[son[p][u]] = son[fail[p]][u];
du[son[fail[p]][u]]++;//额外记录入度
q.push(son[p][u]);
}
else {
son[p][u] = son[fail[p]][u];
}
}
}
}
int query(const std::string &s){
int p = 0;
for(int i = 0;i < s.size();i++){
int u = get(s[i]);
p = son[p][u];
ans[p]++;
}
topu();
return 0;
}
void topu(){//拓扑排序统计答案
std::queue<int>q;
for(int i = 1;i <= idx;i++){
if(!du[i]) q.push(i);//入度为零的点,必定是一个 Fail 链的末尾
}
while(q.size()){
int p = q.front();
q.pop();
vis[cnt[p]] = ans[p];
ans[fail[p]] += ans[p];
if(!--du[fail[p]]) q.push(fail[p]);
}
}
};
};
using ACAM::Trie; //Trie t;
const int N = 200005;
std::string s[N];
int main(){
Trie t;
int n; std::cin >> n;
vis = mp = std::vector<int>(n+1,0);
for(int i = 1;i <= n;i++){
std::cin >> s[i];
id = i;
t.insert(s[i]);
}
t.get_fail();
std::cin >> s[0];
t.query(s[0]);
for(int i = 1;i <= n;i++){
std::cout << vis[mp[i]] << '\n';
}
}
回文串
Manacher
O(N)求得对于每个i的最长回文长度,这里下标从0开始
t = "abbba" 则对应s = " #a#b#b#b#a#",可以同时处理奇偶回文串,而不必分开讨论,对s求得d1[ ]
d1[i]为以s[i]为中心的最长回文串长度。
对于t[i]来说,d1[i*2]-1 即为以i为中心,最长的奇数长度回文串
d1[i*2+1]-1即为以(i,i+1)中点为中心最长的偶数长度回文串
//https://www.luogu.com.cn/problem/P3805
//模版题,给定字符串,求最长的回文子串长度
template<typename T>
struct Manacher{ //1_idx
int n,ans;
T s;
std::vector<int>d;
Manacher(){}
Manacher(const T &v){
init(v);
}
void init(const T &v){
s = " #";
for(int i = 1;i < v.size();i++){
s += v[i];
s += '#';
}
n = s.size()-1;
d = std::vector<int>(n+1,0);
ans = 0;
for(int i = 1,l = 0,r = 0;i <= n;i++){
if(i > r) d[i] = 1;
else d[i] = std::min(d[l*2-i],r-i+1);
while(i-d[i] >= 1 && i+d[i] <= n && s[i-d[i]] == s[i+d[i]]) d[i]++;
if(i+d[i]-1 > r) l = i,r = i+d[i]-1;
ans = std::max(ans,d[i]-1); //减去加入的'#'
}
}
bool query(int l,int r){ //查询区间是否为回文串
l <<= 1,r <<= 1;
int mid = l + r >> 1;
return d[mid]-1 >= r-mid;
}
};
int main(){
std::string s;
std::cin >> s;
Manacher t(s);
std::cout << t.ans;
}
最小表示法
求s的循环同构中字典序最小,且下标最小的一个
时间复杂度$O(N)$
//https://www.luogu.com.cn/problem/P1368
#include <iostream>
#include <vector>
template<typename T>
int get_min(T a){//1_idx
int n = a.size()-1;
for(int i = 1;i <= n;i++) a.push_back(a[i]);
int i = 1,j = 2;
while(i <= n && j <= n){
int k = 0;
while(k < n && a[i+k] == a[j+k]) k++;
if(k == n) break;
if(a[i+k] > a[j+k]) {//诺将符号取反即为最大表示法
i += k+1;//诺a[i+k]>a[j+k],则a[i]~a[i+k]>a[j]
if(i == j) i++;//保持i != j
}
else {//a[j]同理
j += k+1;
if(i == j) j++;
}
}
return std::min(i,j);
}
int main(){
int n; std::cin >> n;
std::vector<int>a(n+1);
for(int i = 1;i <= n;i++){
scanf("%d",&a[i]);
}
int id = get_min(a);
for(int i = 0;i < n;i++){
printf("%d ",a[(id+i-1)%n+1]);
}
}
//https://acm.hdu.edu.cn/showproblem.php?pid=2609
//诺两个字符串具有的循环同构,则称两个字符串本质相同,求本质不同的字符串的有多少种
//思路:将每个字符串的最小表示法用set/map存起来,最后容器的大小即为答案
后缀数组
这里假定字符串长度为n,下标从1开始。“后缀i”表示以第i个字符开头的后缀,储存时用i表示字符串s的后缀s[i…n]。
后缀数组sa[i]表示将所有后缀排序后,第i小的后缀的编号。
排名数组rk[i]表示后缀i的排名,重要的辅助数组。
这两个数组满足性质:sa[rk[i]] = rk[sa[i]] = i。
height数组height[i],即lcp(sa[i],sa[i-1])
 后缀数组示例
后缀数组示例
P10469 后缀数组 - 洛谷 (luogu.com.cn)
排序+哈希+二分
时间复杂度$O(nlog^2n)$
#include <iostream>
#include <algorithm>
using namespace std;
const unsigned long long base = 131;
const int N = 300005;
int n;
string s;
int sa[N],rk[N];
unsigned long long hs[N],p[N];
void init(string &s){
hs[0] = 0;
p[0] = 1;
for(int i = 0;i < s.size();i++){
p[i+1] = p[i] * base;
hs[i+1] = hs[i] * base + s[i];
}
}
unsigned long long query(int l,int r){
return hs[r] - hs[l-1]*p[r-l+1];
}
int lcp(int x,int y){//二分查找后缀x和后缀y的最长公共前缀
int l = 0,r = min(n-x+1,n-y+1);
while(l < r){
int mid = l + r + 1 >> 1;
if(query(x,x+mid-1) == query(y,y+mid-1)) l = mid;
else r = mid - 1;
}
return l;
}
bool cmp(int x,int y){
int len = lcp(x,y);
return s[x+len] < s[y+len];//s[x+len]和s[y+len]即为第一个不同的位置
}
int main(){
cin >> s; n = s.size();
init(s);
s = ' ' + s;
for(int i = 1;i <= n;i++) sa[i] = i;
stable_sort(sa+1,sa+n+1,cmp);
for(int i = 1;i <= n;i++){
cout << sa[i] - 1 << ' '; //sa[] 本题下标从0开始,减1即可
rk[sa[i]] = i;//rk[]
}
cout << '\n';
for(int i = 1;i <= n;i++){
cout << lcp(sa[i],sa[i-1]) << ' ';//height[]
}
}
倍增实现
时间复杂度$O(NlogN)$
//https://www.luogu.com.cn/problem/P10469
#include <bits/stdc++.h>
namespace SA{//1_idx 未验证多测是否正确初始化
int n;
std::vector<int>sa,c,x,y,rk,height;
template<typename T>
void build (const T &s) {//get:sa[]
sa = x = y = std::vector<int>(n+1);
int m = 300;//字符值域
c.resize(std::max(n,m)+1);
for (int i = 1; i <= m; i++) c[i] = 0;
for (int i = 1; i <= n; i++) c[x[i] = s[i]]++;
for (int i = 1; i <= m; i++) c[i] += c[i-1];
for (int i = n; i >= 1; i--) sa[c[x[i]]--] = i;
for (int j = 1; j <= n; j <<= 1) {
int p = 0;
for (int i = n - j + 1; i <= n; i ++) y[++p] = i;
for (int i = 1; i <= n; i++) if (sa[i] > j) y[++p] = sa[i] - j;
for (int i = 1; i <= m; i++) c[i] = 0;
for (int i = 1; i <= n; i++) c[x[y[i]]]++;
for (int i = 1; i <= m; i++) c[i] += c[i-1];
for (int i = n; i >= 1; i--) sa[c[x[y[i]]]--] = y[i];
std::swap (x, y);
p = 1;
x[sa[1]] = 1;
for (int i = 2; i <= n; i ++) {
x[sa[i]] = y[sa[i-1]] == y[sa[i]] && y[sa[i-1]+j] == y[sa[i]+j] ? p : ++p;
}
if (p >= n) break;
m = p;
}
}
template<typename T>
void make (const T &s) {//get:rk[],height[]
rk = height = std::vector<int>(n+1);
int k = 0;
for (int i = 1; i <= n; i ++) rk[sa[i]] = i;
for (int i = 1; i <= n; i ++) {
if (rk[i] == 1) continue;
if (k) k --;
int j = sa[rk[i] - 1];
while (j + k <= n and i + k <= n and s[i + k] == s[j + k]) {
++ k;
}
height[rk[i]] = k;
}
}
template<typename T>
std::vector<int> get_sa(const T &s){
n = s.size()-1;
build(s);
make(s);
return sa;
}
}
using SA::get_sa,SA::sa,SA::rk,SA::height;
int main () {
std::string s; std::cin >> s; s = ' ' + s;
int n = s.size()-1;
get_sa(s);
for(int i = 1;i <= n;i++){ std::cout << sa[i]-1 << ' '; }
std::cout << '\n';
for(int i = 1;i <= n;i++){ std::cout << height[i] << ' '; }
}
height数组
lcp为最长公共前缀,下文以lcp(i,j)表示后缀i和后缀j的最长公共前缀。
height[ ]数组的定义:height[i] = lcp(sa[i],sa[i-1]),即第i名的后缀与它前一名的后缀的最长公共前缀。height[1]可以视作0。
一些应用
两子串最长公共前缀
lcp(sa[i],sa[j]) = min({height[i+1...j]})如果
height一直大于某个数,前这么多位就一直没变过;反之,由于后缀已经排好序了,不可能之后变回来。 求两子串的最长公共前缀就转化为了RMQ问题。
比较两子串的大小关系 假设比较的子串为
A = s[a,b]和B = s[c,d]若 $lcp(a, c)\ge\min(|A|, |B|)$,$A<B\iff |A|<|B|$。 否则,$A<B\iff rk[a]< rk[c]$。
求字符串循环同构的字典序排名
[P4051 JSOI2007] 字符加密 - 洛谷 (luogu.com.cn) 将s复制一遍后,求sa[ ]
求不同子串的数目
P2408 不同子串个数 - 洛谷 (luogu.com.cn) 每个子串一定是某个后缀的前缀,所以可以计算子串总数,枚举每个后缀,减掉重复。 \(答案为:\frac{n(n+1)}{2} - \sum_{i=2}^{n}{height[i]}\)
求至少出现k次的子串(可重叠)的最大长度
[P2852 USACO06DEC] Milk Patterns G - 洛谷 (luogu.com.cn) 出现至少k次意味着后排序后,有至少连续k个后缀以这个子串作为公共前缀。 所以求出每相邻k-1个height的最小值,这些最小值的最大值即为答案,这里可以用单调队列O(n)解决
结合并查集/线段树/单调栈等数据结构
其它
求字符串S中长度为k的子序列中,字典序最小的一个。$1 \le K \le N \le 10^5$
贪心实现,依次考虑子序列的每一位,从合法区间[l,r]中选择字典序最小的一个字母,选择该字母后,该字母前面的字母都不能选,于是我们可以不断缩小合法区间。
//https://vjudge.net/problem/AtCoder-typical90_f#author=GPT_zh
#include <iostream>
#include <queue>
using namespace std;
int n,k;
string s;
queue<int>q[30];
int main(){
cin >> n >> k >> s;
for(int i = 0;i < s.size();i++){
q[s[i]-'a'].emplace(i);
}
int l = 0;
string ans;
for(int i = 0;i < k;i++){
int r = n - k + i;//右端点必须小于r,否则凑不齐长度k的序列
for(int c = 0;c < 26;c++){
while(q[c].size() && q[c].front() < l){//左端点l前面的字母都可以排除
q[c].pop();
}
if(q[c].empty()) continue;
if(q[c].front() <= r){//选择该位后,缩小左端点
ans += 'a' + c;
l = q[c].front();
q[c].pop();
break;
}
}
}
cout << ans;
}
给定一个长度为N的字符串S,求有多少个的子序列 = 字符串T。
设dp[i]为T的前i个前缀出现的次数,时间复杂度$O(NM)$
//https://vjudge.net/problem/AtCoder-typical90_h#author=GPT_zh
#include <bits/stdc++.h>
using namespace std;
const int N = 200005,mod = 1e9+7;
string t = " atcoder";
int a[N];
long long dp[5];
int main(){
int n;cin >> n;
int m = t.size()-1;
string s;cin >> s;s = ' ' + s;
dp[0] = 1;
for(int i = 1;i <= n;i++){
for(int j = 1;j <= m;j++){
if(s[i] == t[j]){
dp[j] = (dp[j] + dp[j-1])%mod;
}
}
}
cout << dp[m] << '\n';
}
图论
图论部分简介 - OI Wiki (oi-wiki.org)
作图工具Graph Editor (csacademy.com)
树和图的存储
邻接矩阵
空间复杂度n^2,适合存储稠密图,可以快速查询一条边是否存在
int arr[N][N];
void add(int a,int b){
arr[a][b] = x;//无权值则x为bool值代表是否连通,有权值则x为权值
}
//单向 add(a,b);
//双向 add(b,a);
邻接表
适合存稀疏图,不支持随机访问
初始 h[u] -> -1 add(u,1) h[u] -> 1 -> -1 add(u,2) h[u] -> 2 -> 1 -> -1 add(u,3) h[u] -> 3 -> 2 -> 1 -> -1
//数组模拟链表实现 ---推荐
//诺为无向图,则边i和边i^1互为一条反边
int h[N], e[M], ne[M], idx;
//存边
void add(int a, int b) {
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
//遍历边
for(int i = h[x];i != -1;i = ne[i]){
int k = e[i];
cout << k << ' ';
}
int main() {
memset(h, -1, sizeof h);//注意h需要初始化为-1
}
//STL vector实现
//在内存和时间上都比数组模拟链表能差,可能被卡时间
vector<int>e[N];
void add(int a, int b) {//存边
e[a].push_back(b);
}
//遍历边
for(int i = 0;i < v[x].size();i++){
cout << v[x][i] << ' ';
}
//STL list实现 由于内存不连续遍历不如vector但支持删除操作
list<int>e[N];
//存边
void add(int a, int b) {
e[a].push_back(b);
}
//遍历边
for(int &k:e[u]){
cout << k << " ";
}
树和图的遍历
| 二叉树的遍历 | |
|---|---|
| 前序遍历 | 根-左-右 |
| 中序遍历 | 左-根-右 |
| 后序遍历 | 左-右-根 |
DFS
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 100010, M = N * 2;
int n;
int h[N], e[M], ne[M], idx;
bool st[N];//存哪些点已经遍历过了
void add(int a, int b) {
e[idx] = b;ne[idx] = h[a];h[a] = idx++;
}
void dfs(int u) {
st[u] = 1;//标记这个点遍历过了
for (int i = h[u]; i != -1;i = ne[i]) {//搜索下一条未被遍历过的条边
int k = e[i];
if (!st[k]) {
dfs(k);
}
}
}
void dfs2(int u,int fa){//(无环图)可以省下一个vis数组
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(k != fa){
dfs2(k,u);
}
}
}
int main() {
memset(h, -1, sizeof h);
dfs(1);
//dfs2(1,0); 诺根节点编号从0开始,则应dfs2(0,-1)
}
//dfs 无向图叶子节点
void dfs(int u,int fa){//u为当前节点,fa为当前节点的父节点
if(q[u].size() == 1 && q[u][0] == fa){
leaf.emplace_back(u);//此时u为叶子节点
}
st[u] = 1;
for(auto &k:q[u]){
if(!st[k]){
dfs(k,u);
st[k] = 1;
}
}
}
DFS序列
void dfs(int u){
d[++p] = u;
st[u] = 1;//每个点第一次被标记为走过时的p即为该点的时间戳
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(!st[k]){
dfs(k);
}
}
d[++p] = u;//每个点来回会被标记两次,最后长度为2*n
}
for(int i = 1;i <= 2*n;i++) cout << d[i] << ' ';
每个节点x的编号在dfs序中恰好出现两次,假设这两次的位置为L[x]和R[x],则闭区间 L[x] ~ R[x] 就是以x为根的子树的dfs序。可以通过dfs序把子树统计转化为序列上的区间统计。例题:线段树维护子树信息Assign the task - HDU 3974 - Virtual Judge (vjudge.net)
 DFS序:1 2 8 8 5 5 2 7 7 4 3 9 9 3 6 6 4 1
DFS序:1 2 8 8 5 5 2 7 7 4 3 9 9 3 6 6 4 1
连通块划分
 对一个森林多次dfs/bfs可以划分出每一棵树,并查集可以达到类似效果
对一个森林多次dfs/bfs可以划分出每一棵树,并查集可以达到类似效果
#include <iostream>
#include <cstring>
using namespace std;
const int N = 100005;
int n,m;
int h[N],e[N],ne[N],idx;
int id[N],cnt;
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dfs(int u){
id[u] = cnt;
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(!id[k]){
dfs(k);
}
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
while(m--){
int a,b;cin >> a >> b;
add(a,b);
add(b,a);
}
for(int i = 1;i <= n;i++){
if(!id[i]){
cnt++;
dfs(i);
}
cout << i << ' ' << id[i] << '\n';
}
}
BFS
//1号点到n号点的最短距离 https://www.acwing.com/problem/content/849/
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int N = 100010;
int n, m;
queue<int>q;//队列实现
int h[N], e[N], ne[N], idx,d[N];//d计算距离
void add(int a,int b) {//插入有向边a→b
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
int bfs() {
q.push(1);
d[1] = 0;
while (q.size()) {
int t = q.front();//取队头
q.pop();
for (int i = h[t]; i != -1;i = ne[i]) {//扩展t
int k = e[i];
if (d[k] == -1) {//如果没走过
d[k] = d[t]+1;//则标记为走过,距离+1
q.push(k);//该点入队
}
}
}
return d[n];
}
int main() {
memset(h, -1, sizeof h);//初始化邻接表指向-1
memset(d, -1, sizeof d);//初始化距离为-1
cin >> n >> m;
while (m--) {
int a, b; cin >> a >> b;
add(a, b);
}
cout << bfs();
}
拓扑排序
在图论中,拓扑排序(Topological Sorting)是一个有向无环图(DAG, Directed Acyclic Graph)的所有顶点的线性序列。且该序列必须满足下面两个条件:
- 每个顶点出现且只出现一次。
- 若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面。

所有入度为0的点都可以作为起点,一个有向无环图至少存在一个入度为0的点,答案一般不唯一

#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int N = 100010;
int n, m;
queue<int>q;
int h[N], e[N], ne[N], idx;
int d[N],arr[N], cnt;//d[N]存每条边的入度,arr[cnt]记录每次入队的点
void add(int a, int b) {
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
bool topsort() {
for (int i = 1; i <= n; i++) {
if (d[i] == 0) {//先将所有入度为0的点入队
q.push(i);
arr[cnt++] = i;
}
}
while (q.size()) {
int t = q.front();//取队头
q.pop();
for (int i = h[t]; i != -1; i = ne[i]) {//拓展t
int k = e[i];
d[k]--;//指向的边度数-1
if (d[k] == 0) {//如果入度为0则入队
q.push(k);
arr[cnt++] = k;
}
}
}
return cnt == n;//不相等说明存在重边或自环
}
int main() {
memset(h, -1, sizeof h);
cin >> n >> m;
while (m--) {
int a, b; cin >> a >> b;
add(a, b);
d[b]++;//b边入度+1
}
if (topsort()) {
for (int i = 0; i < n; i++) {
cout << arr[i] << ' ';
}
}
else cout << -1;
return 0;
}
最短路

记录路径
邻接表用pre[a] = b 表示a是由b过来的,邻接矩阵用pre[i][j] = k
//对于邻接表 https://codeforces.com/problemset/problem/20/C
if(dist[k] > dist[t] + w[i]){
pq.push({dist[y],y});
dist[k] = dist[t] + w[i];
pre[t] = k;//每次更新最短路时记录路径
}
//输出最短路时由终点往前推
for(int i = n;i != 0;i = pre[n]){
cout << i << " ";//此输出为反向,诺要正向输出路径,将i记录下来逆序输出即可
}
//对于邻接矩阵
if(dist[i][j] > dis[i][k] + dist[k][j]){
dist[i][j] > dis[i][k] + dist[k][j];
path[i][j] = k;//更新时记录路径
}
void print(int a,int b){
if(path[a][b] == 0) return;
print(a,path[a][b]);//前半部
cout<< path[a][b] << " ";//输出该点
print(path[a][b],b);//后半部
}
cout << x << ' ';//输出从x到y的最短路,无需逆序输出。
print(x,y);
cout << y;
最短路条数
求最短路有多少条
//https://www.luogu.com.cn/problem/P1144
//初始时cnt[1] = 1;
if(dist[y] > dist[x] + w[i]){
dist[y] = dist[x] + w[i];
pq.push({dist[y],y});
cnt[y] = cnt[x];//更新y节点时,最短路条数继承自x
}
else if(dist[y] == dist[x] + w[i]){
cnt[y] = (cnt[y] + cnt[x]) % mod;//诺有多条则累加
}
诺要求最多同时划分成多少条最短路,他们之间不含公共边。则可以将所有最短路径上的边保留下来,(如何确定一条边是否为最短路:正反图各跑一次,诺起点->a + a->b + b->终点 == 最短路,则边(a,b)为最短路上的一条边),跑最大流即为答案。4264. 规划最短路 - AcWing题库
单源最短路
仅正权边
Dijkstra朴素
适合稠密图,邻接矩阵存 O(n^2)
//https://www.acwing.com/activity/content/problem/content/918/
#include <iostream>
#include <cstring>
using namespace std;
const int N = 510;
int n, m;
int g[N][N];//邻接矩阵存稠密图
int dist[N];//记录每个点距离第一个点的距离
bool st[N];//记录每个点的最短距离是否已经确认
int Dijkstra() {
memset(dist, 0x3f, sizeof dist);//初始化距离为无限大
dist[1] = 0;//第一个点到自身距离为0
for (int i = 0; i < n;i++) {//n个点进行n次迭代
int t = -1;//t存储当前访问的点
for (int j = 1; j <= n;j++) {//从1号点开始到n号点
if (!st[j] && (t == -1 || dist[t] > dist[j]))//t=寻找所有st=0中dist最小的点
t = j;
}
//if(t == n) break;
st[t] = 1;
for (int j = 1; j <= n;j++) {//再用t依次更新每个点所到相邻的点路径值
dist[j] = min(dist[j], dist[t] + g[t][j]);
//min(1~j , 1~t + t~j) d[j]取最短路径值
}
}
if (dist[n] == 0x3f3f3f3f) return -1;//如果第n号点距离为无穷,则不存在最短路
return dist[n];
}
int main() {
memset(g, 0x3f, sizeof g);//求最短,稠密图初始化为无限大
cin >> n >> m;
while (m--) {
int a, b, c; cin >> a >> b >> c;
g[a][b] = min(g[a][b], c);//处理重边,保留最短的一条
}
cout << Dijkstra();
}
Dijkstra堆优化
适合稀疏图 ,优先队列小根堆实现 O(mlogn)
//https://www.acwing.com/problem/content/description/852/
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
using PII = pair<int, int>;//first为距离,队列根据距离排序,second为对应点
const int N = 150005;
int n, m;
priority_queue<PII, vector<PII>, greater<PII>>pq;
int h[N], e[N], ne[N], idx;
int w[N];//存权重
int dist[N];
bool st[N];//如果为true说明这个点的最短路径已经确定
void add(int a, int b, int c) {
w[idx] = c;
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
int Dijkstra() {
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
pq.push({ 0,1 });
while (pq.size()){
auto t = pq.top();//取队头t
pq.pop();
int ver = t.second, distance = t.first;
if (st[ver])continue;//如果距离已经确定,则跳过该点
st[ver] = 1;
for (int i = h[ver]; i != -1;i = ne[i]) {//拓展t
int k = e[i];
if (dist[k] > distance + w[i]) {
dist[k] = distance + w[i];
pq.push({dist[k],k});
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1;//不存在输出-1
return dist[n];
}
int main() {
memset(h, -1, sizeof h);
cin >> n >> m;
while (m--){
int a, b, c; cin >> a >> b >> c;
add(a, b, c);
}
cout << Dijkstra();
}
含负权边
在图中如果存在负环,则从该环上任意一点出发,沿着环重复行走可以使路径总权值无限减小,因此通常意义上的“最短路”在这种情况下是没有定义的(路径长度可以无限小)。然而,根据具体问题的需求,我们仍然可以通过一些方法处理含有负环的最短路问题。
Bellman-Ford
可以解决有边数限制的问题(诺问题允许忽略负环,如限制路径边数时,可以处理负权环)
时间复杂度O(mn) 结构体存边
//https://www.acwing.com/problem/content/855/
//1~n号点,最多经过k条边的最短距离,边权可能为负数
#include <iostream>
#include <cstring>
using namespace std;
const int N = 505, M = 10004;
int n, m, k;//k代表最多经过k条边,诺是没限制k的最短路,则取n-1
int dist[N], backup[N];//backup备份防止串联
struct Edge { int a, b, w; }edges[M];//使用结构体存储
int bellman_ford() {
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
for (int i = 0; i < k; i++) {//k次循环
memcpy(backup, dist, sizeof backup);
for (int j = 0; j < m; j++) {//遍历所有边
int a = edges[j].a, b = edges[j].b, w = edges[j].w;
dist[b] = min(dist[b], backup[a] + w);//使用上一次备份数据防止节点最短距离串联
}
}
return dist[n];
}
int main() {
cin >> n >> m >> k;
for (int i = 0; i < m;i++) {
int a, b, w; cin >> a >> b >> w;
edges[i] = { a,b,w };
}
int k = bellman_ford();
if (k > 0x3f3f3f3f/2) cout << "impossible";//最后一次松弛后可能会在0x3f3f3f3f附近
else cout << k;
}
SPFA
也称为 队列优化的Bellman-Ford
一般O(m),最坏O(mn),邻接表存,队列实现
如果不被卡(
SPFA已经死了.jpg),可以用来替代Dijkstra堆优化版
//https://www.acwing.com/problem/content/853/
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int N = 100005;
int n, m;
int h[N], e[N], ne[N], idx;
int dist[N],w[N];
bool st[N];
void add(int a, int b,int c) {
w[idx] = c, e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
int SPFA() {
memset(dist, 0x3f, sizeof dist);//距离初始化为正无穷
queue<int>q;//队列存最小距离变小的点,再用它扩展到邻接表中其它相邻的点
dist[1] = 0;//起点到自身距离为0
q.push(1);
st[1] = 1;
while (q.size()){
auto t = q.front();
q.pop();
st[t] = 0;//从队列中取出来之后该节点st被标记为false
for (int i = h[t]; i != -1;i = ne[i]) {
int k = e[i];
if (dist[k] > dist[t] + w[i]) {
dist[k] = dist[t] + w[i];
if (!st[k]) {//将当前未加入队列的结点入队
q.push(k);
st[k] = 1;
}
}
}
}
return dist[n];
}
int main() {
memset(h, -1, sizeof h);//链表头节点初始化为-1
cin >> n >> m;
while (m--){
int a, b, c; cin >> a >> b >>c;
add(a, b, c);
}
int t = SPFA();
if (t == 0x3f3f3f3f) puts("impossible");
else cout << t;
}
多源最短路
Floyd
可以有负权边,不能有负权环 O(n^3)
邻接矩阵存储
(k:1~n) (i:1~n) (j:1~n) {d[i,j] = min(d[i,j], d[i,k] + d[k,j]);}
//https://www.acwing.com/problem/content/description/856/
#include <iostream>
using namespace std;
const int inf = 0x3f3f3f3f;
const int N = 210;
int d[N][N];
int n, m, q;
void floyd() {
for (int k = 1; k <= n; k++) {//在枚举第k层前,已经得到了前k-1个点之间(路径不包含k)的最短路
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);//核心代码
}
}
}
}
int main() {
cin >> n >> m >> q;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
if (i != j) d[i][j] = inf;//初始化为无穷,处理自环
}
}
while (m--) {
int a, b, c; cin >> a >> b >> c;//a到b的距离为c
d[a][b] = min(d[a][b], c);//处理重边
}
floyd();
while (q--) {
int a, b; cin >> a >> b;
if (d[a][b] > inf / 2) cout << "impossible" << endl;
//因为存在负权边,可能会把inf更新变小,导致d[a][b]略小于inf
else cout << d[a][b] << endl;
}
}
传递闭包
在一张点数为 n 的有向图的邻接矩阵中,给出任意两点间是否有直接连边的关系,让你求出任意两点之间是否有直接连边或间接连边的关系。
如果i能到达k,且k能到达j,则i也能到达j
//https://www.luogu.com.cn/problem/B3611
//给定一张点数为 n 的有向图的邻接矩阵,图中不包含自环,求该有向图的传递闭包
#include <iostream>
using namespace std;
const int N = 105;
int n;
int a[N][N];
void floyd(){
for(int k = 1;k <= n;k++){
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
a[i][j] |= a[i][k] & a[k][j];
}
}
}
}
int main(){
cin >> n;
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
cin >> a[i][j];
}
}
floyd();
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
cout << a[i][j] << ' ';
}
cout << '\n';
}
}
Johnson
可以有负权边,不能有负权环
时间复杂度$O(NMlogM)$
- 新建一个虚拟的0号节点,从这个点向其它点连一条边权为0的边。然后用Bellman-Ford求出0号节点到其它所有点的最短路,记为
h[ ]。 - 假设存在一条从x到y边权为w的边,则我们重新设置边权为
w+p[x]-p[y](类似于物理学中的势能概念),消除负权边的影响。 - 接下来以每个点为起点跑n轮Dijkstra算法,再消除势能差,即可求出任意两点间的最短路。
//https://www.luogu.com.cn/problem/P5905
#include <iostream>
#include <queue>
#include <cstring>
using namespace std;
const long long INF = 1e9;
const int N = 3003,M = 10004;
int n,m;
int h[N],e[M],ne[M],w[M],idx;
long long dist[N][N],p[N];
bool vis[N];
int cnt[N];
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
bool spfa(){
memset(p,0x3f,sizeof p);
queue<int>q;
q.push(0);
p[0] = 0;
vis[0] = 1;
while(q.size()){
int t = q.front();
q.pop();
vis[t] = 0;
for(int i = h[t];~i;i = ne[i]){
int k = e[i];
if(p[k] > p[t] + w[i]){
p[k] = p[t] + w[i];
if(!vis[k]){
q.push(k);
vis[k] = 1;
cnt[k]++;
if(cnt[k] == n+1) return 1;
}
}
}
}
return 0;
}
void dijkstra(int bg){
memset(vis,0,sizeof vis);
priority_queue<pair<int,int>,vector<pair<int,int>>,greater<pair<int,int>>>pq;
pq.push({0,bg});
dist[bg][bg] = 0;
while(pq.size()){
auto [distance,ver] = pq.top();
pq.pop();
if(vis[ver]) continue;
else vis[ver] = 1;
for(int i = h[ver];~i;i = ne[i]){
int k = e[i];
if(dist[bg][k] > dist[bg][ver] + w[i]){
dist[bg][k] = dist[bg][ver] + w[i];
if(!vis[k]){
pq.push({dist[bg][k],k});
}
}
}
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
for(int i = 1;i <= m;i++){
int a,b,c;cin >> a >> b >> c;
add(a,b,c);
}
for(int i = 1;i <= n;i++) add(0,i,0);
if(spfa()) {cout << -1;return 0;}
for(int u = 1;u <= n;u++){
for(int i = h[u];~i;i = ne[i]){
w[i] += p[u] - p[e[i]];
}
}
memset(dist,0x3f,sizeof dist);
for(int i = 1;i <= n;i++) { dijkstra(i); }
for(int i = 1;i <= n;i++){
long long ans = 0;
for(int j = 1;j <= n;j++){
dist[i][j] += p[j] - p[i];//最后消除势能差,此时dist[i][j]即为i到j的最短路
if(dist[i][j] < INF ) ans += j * dist[i][j];
else ans += j * INF;
}
cout << ans << '\n';
}
}
(LCA)
求无向树上任意两点的距离
O(NlogN)预处理,O(logN)查询
设两个节点分别为x,y,dist[i]为根节点到点i的距离,lca(x,y)表示两点的最近公共祖先。 则 ans = dist[x] + dist[y] - 2*dist[lca(x,y)]
//例题:How far away? https://vjudge.net/problem/HDU-2586#author=GPT_zh
#include <iostream>
#include <queue>
#include <vector>
using namespace std;
void sol(){
int n,q;scanf("%d %d",&n,&q);
vector<vector<int>>fa(n+1,vector<int>(20));
vector<vector<pair<int,int>>>e(n+1);
vector<int>dist(n+1,0x3f3f3f3f),st(n+1),deep(n+1);
for(int i = 1;i < n;i++){
int a,b,c;scanf("%d %d %d",&a,&b,&c);
e[a].push_back({b,c});
e[b].push_back({a,c});
}
auto uuz = [&](){
priority_queue<pair<int,int>,vector<pair<int,int>>,greater<pair<int,int>>>pq;
dist[1] = 0;
pq.push({0,1});
while(pq.size()){
auto [distance,ver] = pq.top();pq.pop();
if(st[ver]) continue;
else st[ver] = 1;
for(auto &[k,w]:e[ver]){
if(dist[k] > distance + w){
dist[k] = distance + w;
pq.push({dist[k],k});
}
}
}
};
auto dfs = [&](auto &dfs,int u,int father)->void{
deep[u] = deep[father] + 1;
fa[u][0] = father;
for(int i = 1;(1 << i) <= deep[u];i++){
fa[u][i] = fa[fa[u][i-1]][i-1];
}
for(auto [k,w]:e[u]){
if(k == father) continue;
dfs(dfs,k,u);
}
};
auto lca = [&](int x,int y){
if(deep[x] < deep[y]) swap(x,y);
for(int i = 20;i >= 0;i--){
if(deep[fa[x][i]] >= deep[y]) x = fa[x][i];
}
if(x == y) return x;
for(int i = 20;i >= 0;i--){
if(fa[x][i] != fa[y][i]){
x = fa[x][i];
y = fa[y][i];
}
}
return fa[x][0];
};
uuz();
dfs(dfs,1,0);
while(q--){
int a,b;scanf("%d %d",&a,&b);
int k = lca(a,b);
printf("%d\n",dist[a] + dist[b] - 2*dist[k]);
}
}
int main(){
int t;scanf("%d",&t);
while(t--) sol();
}
树上问题
树的重心
重心是指树中的一个结点,如果将这个点删除后,剩余各个连通块中点数的最大值最小,那么这个节点被称为树的重心。
- 树的重心如果不唯一,则至多有两个且相邻
- 以树的重心为根时,所有子树的大小都不超过整棵树大小的一半。
- 树中所有点到某个点的距离和中,到重心的距离和最小;如果有两个重心,那么到它们的距离和一样。
- 把两棵树通过一条边相连得到一棵新的树,那么新的树的重心在连接原来两棵树的重心的路径上。
- 在一棵树上添加或删除一个叶子,那么它的重心最多只移动一条边的距离。
#include <iostream>
#include <vector>
#include <cstring>
using namespace std;
const int N = 200005;
int n,m;
int h[N],e[N],ne[N],idx;
bool st[N];
int siz[N],weight[N];//siz[i]表示dfs(x)选x为树根时,所有根节点为i的子树的大小(包括i)
//weight[i]表示第i个节点的最大的子树的大小,与dfs(x)的x选取无关
vector<int>cent;//重心可能有两个
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dfs(int u){
st[u] = 1;
siz[u] = 1;
int &now = weight[u];
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(!st[k]){
dfs(k);
siz[u] += siz[k];
now = max(now,siz[k]);
}
}
now = max(now,n - siz[u]);
if(now <= n/2){//根据定义2:以树的重心为根时,所有子树的大小都不超过整棵树大小的一半
cent.emplace_back(u);
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
for(int i = 1;i <= m;i++){
int a,b;cin >> a >> b;
add(a,b);
add(b,a);
}
dfs(1);//任选一个点当做树根dfs均可
cout << cent[0] << endl;
//cout << cent[1] << endl;//重心可能有两个
//cout << weight[cent[0]] << endl;
}
//给定一棵有根树,求出每一棵子树(有根树意义下且包含整颗树本身)的重心是哪一个节点。O(N)
//https://codeforces.com/contest/685/problem/B
#include <iostream>
#include <cstring>
using namespace std;
const int N = 300005;
int n,q;
int h[N],e[N],ne[N],idx;
bool st[N];
int fa[N];//存父节点
int ans[N];//当前节点的重心
int siz[N];//子树大小:所有子树上节点数 + 该节点
int weight[N];//节点重量:即所有子树「大小」的最大值
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dfs(int u){
siz[u] = 1;
ans[u] = u;
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
dfs(k);
siz[u] += siz[k];
weight[u] = max(weight[u],siz[k]);
}
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
int p = ans[k];
while(p!=u){
if(max(weight[p],siz[u]-siz[p]) <= siz[u]/2){
ans[u] = p;
break;
}
else{
p = fa[p];
}
}
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> q;
for(int i = 2;i <= n;i++){
int a;cin >> a;
fa[i] = a;
add(a,i);
}
dfs(1);
while(q--){
int u;cin >> u;
cout << ans[u] << endl;
}
}
树的中心
在树中,如果节点 $x$ 作为根节点时,从 $x$ 出发的最长链最短,那么称 $x$ 为这棵树的中心。
性质:
- 树的中心不一定唯一,但最多有 $2$ 个,且这两个中心是相邻的。
- 树的中心一定位于树的直径上。
- 树上所有点到其最远点的路径一定交会于树的中心。
- 当树的中心为根节点时,其到达直径端点的两条链分别为最长链和次长链。
- 当通过在两棵树间连一条边以合并为一棵树时,连接两棵树的中心可以使新树的直径最小。
- 树的中心到其他任意节点的距离不超过树直径的一半。
//树形dp实现 https://www.acwing.com/problem/content/1075/
//给定一颗树,找到一个点,使得该点到树中其它节点的最远距离最近
#include <iostream>
#include <cstring>
using namespace std;
const int N = 200005,INF = 0x3f3f3f3f;
int n;
int h[N],e[N],ne[N],w[N],idx;
int d1[N],d2[N],p1[N],p2[N],up[N];
//d1,d2表示向下的最大值和次大值,p1,p2表示d1,d2是由哪个子节点更新过来的
//up表示向上的最大值
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dfs_d(int u,int fa){//子节点向父节点更新,获得向下的d1,d2
d1[u] = d2[u] = -INF;//初始化为-INF可以处理负权边
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(k == fa) continue;
dfs_d(k,u);
int t = d1[k] + w[i];
if(t > d1[u]){
d2[u] = d1[u]; d1[u] = t;
p2[u] = p1[u]; p1[u] = k;
}
else if(t > d2[u]){
d2[u] = t;
p2[u] = k;
}
}
if(d1[u] == -INF){ d1[u] = d2[u] = 0;}//特殊处理叶子节点
}
void dfs_u(int u,int fa){//父节点向子节点更新,获得向上的up
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(k == fa)continue;
if(p1[u] == k){ up[k] = max(up[u],d2[u])+w[i]; }
else { up[k] = max(up[u],d1[u])+w[i]; }
dfs_u(k,u);
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n;
for(int i = 1;i < n;i++){
int a,b,c;cin >> a >> b >> c ;
add(a,b,c);add(b,a,c);
}
dfs_d(1,0);
dfs_u(1,0);
int ans = INF;
for(int i = 1;i <= n;i++){
ans = min(ans,max(d1[i],up[i]));
}
cout << ans;
}
树的直径
树上任意两节点之间最长的简单路径即为「树的直径」。(可能有多条,所有直径经过相同的中点)
树形DP实现:我们记录当 $1$ 为树的根时,每个节点作为子树的根向下,所能延伸的最长路径长度 $d_1$ 与次长路径(与最长路径无公共边)长度 $d_2$,那么直径就是对于每一个点,该点 $d_1 + d_2$ 能取到的值中的最大值。
//https://www.acwing.com/problem/content/1074/
#include <iostream>
#include <cstring>
using namespace std;
const int N = 200005;
int n;
int h[N],e[N],ne[N],w[N],idx;
int d1[N],d2[N],ans;//d1记录最长路径,d2记录次长路径,初始为0,避免负权边的影响
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dfs(int u,int fa){
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(k == fa) continue;
dfs(k,u);
int t = d1[k] + w[i];
if(t > d1[u]){//诺t>d1同时更新d1,d2
d2[u] = d1[u];
d1[u] = t;
}
else if(t > d2[u]){//else if诺t>d2只需更新d2
d2[u] = t;
}
}
ans = max(ans,d1[u]+d2[u]);
}
int main(){
memset(h,-1,sizeof h);
cin >> n;
for(int i = 1;i < n;i++){
int a,b,c;cin >> a >> b >> c;
add(a,b,c);
add(b,a,c);
}
dfs(1,0);
cout << ans;
}
两次DFS/BFS实现(边权必须非负):首先从任意节点 $y$ 开始进行第一次 DFS,到达距离其最远的节点,记为 $z$,然后再从 $z$ 开始做第二次 DFS,到达距离 $z$ 最远的节点,记为 $z’$,则 $dist(z,z’)$ 即为树的直径。
定理:在一棵树上,从任意节点y开始进行一次 DFS,到达的距离其最远的节点z必为直径的一端。
//https://www.luogu.com.cn/problem/B4016
#include <iostream>
#include <cstring>
using namespace std;
using ll = long long;
const int N = 400005;
int n;
int h[N],e[N],ne[N],w[N],idx;
ll dist[N];
ll maxn;//记录最远点能到的点
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dfs(int u,int fa){
for(int i = h[u];i != -1;i = ne[i]){
int k = e[i];
if(k == fa) continue;
dist[k] = dist[u] + w[i];
if(dist[k] > dist[maxn]){maxn = k;}//更新最远能到的点
dfs(k,u);
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n;
for(int i = 1;i < n;i++){
int a,b,c = 1;cin >> a >> b;
add(a,b,c);
add(b,a,c);
}
dfs(1,0);
dist[maxn] = 0;
dfs(maxn,0);
cout << dist[maxn] << endl;;
}
//bfs(1)
void bfs(int u){
queue<pair<int,int>>q;
memset(st,0,sizeof st);
q.push({u,0});
st[u] = 1;
while(q.size()){
auto [v,dist] = q.front();
q.pop();
for(int i = h[v];~i;i = ne[i]){
int k = e[i];
if(st[k]) continue;
st[k] = 1;
q.push({k,dist+w[i]});
if(ans < dist + w[i]){
ans = dist + w[i];
maxn = k;
}
}
}
}
最近公共祖先
性质
- $\text{LCA}({u})=u$;
- $u$ 是 $v$ 的祖先,当且仅当 $\text{LCA}(u,v)=u$;
- 如果 $u$ 不为 $v$ 的祖先并且 $v$ 不为 $u$ 的祖先,那么 $u,v$ 分别处于 $\text{LCA}(u,v)$ 的两棵不同子树中;
- 前序遍历中,$\text{LCA}(S)$ 出现在所有 $S$ 中元素之前,后序遍历中 $\text{LCA}(S)$ 则出现在所有 $S$ 中元素之后;
- 两点集并的最近公共祖先为两点集分别的最近公共祖先的最近公共祖先,即 $\text{LCA}(A\cup B)=\text{LCA}(\text{LCA}(A), \text{LCA}(B))$;
- 两点的最近公共祖先必定处在树上两点间的最短路上;
- $d(u,v)=h(u)+h(v)-2h(\text{LCA}(u,v))$,其中 $d$ 是树上两点间的距离,$h$ 代表某点到树根的距离。
倍增求LCA
O(NlogN)预处理,O(logN)查询,空间复杂度O(NlogN)
dfs预处理fa[i,j],表示节点i的第$2^j$个祖先
求lca时,让深度最小的节点跳到与另一个节点同一个深度,诺此时两个节点相同直接返回当前节点。 再让两个节点同时往上跳到最后一个非公共祖先节点,该点的父亲节点即为LCA节点
//https://www.luogu.com.cn/problem/P3379
#include <iostream>
#include <vector>
using namespace std;
const int N = 500005;
int n,q,root;
vector<int> e[N];
int fa[N][22],deep[N];//深度从1开始
void dfs(int u,int father){
fa[u][0] = father;
deep[u] = deep[father] + 1;
for(int i = 1;(1 << i) <= deep[u];i++){
fa[u][i] = fa[fa[u][i-1]][i-1];
}
for(auto k:e[u]){
if(k == father) continue;
dfs(k,u);
}
}
int lca(int x,int y){
if(deep[x] < deep[y]) swap(x,y);//一般以x作为深度较深的点
for(int i = 20;i >= 0;i--){//再让x跳到与y同一深度
if(deep[fa[x][i]] >= deep[y]) x = fa[x][i];
}
if(x == y) return x;
for(int i = 20;i >= 0;i--){
if(fa[x][i] != fa[y][i]){
x = fa[x][i];
y = fa[y][i];
}
}
return fa[x][0];
}
int main(){
cin >> n >> q >> root;
for(int i = 1;i < n;i++){
int a,b;cin >> a >> b;
e[a].emplace_back(b);
e[b].emplace_back(a);
}
dfs(root,0);
while(q--){
int a,b;cin >> a >> b;
cout << lca(a,b) << '\n';
}
}
Tarjan求LCA
离线算法,使用DFS+并查集实现
时间复杂度O(N+Q),常数较大
#include <iostream>
#include <vector>
#include <cstring>
using namespace std;
const int N = 1000006;
int n,q,root;
int h[N],e[N],ne[N],idx;
int dfn[N],low[N],dn;
vector<pair<int,int>>ask[N];
int ans[N];
int p[N];
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
int find(int x){
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
void tarjan(int x,int fa){
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(y == fa) continue;
tarjan(y,x);
p[find(y)] = find(x);
}
for(auto [y,i]:ask[x]){
ans[i] = find(y);
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> q >> root;
for(int i = 1;i <= n;i++) p[i] = i;
for(int i = 1;i < n;i++){
int a,b;scanf("%d %d",&a,&b);
add(a,b);add(b,a);
}
for(int i = 1;i <= q;i++){
int a,b;scanf("%d %d",&a,&b);
if(a == b) ans[i] = a;
else{
ask[a].push_back({b,i});
ask[b].push_back({a,i});
}
}
tarjan(root,0);
for(int i = 1;i <= q;i++){
printf("%d\n",ans[i]);
}
}
树上差分
树上差分可以理解为对树上的某一段路径进行差分操作,这里的路径可以类比一维数组的区间进行理解。适合多次修改(O(logN)),单次查询(需要O(N)dfs统计信息)。
点差分
[P3128 USACO15DEC] Max Flow P - 洛谷 (luogu.com.cn)
每次将a到b简单路径上的点权加上x,则val[a] += x,val[b] += x, val[lca] -= x,val[fa[lca]] -= x。因为回溯统计时lca会被加上2x,所以我们需要让lca减去x,再让lca的父节点减去x。
#include <iostream>
#include <cstring>
using namespace std;
const int N = 50004,M = 100005;
int n,q,ans;
int h[N],e[M],ne[M],idx;
int fa[N][22],deep[N];
int val[N];
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dfs(int u,int father){
fa[u][0] = father;
deep[u] = deep[father] + 1;
for(int i = 1;(1 << i) <= deep[u];i++){
fa[u][i] = fa[fa[u][i-1]][i-1];
}
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(k != father) dfs(k,u);
}
}
int lca(int x,int y){
if(deep[x] < deep[y]) swap(x,y);
for(int i = 20;i >= 0;i--){
if(deep[fa[x][i]] >= deep[y]) x = fa[x][i];
}
if(x == y) return x;
for(int i = 20;i >= 0;i--){
if(fa[x][i] != fa[y][i]){
x = fa[x][i];
y = fa[y][i];
}
}
return fa[x][0];
}
void dfs2(int u,int father){
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(k != father){
dfs2(k,u);
val[u] += val[k];
}
}
ans = max(ans,val[u]);
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> q;
for(int i = 1;i < n;i++){
int a,b;cin >> a >> b;
add(a,b);add(b,a);
}
dfs(1,0);
while(q--){
int a,b;cin >> a >> b;
int father = lca(a,b);
val[a]++;val[b]++;
val[father]--;val[fa[father][0]]--;
}
dfs2(1,0);
cout << ans;
}
边差分
与点差分略有不同。
诺要将a到b上简单路径的边权加x,则dist[a] += x,dist[b] += x,dist[lca] -= 2x。
树哈希
判断一些树是否同构的时,我们常常把这些树转成哈希值储存起来,以降低复杂度。
这里介绍一个实现简单且不容易被卡的做法,这类方法需要一个多重集的哈希函数。以某个结点为根的子树的哈希值,就是以它的所有儿子为根的子树的哈希值构成的多重集的哈希值,即:
\[h_x = f(\{ h_i \mid i \in son(x) \})\]其中 $h_x$ 表示以 $x$ 为根的子树的哈希值,$f$ 是多重集的哈希函数。
以代码中使用的哈希函数为例:
\[f(S) = \left( c + \sum_{x \in S} g(x) \right) \bmod m\]其中 $c$ 为常数,一般使用 $1$ 即可。$m$ 为模数,一般使用 $2^{32}$ 或 $2^{64}$ 进行自然溢出,也可使用大素数。$g$ 为整数到整数的映射,代码中使用 xor shift,也可以选用其他的函数,但是不建议使用多项式。为了预防出题人对着 xor hash 卡,还可以在映射前后异或一个随机常数。
这种哈希十分好写,比每次使用mt19937_64(hs[k])( )生成随机数要快。如果需要换根,第二次 DP 时只需把子树哈希减掉即可。
//有根树哈希 https://uoj.ac/problem/763
//给定一棵以1为根的树,你需要输出这棵树中最多能选出多少个互不同构的子树。
#include <iostream>
#include <set>
#include <cstring>
#include <random>
using namespace std;
const int N = 1000006,M = N << 1;
int n;
int h[N],e[M],ne[M],idx;
unsigned long long hs[N];
set<unsigned long long>se;
const unsigned long long mask = mt19937_64(time(0))();
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
unsigned long long shift(unsigned long long x){
x ^= mask;
x ^= x << 13;
x ^= x >> 7;
x ^= x << 17;
x ^= mask;
return x;
}
void dfs(int u,int fa){
hs[u] = 1;
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(k == fa) continue;
dfs(k,u);
hs[u] += shift(hs[k]);
}
se.insert(hs[u]);
}
int main(){
memset(h,-1,sizeof h);
cin >> n;
for(int i = 1;i < n;i++){
int a,b;cin >> a >> b;
add(a,b);add(b,a);
}
dfs(1,0);
cout << se.size();
}
生成树
最小生成树
无向连通图的 最小生成树(Minimum Spanning Tree,MST)为边权和最小的生成树。
从图(一般为无向有环图 )中生成一棵树(n-1条边)时,这棵树每条边的权重相加之和最小。
只有连通图才有生成树,而对于非连通图,只存在生成森林。
Kruskal
适合稀疏图 $O(MlogM)$ 结构体存边 并查集实现
将边权从小到大排序,遍历边,诺当前边的两个端点属于不同的树,则合并这两颗树
kurskal重构树的一些性质
- 是一棵二叉树。
- 如果是按最小生成树建立的话是一个大根堆。
- 原图中两个点间所有路径上的边最大权值的最小值 = 最小生成树上两点简单路径的边最大权值 = Kruskal 重构树上两点 LCA 的点权。
//https://www.acwing.com/problem/content/description/861/
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100005, M = 2 * N;
int n, m;
int p[N];//保存并查集
int res, cnt;
struct Edge {
int a, b, w;
}edges[M];
bool cmp(Edge E1, Edge E2) {//自定义sort排序,以结构体w值为依据排序
return E1.w < E2.w;
}
int find(int x) {//并查集
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
void kruskal() {
for (int i = 0; i < m; i++) {
int pa = find(edges[i].a), pb = find(edges[i].b);
if (pa != pb) {//如果这个边与之前选择的所有边不会成环,就选择这条边
p[pa] = pb;//合并
res += edges[i].w;
cnt++;
}
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i++) { p[i] = i; }//初始化并查集
for (int i = 0; i < m; i++) {
int a, b, w; cin >> a >> b >> w;
edges[i] = { a,b,w };
}
sort(edges, edges + m,cmp);//将所有m条边按照权值的大小进行升序排序
kruskal();
if (cnt < n - 1) puts("impossible");
else cout << res << endl;
}
Prim朴素
适合稠密图 $O(N^2)$
//https://www.acwing.com/problem/content/860/
#include <iostream>
#include <cstring>
using namespace std;
const int N = 510, inf = 0x3f3f3f3f;
int n, m;
int dist[N], g[N][N];//dist存点到集合s的距离
bool vis[N];
int prim(){//1_idx
std::memset(dist,0x3f,sizeof dist);
std::memset(vis,0,sizeof vis);
int ans = 0;
for(int i = 0;i < n;i++){
int t = 0;
for(int j = 1;j <= n;j++){
if(!vis[j] && (t == 0 || dist[t] > dist[j])) {
t = j;//寻找离集合s最近的点t
}
}
vis[t] = 1;
if(i && dist[t] == 0x3f3f3f3f) return -1;//判断是否连通
if(i) ans += dist[t];//加入点t
for(int j = 1;j <= n;j++){
dist[j] = std::min(dist[j],g[t][j]);//再用点t更新其它点到集合的距离
}
}
return ans;
}
int main() {
cin >> n >> m;
memset(g, 0x3f, sizeof g);
while (m--){
int a, b, c; cin >> a >> b >> c;
g[a][b] = g[b][a] = min(g[a][b], c);//处理重边
}
int t = prim();
if (t == -1) puts("impossible");
else cout << t;
}
诺prim要输出具体选择的边,可以开一个辅助数组last[],更新dist[]时记录当前点从哪个点转移的,ans+=dist[t]时即选择了边(t,last)。
Prim堆优化
比较复杂不常用,直接用Kruskal算法
Boruvka
Kruskal和Prim的结合,在边具有较多特殊性质的问题中,Boruvka算法具有优势。
唯一性
考虑最小生成树的唯一性。如果一条边 不在最小生成树的边集中,并且可以替换与其 权值相同、并且在最小生成树边集 的另一条边。那么,这个最小生成树就是不唯一的。
对于 Kruskal 算法,只要计算为当前权值的边可以放几条,实际放了几条,如果这两个值不一样,那么就说明这几条边与之前的边产生了一个环(这个环中至少有两条当前权值的边,否则根据并查集,这条边是不能放的),即最小生成树不唯一。
寻找权值与当前边相同的边,我们只需要记录头尾指针,用单调队列即可在 $O(\alpha(m))$(m 为边数)的时间复杂度里优秀解决这个问题(基本与原算法时间相同)。
//https://vjudge.net/problem/OpenJ_Bailian-1679#author=GPT_zh
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 105,M = 10004;
int n,m;
int p[N];
struct edge{
int a,b,w;
bool operator < (edge &e2){
return w < e2.w;
}
}e[M];
int find(int x){
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
void soviet(){
cin >> n >> m;
for(int i = 1;i <= n;i++) p[i] = i;
for(int i = 1;i <= m;i++){
cin >> e[i].a >> e[i].b >> e[i].w;
}
sort(e+1,e+m+1);
int ans = 0,cnt = 0;
bool flag = 1;
int tail = 0,sum1 = 0,sum2 = 0;
for(int i = 1;i <= m+1;i++){
if(i > tail){
if(sum1 != sum2){//如果sum1 != sum2 则最小生成树不唯一
flag = 0;
break;
}
sum1 = sum2 = 0;
for(int j = i;j <= m+1;j++){
if(j > m || e[j].w != e[i].w){
tail = j-1;
break;
}
if(find(e[j].a) != find(e[j].b)) sum1++;//sum1计算当前权值的边可以放几条
}
}
if(i > m) break;
int pa = find(e[i].a),pb = find(e[i].b);
if(pa != pb && cnt != n-1){
sum2++;//sum2计算当前权值的边实际放了几条
cnt++;
p[pa] = pb;
ans += e[i].w;
}
}
if(flag) cout << ans << '\n';
else cout << "Not Unique!\n";
}
int main(){
int mt;cin >> mt;
while(mt--) soviet();
}
次小生成树
非严格次小生成树
求解方法
- 求出无向图的最小生成树 $T$,设其权值和为 $M$ 。
- 遍历每条未被选中的边$e = (u,v,w)$,找到 $T$ 中 $u$ 到 $v$ 的路径上边权最大的一条边$e’ = (s,t,w’)$,在 $T$ 中用 $e$ 替换 $e’$,即可得到一颗生成树 $T’$,其权值为 $M’ = M + w - w’$ 。
- 对所有的 $M’$ 取最小值即为答案。
其中求 $u,v$ 路径上边权最大的值可以在倍增求 $LCA$ 的过程中求得。
//ACM Contest and Blackout https://vjudge.net/problem/UVA-10600
//模版题,分别输出无向图的最小生成树和非严格次小生成树的权值,本题保证答案存在
#include <iostream>
#include <cstring>
#include <vector>
#include <algorithm>
const int N = 105,M = N*N;
int n,m;
int fa[N][22],deep[N],mx[N][22];
int h[N],e[M],ne[M],w[M],idx;
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
int p[N];
int find(int x){
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
struct Edge{
int a,b,c;
bool operator < (const Edge &e2) const{
return c < e2.c;
}
};
void dfs(int u,int father,int weight){//mx[u][i]表示u到其第2^i个父节点的最大权值
deep[u] = deep[father]+1;
fa[u][0] = father;
mx[u][0] = weight;
for(int i = 1;(1 << i) <= deep[u];i++){
mx[u][i] = std::max(mx[fa[u][i-1]][i-1],mx[u][i-1]);//
fa[u][i] = fa[fa[u][i-1]][i-1];
}
for(int i = h[u];~i;i = ne[i]){
if(e[i] != father) dfs(e[i],u,w[i]);
}
}
int lca(int a,int b){//求a,b路径上的最大权值
int ans = 0;
if(deep[a] < deep[b]) std::swap(a,b);
for(int i = 20;i >= 0;i--){
if(deep[fa[a][i]] >= deep[b]) {
ans = std::max(ans,mx[a][i]);
a = fa[a][i];
}
}
if(a == b) return ans;
for(int i = 20;i >= 0;i--){
if(fa[a][i] != fa[b][i]){
ans = std::max({ans,mx[a][i],mx[b][i]});
a = fa[a][i];
b = fa[b][i];
}
}
ans = std::max({ans,mx[a][0],mx[b][0]});
return ans;
}
void sol(){
std::memset(h,-1,sizeof h);
std::memset(fa,0,sizeof fa);//多测需清空fa数组
idx = 0;
std::cin >> n >> m;
for(int i = 1;i <= n;i++) p[i] = i;
std::vector<Edge>edge;
for(int i = 1;i <= m;i++){
int a,b,c; std::cin >> a >> b >> c;
edge.push_back({a,b,c});
}
std::sort(edge.begin(),edge.end());
int ans1 = 0;
std::vector<Edge>T2;
for(auto &[a,b,c]:edge){
int pa = find(a),pb = find(b);
if(pa == pb) { T2.push_back({a,b,c}); }
else{
p[pa] = pb;
ans1 += c;
add(a,b,c); add(b,a,c);
}
}
//if(cnt != n-1) {return;} 不存在最小生成树
//if(T2.empty()) {return;} 不存在次小生成树
dfs(1,0,0);
int ans2 = 1e9;
for(auto &[a,b,c]:T2){//遍历所有未选择的边
int now = ans1 + c - lca(a,b);//替换最小生成树中(a,b)路径上权值最大的一条边
ans2 = std::min(ans2,now);//答案取最小
}
std::cout << ans1 << ' ' << ans2 << '\n';
}
int main(){
int mt;std::cin >> mt;
while(mt--) sol();
}
严格次小生成树
在用未选择的边 $e = (u,v,w)$ 替换最小生成树 $T$ 上的边时,找出 $T$ 上 $(u,v)$ 路径中边权严格小于 $w$ 的最大的一条边进行替换。
同时维护节点到祖先路径上的最大边权和严格次大边权即可。
//https://www.luogu.com.cn/problem/P4180
//模版,本题保证严格次小生成树存在
#include <iostream>
#include <cstring>
#include <vector>
#include <algorithm>
const int INF = 0x3f3f3f3f;
const int N = 100005,M = 600005;
int n,m;
int h[N],e[M],ne[M],w[M],idx;
int fa[N][20],deep[N],mx[N][20],mx2[N][20];//mx:最大边权,mx2:次大边权
struct Edge{
int a,b,c;
bool operator < (const Edge &e2)const{
return c < e2.c;
}
};
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
int p[N];
int find(int x){
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
void dfs(int u,int father,int weight){
deep[u] = deep[father] + 1;
fa[u][0] = father;
mx[u][0] = weight;
mx2[u][0] = -INF;//-INF代表不存在次大边权
for(int i = 1;(1 << i) <= deep[u];i++){
mx[u][i] = std::max(mx[fa[u][i-1]][i-1],mx[u][i-1]);
mx2[u][i] = std::max(mx2[fa[u][i-1]][i-1],mx2[u][i-1]);
if(mx[u][i-1] > mx[fa[u][i-1]][i-1]) mx2[u][i] = std::max(mx2[u][i],mx[fa[u][i-1]][i-1]);
else if(mx[u][i-1] < mx[fa[u][i-1]][i-1]) mx2[u][i] = std::max(mx2[u][i],mx[u][i-1]);
fa[u][i] = fa[fa[u][i-1]][i-1];
}
for(int i = h[u];~i;i = ne[i]){
if(e[i] != father) dfs(e[i],u,w[i]);
}
}
int lca(int a,int b,int c){
int ans = -INF;
if(deep[a] < deep[b]) std::swap(a,b);
for(int i = 18;i >= 0;i--){
if(deep[fa[a][i]] >= deep[b]) {
if(mx[a][i] < c) ans = std::max(ans,mx[a][i]);
else ans = std::max(ans,mx2[a][i]);
a = fa[a][i];
}
}
if(a == b) return ans;
for(int i = 18;i >= 0;i--){
if(fa[a][i] != fa[b][i]){
ans = std::max(ans,mx[a][i] < c ? mx[a][i] : mx2[a][i]);
ans = std::max(ans,mx[b][i] < c ? mx[b][i] : mx2[b][i]);
a = fa[a][i];
b = fa[b][i];
}
}
ans = std::max(ans,mx[a][0] < c ? mx[a][0] : mx2[a][0]);
ans = std::max(ans,mx[b][0] < c ? mx[b][0] : mx2[b][0]);
return ans;
}
int main(){
std::memset(h,-1,sizeof h);
std::cin >> n >> m;
for(int i = 1;i <= n;i++) p[i] = i;
std::vector<Edge>edge;
for(int i = 1;i <= m;i++){
int a,b,c;std::cin >> a >> b >> c;
edge.push_back({a,b,c});
}
std::sort(edge.begin(),edge.end());
std::vector<Edge>T2;
int cnt = 0;
long long ans1 = 0;
for(auto &[a,b,c]:edge){
int pa = find(a),pb = find(b);
if(pa == pb) {
T2.push_back({a,b,c});
}
else{
p[pa] = pb;
ans1 += c;
cnt++;
add(a,b,c); add(b,a,c);
}
}
// if(cnt != n-1) {return 0;} //无最小生成树
// if(T2.empty()) {return 0;} //无次小生成树
dfs(1,0,0);
long long ans2 = 1e18;
for(auto &[a,b,c]:T2){
long long w2 = lca(a,b,c); //查找生成树中(a,b)路径上边权严格小于c的最大边权
if(w2 == -INF) continue; //不存在严格次大边
long long now = ans1 + c - w2;
ans2 = std::min(ans2,now);
}
// if(ans2 == 1e18) {return 0;} //无严格次小生成树
std::cout << ans2;
}
生成树计数
无向图的生成树计数
UVA10766 Organising the Organisation - 洛谷 (luogu.com.cn)
给定n个点,两两之间有一条无向边,现在切断m条边,求剩下的图中有多少种不同的生成树
矩阵树定理,时间复杂度$O(N^3)$
权值设为1求得的是不同生成树的个数。权值设为原边权求得的是不同生成树的权值之和。
#include <iostream>
#include <vector>
const int N = 55;
int n,m,root;
int g[N][N];
struct Mat{
std::vector<std::vector<long long>>a;
Mat(int n){
a = std::vector<std::vector<long long>>(n+1,std::vector<long long>(n+1));
}
void add(int x,int y,int w){//无向图add(x,y,w),add(y,x,w); 度数矩阵-邻接矩阵
if(x == y) return;
a[y][y] = (a[y][y] + w);
a[x][y] = (a[x][y] - w);
}
long long det(int n){//高斯消元求n*n行列式的值(1_idx)
long long ans = 1;
for(int i = 2;i <= n;i++){//删除根节点1所在行列,下标从2开始即可(无向图可任选根)
for(int j = i+1;j <= n;j++){
while(a[j][i]){
long long t = a[i][i]/a[j][i];//貌似求不求逆元都无所谓?
for(int k = i;k <= n;k++) {
a[i][k] -= a[j][k] * t;
}
std::swap(a[i],a[j]);
ans = -ans;
}
}
if(!a[i][i]) return 0;
ans *= a[i][i];
}
return std::abs(ans);
}
};
void sol(){
Mat M(n);
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
g[i][j] = 1;
}
}
for(int i = 1;i <= m;i++){
int x,y;std::cin >> x >> y;
g[x][y] = g[y][x] = 0;
}
for(int i = 1;i <= n;i++){
for(int j = i+1;j <= n;j++){
if(g[i][j]) {
M.add(i,j,1);
M.add(j,i,1);
}
}
}
std::cout << M.det(n) << '\n';
}
int main(){
while(std::cin >> n >> m >> root) sol();
}
有向图的生成树计数
[P4455 CQOI2018] 社交网络 - 洛谷 (luogu.com.cn)
给定n个点m条边的有向图,求以1为根节点的生成树个数。
如果要是给定root,不一定为1,将第root行和第n行交换,第root列和第n列交换,然后删除第n行n列再计算即可。
#include <iostream>
#include <vector>
const int mod = 1e4+7;
struct Mat{
std::vector<std::vector<long long>>a;
Mat(int n){
a = std::vector<std::vector<long long>>(n+1,std::vector<long long>(n+1));
}
void add(int x,int y,int w){//有向图add(x,y,w);
if(x == y) return;
a[y][y] = (a[y][y] + w) % mod;
a[x][y] = (a[x][y] - w) % mod;
}
long long det(int n){//高斯消元求n*n行列式的值(1_idx)
long long ans = 1;
for(int i = 2;i <= n;i++){//下标从2开始,相当于删除根节点1所在行列,
for(int j = i+1;j <= n;j++){
while(a[j][i]){
long long t = a[i][i]/a[j][i];//貌似求不求逆元都无所谓?
for(int k = i;k <= n;k++) {
a[i][k] = (a[i][k] - a[j][k] * t % mod + mod) % mod;
}
std::swap(a[i],a[j]);
ans = -ans;
}
}
if(!a[i][i]) return 0;
ans = (ans * a[i][i] % mod + mod) % mod;
}
return std::abs(ans);
}
};
int main(){
int n,m; std::cin >> n >> m;
Mat M(n);
for(int i = 1;i <= m;i++){
int a,b;std::cin >> a >> b;
M.add(b,a,1);//本题题意是b向a连边
}
std::cout << M.det(n);
}
最小树形图
有向图上的最小生成树(Directed Minimum Spanning Tree)称为最小树形图。
所有从图中生成一颗 根节点能到达其它节点的树,边权和最小的一颗树
常用的算法是朱刘算法(也称 Edmonds 算法),可以在 $O(nm)$ 时间内解决最小树形图问题
算法流程,对于每一次循环:
- 初始化
- 对于每个点,选择指向它的边权最小的一条边
- 将选出的边累加到答案里,如果出现孤立点则无解
- 如果没有环,算法完成,退出循环
- 把所有不是环上的点全部设置为自己是一个独立的环(大小为1的新环)
- 进行缩环并更新其它点到环的距离
- 重新设置n和root
//https://www.luogu.com.cn/problem/P4716
//给定一个n个点m条边根节点为root的有向图,试求出一颗以root为根的最小树形图
#include <iostream>
const int INF = 0x3f3f3f3f;
const int N = 3003,M = 10004;
int mn[N],fa[N];//每个节点的最小入边权值及其父节点
int loop[N];//节点所属的环编号(0表示不在环中)
int vis[N]; //临时标记数组(用于环检测)
struct Edge{
int a,b,c;
}edge[M];
int zhuliu(int n,int m,int root){
int ans = 0;
while(1){
int tot = 0;//记录当前迭代检测到的环的数量
for(int i = 1;i <= n;i++){//初始化数组
mn[i] = INF;
fa[i] = vis[i] = loop[i] = 0;
}
for(int i = 1;i <= m;i++){//贪心找到最小入边图,并记录该图上每个节点的最小入边权值及其父节点
auto &[a,b,c] = edge[i];
if(a != b && mn[b] > c){//处理自环(缩环后存在自环)
mn[b] = c;
fa[b] = a;
}
}
mn[root] = 0;//根节点没有入边,权值设为0
for(int i = 1;i <= n;i++){
if(mn[i] == INF) return -1;//诺存在孤立节点,无解
ans += mn[i];//累加当前选择边的权值
}
for(int a = 1;a <= n;a++){//环检测
int b = a;
//沿着父链回溯,直到遇到根节点、已标记节点或已经在环上的节点
while(b != root && !vis[b] && !loop[b]) {
vis[b] = a;//标记当前节点
b = fa[b];//回溯父节点
}
if(b != root && vis[b] == a){//发现新环
loop[b] = ++tot;//记录环上的点在哪个环上
for(int k = fa[b];k != b;k = fa[k]){
loop[k] = tot;
}
}
}
if(!tot) return ans;//如果没有环,算法完成,返回答案
for(int i = 1;i <= n;i++){//处理剩余节点,所有非环上的独立点,每个点自己视为一个环
if(!loop[i]) loop[i] = ++tot;
}
for(int i = 1;i <= m;i++){//重新设置边权,缩环
auto &[a,b,c] = edge[i];
edge[i] = {loop[a],loop[b],c-mn[b]};//边权减去已选择的最小入边权值
}
n = tot;//完成缩环,重新设置n和root
root = loop[root];
}
}
int main(){
int n,m,root; std::cin >> n >> m >> root;
for(int i = 1;i <= m;i++){
std::cin >> edge[i].a >> edge[i].b >> edge[i].c;
}
std::cout << zhuliu(n,m,root);
}
不定根的最小树形图
Ice_cream’s world II - HDU 2121 - Virtual Judge (vjudge.net)
输出 最小树形图权值 和 选定的根,诺根不唯一,输出编号最小的。
我们建立一个虚拟的超级源点,并向其它所有点连边,边权为大于原图所有边权之和和一个数(假设为sum),诺最后ans - sum >= sum说明虚拟源点建的边用了超过一次,则图不连通无解。否则最终答案就是ans-sum。
主要在于如何找编号最小的根。如果有多个根,则他们最终会成一个环,这个环缩点后会与虚根相连,找出节点编号最小的一个根即可,因为我们从虚根向节点建边时是从m+1到m+n建边的,所以在下一次循环时,第一次访问到连向该环的边时,其编号(减去m)即为编号最小的根。
#include <iostream>
const int INF = 0x3f3f3f3f;
const int N = 2003,M= 20004;
int n,m,root,real_root;
int fa[N],mn[N],vis[N],loop[N];
struct Edge{
int a,b,c;
}edge[M];
int zhuliu(int n,int m,int root){
int ans = 0;
while(1){
int cnt = 0;
for(int i = 1;i <= n;i++){
mn[i] = INF;
fa[i] = vis[i] = loop[i] = 0;
}
for(int i = 1;i <= m;i++){
auto &[a,b,c] = edge[i];
if(a != b && mn[b] > c){
mn[b] = c;
fa[b] = a;
if(a == root) real_root = i;//只需要在这里更新要找的根
}
}
mn[root] = 0;
for(int i = 1;i <= n;i++){
if(mn[i] == INF) return -1;
ans += mn[i];
}
for(int a = 1;a <= n;a++){
int b = a;
while(b != root && !vis[b] && !loop[b]){
vis[b] = a;
b = fa[b];
}
if(b != root && vis[b] == a){
loop[b] = ++cnt;
for(int k = fa[b];k != b;k = fa[k]){
loop[k] = cnt;
}
}
}
if(!cnt) return ans;
for(int i = 1;i <= n;i++){
if(!loop[i]) loop[i] = ++cnt;
}
for(int i = 1;i <= m;i++){
auto &[a,b,c] = edge[i];
edge[i] = {loop[a],loop[b],c-mn[b]};
}
n = cnt;
root = loop[root];
}
}
void sol(){
int sum = 0;
for(int i = 1;i <= m;i++){
int a,b,c;std::cin >> a >> b >> c;
edge[i] = {++a,++b,c};//本题节点编号从0_idx开始
sum += c;
}
sum++;
for(int i = 1;i <= n;i++){
edge[m+i] = {n+1,i,sum};
}
int ans = zhuliu(n+1,n+m,n+1);
if(ans == -1 || ans - sum >= sum) std::cout << "impossible\n";
else std::cout << ans-sum << ' ' << real_root - m - 1<< '\n';
}
int main(){
std::ios::sync_with_stdio(false);std::cin.tie(0);
while(std::cin >> n >> m) {
sol();
std::cout << '\n';
}
}
二分图

性质:
不存在边数为奇数的环
如果两个集合中的点分别染成黑色和白色,可以发现二分图中的每一条边都一定是连接一个黑色点和一个白色点。
二分图判定
染色法判二分图
判断是否是二分图(不存在奇环)

//二分图的判定 https://www.acwing.com/problem/content/862/
#include <iostream>
#include <queue>
#include <cstring>
using namespace std;
const int N = 200005;
int n,m;
int h[N],e[N],ne[N],idx;
int color[N];//0代表未染色,1/2表示染了两种颜色
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
bool uuz(int be){
color[be] = 1;
queue<int>q;
q.push(be);
while(q.size()){
int t = q.front();
q.pop();
for(int i = h[t];~i;i = ne[i]){
int k = e[i];
if(!color[k]){//如果当前点k未染色,则染为与点t相对的颜色
color[k] = 3 - color[t];
q.push(k);
}
if(color[k] == color[t]) return 0;//如果已经染色,且相邻节点t与k同色,则不是二分图
}
}
return 1;
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
for(int i = 1;i <= m;i++){
int a,b;cin >> a >> b;
add(a,b);add(b,a);
}
for(int i = 1;i <= n;i++){
if(!color[i]){
if(uuz(i) == 0) {
cout << "No";
return 0;
}
}
}
cout << "Yes";
}
最大匹配
“任意两条边都没有公共端点”的边的集合被称为图的一组匹配。在二分图中,包含边数最多的一组匹配被称为二分图的最大匹配。
 例如图中红边集合为一种最大匹配方案。
例如图中红边集合为一种最大匹配方案。
匈牙利算法
又称增广路算法,二分图的一组匹配S是最大匹配,当且仅当图中不存在S的增广路。
时间复杂度 $O(NM)$,实际效率较高。
//https://www.acwing.com/problem/content/863/
#include <iostream>
#include <cstring>
using namespace std;
const int N = 510, M = 100005;
int n1, n2, m;
int h[N], e[M], ne[M], idx;
int match[N],res;//match[b] = a; 即为a->b的匹配
bool st[N];
void add(int a, int b) {
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
bool find(int x) {
for (int i = h[x]; i != -1;i = ne[x]) {
int y = e[i];
if (!st[y]) {//如果某个点没被预定
st[y] = 1;//预定这个点
if (match[y] == 0 || find(match[y])) {
//如果这个点没有匹配的对象或其匹配的对象能匹配其它点
match[y] = x;//则y与x匹配
return 1;
}
}
}
return 0;//如果全被预定了,则匹配失败
}
int main() {
cin >> n1 >> n2 >> m;
memset(h, -1, sizeof h);
while (m--){
int a, b; cin >> a >> b;
add(a, b);//只连一边(左到右),只有确定集合A到B只有单向关系,两个节点编号才可以相同,否则应让b加上一个偏移
}
for (int i = 1; i <= n1;i++) {//n1轮
memset(st, 0, sizeof st);
//因为每次模拟匹配的预定情况都是不一样的所以每轮模拟都要初始化
if (find(i)) res++;
}
cout << res;
}
结果$match[v_i] = u_i$表示集合v中的点和集合u中的点完成配对。
无向图的最大匹配
只能求最二分图大匹配(即没有奇环),诺为一般图,则应换用带花树算法
//https://vjudge.net/problem/HDU-2444
//染色且只匹配当前颜色为1的点
//或者最终答案直接除以2(貌似这种具体方案不好求?)
#include <iostream>
#include <vector>
#include <cstring>
const int N = 205,M = N*N;
int n,m;
int h[N],e[M],ne[M],idx;
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
bool vis[N];
int match[N],color[N];
bool dfs(int x,int c){
color[x] = c;
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(!color[y]) {
if(dfs(y,3-c) == 0) return 0;
}
else if(color[y] == c) return 0;
}
return 1;
}
bool find(int x){
if(color[x] != 1) return 0;//只匹配颜色为1的点
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(!vis[y]){
vis[y] = 1;
if(!match[y] || find(match[y])){
match[y] = x;
return 1;
}
}
}
return 0;
}
void sol(){
for(int i = 1;i <= m;i++){
int a,b;std::cin >> a >> b;
add(a,b); add(b,a);
}
for(int i = 1;i <= n;i++){
if(!color[i]){
if(dfs(i,1) == 0) {std::cout << "No\n";return;}//前提必须是二分图
}
}
int ans = 0;
for(int i = 1;i <= n;i++){
std::memset(vis,0,sizeof vis);
ans += find(i);
}
std::cout << ans << '\n';
}
int main(){
while(std::cin >> n >> m) {
idx = 0;
for(int i = 1;i <= n;i++){
h[i] = -1;
color[i] = match[i] = 0;
}
sol();
}
}
多重匹配
const int N = 303;
int n1,n2,m;
int g[N][N];
std::set<int>se[N];
bool vis[N];
bool find(int x){
for(int y = 1;y <= n1;y++){
if(g[x][y] && !vis[y]){
vis[y] = 1;
if(se[y].size() < m){//如果当前组容量有剩余,则直接加入
se[y].insert(x);
return 1;
}
else if(se[y].size() == m){//如果已经满了
for(auto &x2:se[y]){//尝试从当前组移出一个到其它组
if(find(x2,mid)){
se[y].erase(x2);
se[y].insert(x);
return 1;
}
}
}
}
}
return 0;
}
bool check(){
for(int i = 1;i <= n1;i++) se[i].clear();
for(int i = n1+1;i <= n1+n2;i++){
std::memset(vis,0,sizeof vis);
if(find(i) == 0) return 0;
}
return 1;
}
HK 算法
Hopcroft–Karp算法,时间复杂度为$O(M\sqrt{N})$,实际表现较好
//【模板】二分图最大匹配 https://www.luogu.com.cn/problem/P3386
#include <iostream>
#include <queue>
#include <cstring>
struct HK{
int n1,n2,dis;
std::vector<int>cx,cy,dx,dy,vis;
std::vector<std::vector<int>>g;
const int INF = 0x3f3f3f3f;
HK(int _n1,int _n2){
n1 = _n1,n2 = _n2;
g.assign(n1+1,{});
}
void add(int a,int b){
g[a].emplace_back(b);
}
bool bfs(){
std::queue<int>q;
dx = std::vector<int>(n1+1,-1);
dy = std::vector<int>(n2+1,-1);
dis = INF;
for(int i = 1;i <= n1;i++){
if(cx[i] == -1){
q.push(i);
dx[i] = 0;
}
}
while(q.size()){
int x = q.front();
q.pop();
if(dx[x] > dis) break;
for(auto &y:g[x]){
if(dy[y] == -1){
dy[y] = dx[x] + 1;
if(cy[y] == -1) dis = dy[y];
else{
dx[cy[y]] = dy[y]+1;
q.push(cy[y]);
}
}
}
}
return dis != INF;
}
bool dfs(int x){
for(auto &y:g[x]){
if(!vis[y] && dy[y] == dx[x] + 1){
vis[y] = 1;
if(cy[y] != -1 && dy[y] == dis) continue;
if(cy[y] == -1 || dfs(cy[y])){
cy[y] = x;
cx[x] = y;
return 1;
}
}
}
return 0;
}
int sol(){
int ans = 0;
cx = std::vector<int>(n1+1,-1);
cy = std::vector<int>(n2+1,-1);
while(bfs()) {
vis = std::vector<int>(n2+1,0);
for(int i = 1;i <= n1;i++){
if(cx[i] == -1 && dfs(i)) ans++;
}
}
return ans;
}
};
int main(){
int n1,n2,m;
std::cin >> n1 >> n2 >> m;
HK hk(n1,n2);
for(int i = 1;i <= m;i++){
int a,b;std::cin >> a >> b;//n1[] -> n2[]
hk.add(a,b);
}
std::cout << hk.sol() << '\n';
// for(int i = 1;i <= n1;i++){//具体方案,cx[]为左边的点匹配到的方案,cy[]为右边的点匹配到的方案
// if(hk.cx[i] != -1) {//-1则为匹配失败
// std::cout << i << ' ' << hk.cx[i] << '\n';
// }
// }
}
转为网络流模型
边权设为1,源点向左边集合所有点连边,右边集合所有点向汇点连边。求最大流即可。
时间复杂度 $O(M\sqrt{N})$
//基于Dinic实现 【模板】二分图最大匹配 https://www.luogu.com.cn/problem/P3386
#include <iostream>
#include <queue>
#include <cstring>
const int INF = 0x3f3f3f3f;
const int N = 1003,M = 400005;
int h[N],e[M],ne[M],idx,w[M];
int n1,n2,m;
int s,t;
int maxflow;
int d[N],now[N];
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
bool bfs(){
memset(d,0,sizeof d);
std::queue<int>q;
q.push(s);
d[s] = 1;
now[s] = h[s];
while(q.size()){
int x = q.front();
q.pop();
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(!w[i] || d[y]) continue;
d[y] = d[x]+1;
now[y] = h[y];
q.push(y);
if(y == t) return 1;
}
}
return 0;
}
int dfs(int x,int flow){
if(x == t) return flow;
int res = 0;
for(int i = now[x];~i && flow;i = ne[i]){
now[x] = i;
int y = e[i];
if(!w[i] || d[y] != d[x]+1) continue;
int k = dfs(y,std::min(flow,w[i]));
if(!k) d[y] = 0;
w[i] -= k;
w[i^1] += k;
flow -= k;
res += k;
}
return res;
}
int main(){
std::memset(h,-1,sizeof h);
std::cin >> n1 >> n2 >> m;
s = 0,t = n1+n2+1;
for(int i = 1;i <= m;i++){
int a,b;std::cin >> a >> b;
add(a,b+n1,1);
add(b+n1,a,0);
}
for(int i = 1;i <= n1;i++) add(s,i,1),add(i,s,0);
for(int i = n1+1;i <= n1+n2;i++) add(i,t,1),add(t,i,0);//如果B集合每个点可以容下最多m个A集合中的点,则这里边权改为m即可
while(bfs()) maxflow += dfs(s,INF);
std::cout << maxflow << '\n';
// for(int i = 1;i < idx;i += 2){//具体方案,遍历所有反边
// if(w[i]) {//如果反边还剩流量且端点不为源点或汇点
// if(e[i] == s || e[i^1] == t) continue;
// std::cout << e[i] << ' ' << e[i^1] - n1 << '\n';
// }
// }
}
常见问题模型
二分图匹配的模型有两个要素:
- 节点能分成独立的两个集合,每个集合内部有0条边。
- 每个节点只能与1条匹配边相连。
给定一个 N 行 N列的棋盘,已知某些格子禁止放置。求最多能往棋盘上放多少块的长度为 2、宽度为 1 的骨牌,并且任意两张骨牌都不重叠。
将骨牌看作无向边,在相邻的两个格子连边。如果把棋盘黑白染色(行号加列号为偶数染成白色,否则染成黑色)。那么相邻的两个格子颜色不同,有连边。同色的两个格子不相邻,没有边相连。该图是一张二分图,二分图的最大匹配即为最多能放骨牌的个数。
#include <iostream>
#include <cstring>
using namespace std;
const int N = 105;
int n,t;
int a[N][N];
pair<int,int> match[N][N];
bool st[N][N];
int dx[] ={-1,1,0,0},dy[] = {0,0,-1,1};
bool find(pair<int,int>p){
auto [x,y] = p;
for(int i = 0;i < 4;i++){
int nx = x + dx[i],ny = y + dy[i];
if(nx < 1 || nx > n || ny < 1 || ny > n || a[nx][ny]) continue;
if(!st[nx][ny]){
st[nx][ny] = 1;
if(!match[nx][ny].first || find(match[nx][ny])){
match[nx][ny] = {x,y};
return 1;
}
}
}
return 0;
}
int main(){
cin >> n >> t;
while(t--){
int x,y;cin >> x >> y;
a[x][y] = 1;
}
int ans = 0;
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
if((i+j)&1 || a[i][j]) continue;
memset(st,0,sizeof st);
ans += find({i,j});
}
}
cout << ans;
}
P10937 車的放置 - 洛谷 (luogu.com.cn)
给定一个 N 行 M 列的棋盘,已知某些格子禁止放置。问棋盘上最多能放多少个不能互相攻击的車(同行或同列只能有一个车)。
#include <iostream>
#include <cstring>
using namespace std;
const int N = 205,M = N*N;
int n,m,t;
int a[N][N];
int h[N],e[M],ne[M],idx;
bool st[N];
int match[N];
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
bool find(int x){
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(!st[y]){
st[y] = 1;
if(!match[y] || find(match[y])){
match[y] = x;
return 1;
}
}
}
return 0;
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m >> t;
while(t--){
int x,y;cin >> x >> y;
a[x][y] = 1;
}
for(int i = 1;i <= n;i++){
for(int j = 1;j <= m;j++){
if(a[i][j] == 0) add(i,j);
}
}
int ans = 0;
for(int i = 1;i <= n;i++){
memset(st,0,sizeof st);
ans += find(i);
}
cout << ans;
}
最大权匹配
KM算法
时间复杂度$O(N^3)$
//【模板】二分图最大权完美匹配 https://www.luogu.com.cn/problem/P6577
//诺要求最小权,只需将结构体例的INF和-INF,min和max对换
#include<bits/stdc++.h>
using namespace std;
const long long INF = 1e18;
const int N = 505;
int n1,n2,m;
struct KM {
int n;
int pl[N], pr[N], fa[N];
long long g[N][N], wl[N], wr[N], sl[N];
bitset<N> vis;
long long tot;
void init(int _n) {
n = _n;
for (int i = 1; i <= n; i++) {
fill(g[i] + 1, g[i] + n + 1, -INF);//本题含有负权边,初始化为-INF,否则初始化为0
wl[i] = wr[i] = sl[i] = 0;
pl[i] = pr[i] = fa[i] = 0;
}
}
void add(int x, int y, long long z) {
g[x][y] = max(g[x][y],z);
}
void get(int x) {
for (int i = 1; i <= n; i++) {
sl[i] = INF;
fa[i] = 0;
}
vis.reset();
pr[0] = x;
int cr = 0;
while (pr[cr]) {
long long mn = INF;
vis[cr] = 1;
int cl = pr[cr];
for (int i = 1; i <= n; i++) {
if (!vis[i]) {
const long long t1 = wl[cl] + wr[i] - g[cl][i];
if (sl[i] > t1) {
fa[i] = cr;
sl[i] = t1;
}
mn = min(mn, sl[i]);
}
}
for (int i = 0; i <= n; i++) {
if (vis[i]) {
wr[i] += mn;
wl[pr[i]] -= mn;
}
else sl[i] -= mn;
}
cr = 0;
for (int i = 1; i <= n; i++) {
if (!vis[i] && sl[i] == 0) {
cr = i;
break;
}
}
}
while (cr) {
pr[cr] = pr[fa[cr]];
cr = fa[cr];
}
}
void sol() {
tot = 0;
for (int i = 1; i <= n; i++) get(i);
for (int i = 1; i <= n; i++) pl[pr[i]] = i;
for (int i = 1; i <= n; i++) tot += g[i][pl[i]];
}
} km;
int main(){
ios::sync_with_stdio(0); cin.tie(0);
std::cin >> n1 >> m; n2 = n1;
km.init(max(n1,n2));
while(m--){
int a,b,c; cin >> a >> b >> c;
km.add(a,b,c);
}
km.sol();
cout << km.tot << '\n';
// for(int i = 1;i <= n1;i++){
// if(km.g[i][km.pl[i]] > -INF) {
// std::cout << i << "->" << km.pl[i] << ' ';
// }
// }
}
//非完美匹配下的最大权 https://uoj.ac/problem/80
#include<bits/stdc++.h>
using namespace std;
const long long INF = 1e18;
const int N = 505;
int n1,n2,m;
struct KM {
int n;
int pl[N], pr[N], fa[N];
long long g[N][N], wl[N], wr[N], sl[N];
bitset<N> vis;
long long tot;
void init(int _n) {
n = _n;
for (int i = 1; i <= n; i++) {
fill(g[i] + 1, g[i] + n + 1, 0);//边权初始化为0,本题均为正权边
wl[i] = wr[i] = sl[i] = 0;
pl[i] = pr[i] = fa[i] = 0;
}
}
void add(int x, int y, long long z) {
g[x][y] = max(g[x][y],z);
}
void get(int x) {
for (int i = 1; i <= n; i++) {
sl[i] = INF;
fa[i] = 0;
}
vis.reset();
pr[0] = x;
int cr = 0;
while (pr[cr]) {
long long mn = INF;
vis[cr] = 1;
int cl = pr[cr];
for (int i = 1; i <= n; i++) {
if (!vis[i]) {
const long long t1 = wl[cl] + wr[i] - g[cl][i];
if (sl[i] > t1) {
fa[i] = cr;
sl[i] = t1;
}
mn = min(mn, sl[i]);
}
}
for (int i = 0; i <= n; i++) {
if (vis[i]) {
wr[i] += mn;
wl[pr[i]] -= mn;
}
else sl[i] -= mn;
}
cr = 0;
for (int i = 1; i <= n; i++) {
if (!vis[i] && sl[i] == 0) {
cr = i;
break;
}
}
}
while (cr) {
pr[cr] = pr[fa[cr]];
cr = fa[cr];
}
}
void sol() {
tot = 0;
for (int i = 1; i <= n; i++) get(i);
for (int i = 1; i <= n; i++) pl[pr[i]] = i;
for (int i = 1; i <= n; i++) tot += g[i][pl[i]];
}
} km;
int main(){
ios::sync_with_stdio(0); cin.tie(0);
cin >> n1 >> n2 >> m;
km.init(max(n1,n2));//相当于在节点较少的集合添加了虚拟点
while(m--){
int a,b,c; cin >> a >> b >> c;
km.add(a,b,c);
}
km.sol();
// cout << km.tot << '\n';
// for(int i = 1;i <= n1;i++){
// if(km.g[i][km.pl[i]]) {
// std::cout << i << "->" << km.pl[i] << '\n';
// }
// }
}
转为费用流模型
- 新建源点s1和汇点s2。
源点向每个左部节点连一条流量为1,费用为0的边。- 每个
右部节点向汇点连一条流量为1,费用为0的边。 - 对于二分图中每条左部到右部的边,连一条流量为1,费用为边权的边。
- 另外如果考虑非完美匹配,对于每个
左部节点还需要向汇点连一条流量为1,费用为0的边。最大费用的前提是最大流。 - 求这个网络的最大费用最大流即可,此时网络的最大流量一定为左部节点的数量,而最大流量下的最大费用即对应一个最大权匹配方案。
时间复杂度较高,比KM算法慢了大概一个数量级,如果数据范围较大建议换KM算法。
//模板 二分图最大权完美匹配 https://www.luogu.com.cn/problem/P6577
//基于Dinic实现,实际并不能通过本题,只作为实现参考模版,一般只能通过节点总数<=500的图
#include <iostream>
#include <queue>
#include <cstring>
const long long INF = 1e18;
const int N = 1005,M = 1000006;//N开n1+n2+5,M开n1*n2*3
int n1,n2,m;
int h[N],e[M],ne[M],idx;
long long c[M],w[M];
void add(int a,int b,int x,int y){
c[idx] = y,w[idx] = x,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
int s1,s2;
long long maxflow,maxcost;
long long dist[N];
int now[N];
bool vis[N];
bool spfa(){
std::memset(vis,0,sizeof vis);
for(int i = 0;i <= n1+n2+1;i++) dist[i] = -INF;
std::queue<int>q;
q.push(s1);
dist[s1] = 0;
now[s1] = h[s1];
while(q.size()){
int x = q.front();
q.pop();
vis[x] = 0;
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(w[i] && dist[y] < dist[x] + c[i]) {
dist[y] = dist[x] + c[i];
now[y] = h[y];
if(!vis[y]) {
vis[y] = 1;
q.push(y);
}
}
}
}
return dist[s2] > -INF;
}
long long dinic(int x,long long flow){
if(x == s2) return flow;
long long res = 0;
vis[x] = 1;
for(int i = now[x];~i && flow;i = ne[i]){
int y = e[i];
now[x] = i;
if(w[i] && dist[y] == dist[x] + c[i] && !vis[y]){
long long k = dinic(y,std::min(flow,w[i]));
if(!k) dist[y] = 0;
w[i] -= k;
w[i^1] += k;
res += k;
flow -= k;
maxcost += k * c[i];
}
}
vis[x] = 0;
return res;
}
int main(){
std::ios::sync_with_stdio(false);std::cin.tie(0);
std::memset(h,-1,sizeof h);
std::cin >> n1 >> m; n2 = n1;
s1 = 0,s2 = n1+n2+1;
for(int i = 1;i <= m;i++){
int x,y,z;std::cin >> x >> y >> z;
add(x,y+n1,1,z); add(y+n1,x,0,-z);
}
for(int i = 1;i <= n1;i++){
add(s1,i,1,0); add(i,s1,0,0);
// add(i,s2,1,0); add(i,s2,0,0); //加上即为非完美匹配下的最大权
}
for(int i = 1;i <= n2;i++){
add(i+n1,s2,1,0); add(s2,i+n1,0,0);
}
while(spfa()) maxflow += dinic(s1,INF);
std::cout << maxcost << '\n';
// for(int i = 1;i < idx;i += 2){
// if(w[i]){
// if(e[i] == s1 || e[i^1] == s2) continue;
// std::cout << e[i] << "->" << e[i^1] - n1 << '\n';
// }
// }
}
最小点覆盖
求出一个最小的点集S,使得任意一条边都至少有一个端点属于S
König定理:最小点覆盖=最大匹配
二分图最小覆盖的模型特点是:每条边有2个端点,二者至少选择一个。
[P6062 USACO05JAN] Muddy Fields G - 洛谷 (luogu.com.cn)
给定一个N*M的网格,其中一些地面时泥泞的,你需要用一些宽度为1,长度任意的木板将所有泥地盖住,同时不能盖住干净的地面,木板可以重叠。N,M <= 50。
每块泥地要么被第i行的一个横着的木板盖住,要么被第j列的一个竖着的木板盖住,二者至少选择一个,满足二分图最小覆盖特点。把行木板作为左边,列木板作为右边,对于每块泥地,在它所属的行木板与列木板之间连边,求出二分图的最小覆盖,即为最少得木板覆盖所有泥地的答案。
#include <iostream>
#include <vector>
#include <cstring>
using namespace std;
const int N = 55;
int n,m;
string s[N];
int r[N][N],c[N][N],cnt;
bool st[N*N];
int match[N*N];
vector<int>e[N*N];
void add(int a,int b){
e[a].emplace_back(b);
}
bool find(int x){
for(int y:e[x]){
if(!st[y]){
st[y] = 1;
if(!match[y] || find(match[y])){
match[y] = x;
return 1;
}
}
}
return 0;
}
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++){
cin >> s[i];s[i] = ' ' + s[i];
}
for(int i = 1;i <= n;i++){
for(int j = 1;j <= m;j++){
if(!r[i][j] && s[i][j] == '*'){
if(r[i][j-1]) r[i][j] = r[i][j-1];
else r[i][j] = ++cnt;
}
}
}
int cnt1 = cnt;
for(int j = 1;j <= m;j++){
for(int i = 1;i <= n;i++){
if(!c[i][j] && s[i][j] == '*'){
if(c[i-1][j]) c[i][j] = c[i-1][j];
else c[i][j] = ++cnt;
add(r[i][j],c[i][j]);
}
}
}
int ans = 0;
for(int i = 1;i <= cnt1;i++){
memset(st,0,sizeof st);
ans += find(i);
}
cout << ans;
}
最大独立集
选最多的点,满足两两之间没有边相连。
定理:设G是有N个点的二分图,则G的最大独立集等于顶点数N-最大匹配数
求解一个图中的最大独立集等价于求解其反图的最大团(即两两之间都有连边)。
P10939 骑士放置 - 洛谷 (luogu.com.cn)
给点N*M的棋盘,其中有一些格子禁止放旗子,问棋盘上最多能放多少个互不攻击的骑士(与象棋的马类似,攻击‘日’字)。N,M <= 100。
将棋盘黑白染色后,可以发现,一匹马可以跳到的格子的颜色一定与当前所在格子颜色相反。于是我们可以将每个位置与能跳到的位置连边,这样就构成了一个二分图(所有白色格子是一部分,所有黑色格子是一部分)。如果想让所有的马都不能互相吃,那么这个二分图里一条边的两个点最多只能选一个点放马,所以这题就是让我们在一个二分图里相邻的两个点只能选一个,问最多能选多少个点。

#include <iostream>
#include <cstring>
using namespace std;
const int N = 105;
int n,m,t;
int g[N][N];
pair<int,int> match[N][N];
bool st[N][N];
int dx[] = {-2,-1,1,2,2,1,-1,-2},dy[] = {1,2,2,1,-1,-2,-2,-1};
bool find(pair<int,int>p){
auto &[x,y] = p;
for(int i = 0;i < 8;i++){
int nx = x + dx[i],ny = y + dy[i];
if(nx < 1 || nx > n || ny < 1 || ny > m || g[nx][ny]) continue;
if(!st[nx][ny]){
st[nx][ny] = 1;
if(!match[nx][ny].first || find(match[nx][ny])){
match[nx][ny] = {x,y};
return 1;
}
}
}
return 0;
}
int main(){
cin >> n >> m >> t;
for(int i = 1;i <= t;i++){
int x,y;cin >> x >> y;
g[x][y] = 1;
}
int ans = 0;
for(int i = 1;i <= n;i++){
for(int j = 1;j <= m;j++){
if(g[i][j] || (i+j)%2) continue;
memset(st,0,sizeof st);
ans += find({i,j});
}
}
cout << n*m-t - ans;
}
最小路径覆盖
在一个有无环向图中,找出最少得路径,使得这些路径经过了所有点。特别的,每个点自己也可以称为是路径覆盖,只不过路径的长度是0。
最小不相交路径覆盖
每一条路径经过的顶点各不相同。
原图G中每个点如果
a能直接到达b,就加边a->b这样就得到了一个G的拆点二分图G2。定理:DAG图G的最小不相交路径覆盖包含的路径条数 = n - 拆点二分图G2的最大匹配数
一开始每个点都是独立的为一条路径,总共有n条不相交路径。我们每次在二分图里找一条匹配边就相当于把两条路径合成了一条路径,也就相当于路径数减少了1。所以找到了几条匹配边,路径数就减少了多少。所以最小路径覆盖=原图的结点数-新图的最大匹配数
//街道清理 https://www.luogu.com.cn/problem/UVA1184
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
const int N = 205;
int n,m;
vector<int>e[N];
int match[N];
bool st[N];
bool find(int x){
for(int y:e[x]){
if(!st[y]){
st[y] = 1;
if(!match[y] || find(match[y])){
match[y] = x;
return 1;
}
}
}
return 0;
}
void sol(){
memset(match,0,sizeof match);
cin >> n >> m;
for(int i = 1;i <= n;i++) e[i].clear();
for(int i = 1;i <= m;i++){
int a,b;cin >> a >> b;
e[a].emplace_back(b);
}
int ans = 0;
for(int i = 1;i <= n;i++){
memset(st,0,sizeof st);
ans += find(i);
}
cout << n - ans << '\n';
}
int main(){
int T;cin >> T;
while(T--) sol();
}
最小可相交路径覆盖
每一条路径经过的顶点可以相同。
思路:先用floyd求出原图的传递闭包,即如果
a能直接/间接到达b,那么就加边a->b。得到有向无环图G2,再在G2上求最小不相交路径覆盖即可。
//宝藏探索 https://vjudge.net/problem/OpenJ_Bailian-2594
#include <iostream>
#include <cstring>
const int N = 505;
int n,m;
int g[N][N];
void floyd(){
for(int k = 1;k <= n;k++){
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
g[i][j] |= g[i][k]&g[k][j];
}
}
}
}
bool vis[N];
int match[N];
bool find(int x){
for(int y = 1;y <= n;y++){
if(g[x][y] && !vis[y]){
vis[y] = 1;
if(!match[y] || find(match[y])) {
match[y] = x;
return 1;
}
}
}
return 0;
}
void sol(){
std::memset(g,0,sizeof g);
for(int i = 1;i <= m;i++){
int a,b;std::cin >> a >> b;
g[a][b] = 1;
}
floyd();
int ans = 0;
std::memset(match,0,sizeof match);
for(int i = 1;i <= n;i++){
std::memset(vis,0,sizeof vis);
ans += find(i);
}
std::cout << n - ans << '\n';
}
int main(){
while(std::cin >> n >> m,n || m) sol();
}
一般图最大匹配
一般图匹配和二分图匹配不同的是,图可能存在奇环。一般图的最大匹配可以用带花树算法(blossom alogrithm)解决。
时间复杂度在$O(NM) 到 O(N^3)$左右
//【模板】一般图最大匹配 https://www.luogu.com.cn/problem/P6113
//模版来自sse
#include <bits/stdc++.h>
using namespace std;
namespace blossom_tree {
const int N = 1003;
vector<int> e[N];
int lk[N],rt[N],f[N],dfn[N],typ[N],q[N];
int id,h,t,n;
int lca(int u,int v) {
++id;
while(1) {
if(u){
if (dfn[u]==id) return u;
dfn[u]=id;u=rt[f[lk[u]]];
}
swap(u,v);
}
}
void blm(int u,int v,int a) {
while (rt[u]!=a) {
f[u]=v;
v=lk[u];
if (typ[v]==1) typ[q[++t]=v]=0;
rt[u]=rt[v]=a;
u=f[v];
}
}
void aug(int u) {
while (u) {
int v=lk[f[u]];
lk[lk[u]=f[u]]=u;
u=v;
}
}
void bfs(int root) {
memset(typ+1,-1,n*sizeof typ[0]);
iota(rt+1,rt+n+1,1);
typ[q[h=t=1]=root]=0;
while (h<=t) {
int u=q[h++];
for (int v:e[u]) {
if (typ[v]==-1) {
typ[v]=1;f[v]=u;
if (!lk[v]) return aug(v);
typ[q[++t]=lk[v]]=0;
} else if (!typ[v]&&rt[u]!=rt[v]) {
int a=lca(rt[u],rt[v]);
blm(v,u,a);blm(u,v,a);
}
}
}
}
int max_general_match(int N,vector<pair<int,int>> edges){
n=N;id=0;
memset(f+1,0,n*sizeof f[0]);
memset(dfn+1,0,n*sizeof dfn[0]);
memset(lk+1,0,n*sizeof lk[0]);
for (int i=1;i<=n;i++) e[i].clear();
mt19937_64 rnd(114514);
shuffle(edges.begin(),edges.end(),rnd);
for (auto [u,v]:edges) {
e[u].push_back(v),e[v].push_back(u);
if (!(lk[u]||lk[v])) lk[u]=v,lk[v]=u;
}
int res = 0;
for (int i=1;i<=n;i++) if (!lk[i]) bfs(i);
for (int i=1;i<=n;i++) res += !!lk[i];
return res/2;
}
}
using blossom_tree::max_general_match,blossom_tree::lk;
int main(){
int n,m; std::cin >> n >> m;
std::vector<std::pair<int,int>>e;
while(m--){
int a,b;std::cin >> a >> b;
e.push_back({a,b});
}
std::cout << max_general_match(n,e) << '\n';//N:1_idx; edges:0_idx
std::vector<int>ans(n+1);
for(int i = 1;i <= n;i++){//if(lk[i]) i <-> lk[i]
ans[i] = lk[i];
}
for(int i = 1;i <= n;i++){
std::cout << ans[i] << ' ';//if(ans[i] == 0) not_match
}
}
一般图最大权匹配
时间复杂度$O(N^3)$
//https://www.luogu.com.cn/problem/P6699
#include <bits/stdc++.h>
using namespace std;
namespace Graph {
const int N = 403 * 2; //两倍点数
typedef int T; //权值大小
const T inf = numeric_limits<int>::max() >> 1;
struct Q { int u, v; T w; } e[N][N];
T lab[N];
int n, m = 0, id, h, t, lk[N], sl[N], st[N], f[N], b[N][N], s[N], ed[N], q[N];
vector<int> p[N];
#define dvd(x) (lab[x.u] + lab[x.v] - e[x.u][x.v].w * 2)
#define FOR(i, b) for (int i = 1; i <= (int)(b); i++)
#define ALL(x) (x).begin(), (x).end()
#define ms(x, i) memset(x + 1, i, m * sizeof x[0])
void upd(int u, int v) {
if (!sl[v] || dvd(e[u][v]) < dvd(e[sl[v]][v])) {
sl[v] = u;
}
}
void ss(int v) {
sl[v] = 0;
FOR(u, n) {
if (e[u][v].w > 0 && st[u] != v && !s[st[u]]) {
upd(u, v);
}
}
}
void ins(int u) {
if (u <= n) { q[++t] = u; }
else {
for (int v : p[u]) ins(v);
}
}
void mdf(int u, int w) {
st[u] = w;
if (u > n) {
for (int v : p[u]) mdf(v, w);
}
}
int gr(int u, int v) {
v = find(ALL(p[u]), v) - p[u].begin();
if (v & 1) {
reverse(1 + ALL(p[u]));
return (int)p[u].size() - v;
}
return v;
}
void stm(int u, int v) {
lk[u] = e[u][v].v;
if (u <= n) return;
Q w = e[u][v];
int x = b[u][w.u], y = gr(u, x);
for (int i = 0; i < y; i++) {
stm(p[u][i], p[u][i ^ 1]);
}
stm(x, v);
rotate(p[u].begin(), y + ALL(p[u]));
}
void aug(int u, int v) {
int w = st[lk[u]];
stm(u, v);
if (!w) return;
stm(w, st[f[w]]), aug(st[f[w]], w);
}
int lca(int u, int v) {
for (++id; u | v; swap(u, v)) {
if (!u) continue;
if (ed[u] == id) return u;
ed[u] = id;
if (u = st[lk[u]]) u = st[f[u]];
}
return 0;
}
void add(int u, int a, int v) {
int x = n + 1, i, j;
while (x <= m && st[x]) ++x;
if (x > m) ++m;
lab[x] = s[x] = st[x] = 0;
lk[x] = lk[a];
p[x].clear();
p[x].push_back(a);
for (i = u; i != a; i = st[f[j]]) {
p[x].push_back(i);
p[x].push_back(j = st[lk[i]]);
ins(j);
}
reverse(1 + ALL(p[x]));
for (i = v; i != a; i = st[f[j]]) {
p[x].push_back(i);
p[x].push_back(j = st[lk[i]]);
ins(j);
}
mdf(x, x);
FOR(i, m) {
e[x][i].w = e[i][x].w = 0;
}
memset(b[x] + 1, 0, n * sizeof b[0][0]);
for (int u : p[x]) {
FOR(v, m) {
if (!e[x][v].w || dvd(e[u][v]) < dvd(e[x][v])) {
e[x][v] = e[u][v], e[v][x] = e[v][u];
}
}
FOR(v, n) {
if (b[u][v]) { b[x][v] = u; }
}
}
ss(x);
}
void ex(int u) {
for (int x : p[u]) mdf(x, x);
int a = b[u][e[u][f[u]].u], r = gr(u, a);
for (int i = 0; i < r; i += 2) {
int x = p[u][i], y = p[u][i + 1];
f[x] = e[y][x].u;
s[x] = 1;
s[y] = sl[x] = 0;
ss(y), ins(y);
}
s[a] = 1, f[a] = f[u];
for (int i = r + 1; i < p[u].size(); i++) {
s[p[u][i]] = -1;
ss(p[u][i]);
}
st[u] = 0;
}
bool on(const Q &e) {
int u = st[e.u], v = st[e.v];
if (s[v] == -1) {
f[v] = e.u, s[v] = 1;
int a = st[lk[v]];
sl[v] = sl[a] = s[a] = 0;
ins(a);
} else if (!s[v]) {
int a = lca(u, v);
if (!a) {
return aug(u, v), aug(v, u), 1;
} else {
add(u, a, v);
}
}
return 0;
}
bool bfs() {
ms(s, -1), ms(sl, 0);
h = 1, t = 0;
FOR(i, m) {
if (st[i] == i && !lk[i]) {
f[i] = s[i] = 0;
ins(i);
}
}
if (h > t) return 0;
while (1) {
while (h <= t) {
int u = q[h++];
if (s[st[u]] == 1) continue;
FOR(v, n) {
if (e[u][v].w > 0 && st[u] != st[v]) {
if (dvd(e[u][v])) upd(u, st[v]);
else if (on(e[u][v])) return 1;
}
}
}
T x = inf;
for (int i = n + 1; i <= m; i++) {
if (st[i] == i && s[i] == 1) {
x = min(x, lab[i] >> 1);
}
}
FOR(i, m) {
if (st[i] == i && sl[i] && s[i] != 1) {
x = min(x, dvd(e[sl[i]][i]) >> s[i] + 1);
}
}
FOR(i, n) {
if (~s[st[i]]) {
if ((lab[i] += (s[st[i]] * 2 - 1) * x) <= 0) return 0;
}
}
for (int i = n + 1; i <= m; i++) {
if (st[i] == i && ~s[st[i]]) {
lab[i] += (2 - s[st[i]] * 4) * x;
}
}
h = 1, t = 0;
FOR(i, m) {
if (st[i] == i && sl[i] && st[sl[i]] != i && !dvd(e[sl[i]][i]) && on(e[sl[i]][i])) {
return 1;
}
}
for (int i = n + 1; i <= m; i++) {
if (st[i] == i && s[i] == 1 && !lab[i]) ex(i);
}
}
return 0;
}
template<typename TT> long long work(int N, const vector<tuple<int, int, TT>> &edges) {
ms(ed, 0), ms(lk, 0);
n = m = N; id = 0;
iota(st + 1, st + n + 1, 1);
T wm = 0; long long r = 0;
FOR(i, n) FOR(j, n) {
e[i][j] = {i, j, 0};
}
for (auto [u, v, w] : edges) {
wm = max(wm, e[v][u].w = e[u][v].w = max(e[u][v].w, (T)w));
}
FOR(i, n) { p[i].clear(); }
FOR(i, n) FOR(j, n) {
b[i][j] = i * (i == j);
}
fill_n(lab + 1, n, wm);
while (bfs()) {};
FOR(i, n) if (lk[i]) {
r += e[i][lk[i]].w;
}
return r / 2;
}
auto match() {
vector<array<int, 2>> ans;
FOR(i, n) if (lk[i]) {
ans.push_back({i, lk[i]});
}
return ans;
}
} // namespace Graph
using Graph::work, Graph::match;
void soviet(){
int n,m; std::cin >> n >> m;
std::vector<std::tuple<int,int,long long>>edges(m);
for(auto &[a,b,c]:edges){
std::cin >> a >> b >> c;
}
std::cout << work(n,edges) << '\n';//n:1_idx; edges:0_idx
std::vector<int>ans(n+1);
auto v = match();
for(auto [x,y]:v){// x <-> y
ans[x] = y;
}
for(int i = 1;i <= n;i++){
std::cout << ans[i] << ' ';//if(ans[i] = 0) not_match
}
}
int main() {
int M_T = 1;std::ios::sync_with_stdio(false),std::cin.tie(0);
// std::cin >> M_T;
while(M_T--){ soviet(); }
return 0;
}
基环树
n个点n条边组成的无向连通图。若不保证连通,也有可能是内/外向树/森林。
找环
可以以拓扑排序或者dfs实现: P8655 发现环 - 洛谷
基环树的直径
直径有两种情况,二者取最大值即为答案:
- 直径处于以环上某一点为根节点,且不经过环边的子树中。对每一颗子树进行树形DP求直径,取最大值。
- 经过环边,链接两个根节点x,y的子树。ans = max{d1[x]+d1[y]+dis(x,y)}。d1[i]表式以i为根节点向下能达到的最大距离,dis(i,j)表示环上两点之间的最远距离,断链成环,复制拼接,再用前缀和+单调队列优化即可O(N)求得答案。
一般处理方法
- 找到唯一的环;
- 对环之外的部分按照若干棵树处理;
- 考虑与环一起计算。
负环
SPFA判负环
如果某点的最短路所包含的边数大于等于n,则说明存在负环
//https://www.acwing.com/activity/content/problem/content/921/
//判断有向图中是否存在负环
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int N = 100005;
int n, m;
queue<int>q;
int h[N], e[N], ne[N], idx, w[N];
int dist[N], cnt[N];//dist记录1~k最短距离,cnt记录1~k边的数量
bool st[N];
void add(int a, int b, int c) {
w[idx] = c, e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
int SPFA() {
//判负环不需要初始化dist,如果存在负环,那么dist不管初始化为多少,都会被更新
//将所有点进入队列。如果只加源点可能到不了有负环的点,只能说明从源点出发不能抵达负环,而不能说明图上不存在负环。
for (int i = 1; i <= n;i++) {
st[i] = 1;
q.push(i);
}
while (q.size()){
int t = q.front();
q.pop();
st[t] = 0;
for (int i = h[t]; i != -1;i = ne[i]) {
int k = e[i];
if (dist[k] > dist[t] + w[i]) {
dist[k] = dist[t] + w[i];
cnt[k] = cnt[t] + 1;//更新
if (cnt[k] >= n) return 1;//如果到k经过的边的数量>=总点数说明存在负环
if (!st[k]) {
q.push(k);
st[k] = 1;
}
}
}
}
return 0;
}
int main() {
memset(h, -1, sizeof h);
cin >> n >> m;
while (m--){
int a, b, c; cin >> a >> b >> c;
add(a, b, c);
}
if(SPFA()) puts("Yes");
else puts("No");
}
bellman-ford判负环
bellman-ford判负环,据bellman-ford的性质最后得出的是通过不超过n-1条边的从起点到其他点的最短距离
但是如果在n-1次循环之后仍然存在边可以被松弛,那么就存在负环(因为如果没有负环n-1次就已经确定了最短距离,具体可参考bellman-ford证明,已经是最短距离了还能被松弛,必然是存在负环)
#include <iostream>
#include <cstring>
using namespace std;
const int N = 2003,M = 10004;
int n,m;
int dist[N];
struct Edge{
int a,b,c;
}e[M];
bool bellman(){
memset(dist,0x3f,sizeof dist);
dist[1] = 0;
for(int i = 1;i <= n-1;i++){
for(int j = 1;j <= m;j++){
auto &[a,b,c] = e[j];
dist[b] = min(dist[b],dist[a] + c);
}
}
for(int i = 0;i <= m;i++){//如果在n-1次循环之后仍然存在边可以被松弛,那么就存在负环
auto &[a,b,c] = e[i];
if(dist[b] > dist[a] + c) return 1;
}
return 0;
}
int main(){
cin >> n >> m;
for(int i = 1;i <= m;i++){
cin >> e[i].a >> e[i].b >> e[i].c;
}
if(bellman()) cout << "Yes";
else cout << "No";
}
差分约束
求解差分约束系统,有 $m$ 条约束条件,每条都为形如 $x_a-x_b\geq c_k$,$x_a-x_b\leq c_k$ 或 $x_a=x_b$ 的形式,判断该差分约束系统有没有解。
| 题意 | 转化 | 连边 |
|---|---|---|
| $x_a - x_b \geq c$ | $x_b - x_a \leq -c$ | add(a, b, -c); |
| $x_a - x_b \leq c$ | $x_a - x_b \leq c$ | add(b, a, c); |
| $x_a = x_b$ | $x_a - x_b \leq 0, \space x_b - x_a \leq 0$ | add(b, a, 0), add(a, b, 0); |
判断负环,如果存在负环,则无解。
建立一个虚拟的源点0,设 $dist[0]=0$ 并向每一个点连一条权重为 $0$ 边,跑单源最短路,若图中存在负环,则给定的差分约束系统无解,否则,$x_i=dist[i]$ 为该差分约束系统的一组解。 注意到,如果 ${x_1,x_2,\dots,x_n}$ 是该差分约束系统的一组解,那么对于任意的常数 $d$,${x_1+d,x_2+d,\dots,x_n+d}$ 显然也是该差分约束系统的一组解,因为这样做差后 $d$ 刚好被消掉。
一般使用 SPFA 判断图中是否存在负环,最坏时间复杂度为 $O(nm)$。
//小 K 的农场 https://www.luogu.com.cn/problem/P1993
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int N = 20004;
int n,m;
int h[N],e[N],ne[N],w[N],idx;
int dist[N],cnt[N];
bool st[N];
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
bool spfa(){
std::memset(dist,0x3f,sizeof dist);
queue<int>q;
dist[0] = 0;
q.push(0);
while(q.size()){
int t = q.front();
q.pop();
st[t] = 0;
for(int i = h[t];~i;i = ne[i]){
int k = e[i];
if(dist[k] > dist[t] + w[i]){
dist[k] = dist[t] + w[i];
cnt[k] = cnt[t] + 1;
if(cnt[k] >= n+1) return 1;//(加入源点0后有n+1个点)
if(!st[k]){
q.push(k);
st[k] = 1;
}
}
}
}
return 0;
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
for(int i = 1;i <= m;i++){
int op,a,b,c;cin >> op;
if(op == 1){
cin >> a >> b >> c;
add(a,b,-c);
}
else if(op == 2){
cin >> a >> b >> c;
add(b,a,c);
}
else{
cin >> a >> b;
add(a,b,0);add(b,a,0);
}
}
for(int i = 1;i <= n;i++) add(0,i,0);//建立超级源点0,跑单源spfa
//也可以不建源点,直接将所有结点入队跑全源spfa
if(spfa()) cout << "No";//诺存在负环,则无解
else cout << "Yes";//否则dist[]为一组解
}
连通性相关
割点和割边
dfn[x]为每个点dfs第一次被访问的时间戳
low[x]为以下节点的时间戳的最小值 1.x的子树中的节点 2.通过一条不在搜索树上的边,能够到达x的子树的节点
从根开始的一条路径上的 dfn 严格递增,low 非严格递增
//Tarjan
void Tarjan(int u) {
low[u] = dfn[u] = ++dn; // low 初始化为当前节点 dfn
for (int v : G[u]) { // 遍历 u 的相邻节点
if (!dfn[v]) { // 如果未访问过
Tarjan(v); // 递归
low[u] = std::min(low[u], low[v]); // 未访问的和 low 取 min
} else
low[u] = std::min(low[u], dfn[v]); // 已访问的和 dfn 取 min
}
}
割点
对于一个无向图,如果把一个点删除后这个图的极大连通分量数增加了,那么这个点就是这个图的割点(又称割顶)。
诺x不是搜索树的根节点root(dfs的起点),则x是割点当且仅当搜索树上存在一个x的子节点满足dfn[x] <= low[y]
诺x是搜索树的根节点,则x是割点当且仅当搜索树上存在至少两个子节点y1,y2满足上式
//P3388 【模板】割点(割顶) https://www.luogu.com.cn/problem/P3388
#include <iostream>
#include <cstring>
using namespace std;
const int N = 200005;
int n,m;
int h[N],e[N],ne[N],idx;
int dfn[N],low[N],cut[N],dn,root;
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void tarjan(int x){
dfn[x] = low[x] = ++dn;
int son = 0;
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(!dfn[y]){
tarjan(y);
son++;
low[x] = min(low[x],low[y]);
if(x != root && dfn[x] <= low[y]) cut[x] = 1;
}
else low[x] = min(low[x],dfn[y]);
}
if(x == root && son >= 2) cut[x] = 1;
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
for(int i = 1;i <= m;i++){
int a,b;cin >> a >> b;
add(a,b);add(b,a);
}
int cnt = 0;
for(int i = 1;i <= n;i++){
if(!dfn[i]) root = i,tarjan(i);
if(cut[i]) cnt++;
}
cout << cnt << endl;
for(int i = 1;i <= n;i++){
if(cut[i]) cout << i << ' ';
}
}
割边
对于一个无向图,如果删掉一条边后图中的连通分量数增加了,则称这条边为桥或者割边。
无向边(x,y)是割边,当且仅当搜索树上存在x的一个子节点y满足dfn[x] < low[y]
//https://www.luogu.com.cn/problem/U63110
//可处理重边
#include <iostream>
#include <cstring>
using namespace std;
const int N = 100005;
int n,m;
int h[N],e[N],ne[N],idx;
int dfn[N],low[N],cut[N],dn;
void add(int a,int b){//(0 1),(2 3),(4 5)...(x y) x和x^1为两条方向相反的边
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void tarjan(int x,int edge){
dfn[x] = low[x] = ++dn;
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(!dfn[y]){
tarjan(y,i);
low[x] = min(low[x],low[y]);
if(dfn[x] < low[y]){
cut[i] = cut[i^1] = 1;
}
}
else if(i != (edge^1)) low[x] = min(low[x],dfn[y]);
}
}
void sol(){
memset(h,-1,sizeof h);
for(int i = 1;i <= m;i++){
int a,b;cin >> a >> b;
add(a,b);add(b,a);//正反边一定要同时添加
}
for(int i = 1;i <= n;i++){
if(!dfn[i]) tarjan(i,0);
}
int cnt = 0;
for(int i = 0;i < idx;i+=2){
if(cut[i]) cnt++;//e[i]到e[i^1]为一条割边
}
cout << cnt << '\n';
}
int main(){
while(cin >> n >> m,n && m){
for(int i = 1;i <= n;i++) dfn[i] = low[i] = 0;
for(int i = 0;i < idx;i++) cut[i] = 0;//注意cut清空范围
idx = dn = 0;
sol();
}
}
双连通分量
在一张连通的无向图中,对于两个点 $u$ 和 $v$,如果无论删去哪条边(只能删去一条)都不能使它们不连通,我们就说 $u$ 和 $v$ 边双连通。
在一张连通的无向图中,对于两个点 $u$ 和 $v$,如果无论删去哪个点(只能删去一个,且不能删 $u$ 或 $v$ 自己)都不能使它们不连通,我们就说 $u$ 和 $v$ 点双连通。
边双连通具有传递性,即,若 $x,y$ 边双连通,$y,z$ 边双连通,则 $x,z$ 边双连通。
点双连通不具有传递性,反例如下图,$A,B$ 点双连通,$B,C$ 点双连通,而 $A,C$ 不点双连通。

对于一个无向图中的 极大 边双连通的子图,我们称这个子图为一个 边双连通分量。
对于一个无向图中的 极大 点双连通的子图,我们称这个子图为一个 点双连通分量。
边双连通分量
不存在割边。
e-DCC的求法比较简单,先求出无向图中的所有割边,把割边删除后,剩下的图会分成若干个连通块,每一个连通块就是一个“边双连通分量”。
//https://www.luogu.com.cn/problem/P8436
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
const int N = 500005,M = 4000006;
int n,m;
int h[N],e[M],ne[M],idx;
int dfn[N],low[N],dn;
bool cut[M];
int cnt;
bool st[N];
vector<int>v[N];
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void tarjan(int x,int edge){
dfn[x] = low[x] = ++dn;
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(!dfn[y]){
tarjan(y,i);
low[x] = min(low[x],low[y]);
if(dfn[x] < low[y]){
cut[i] = cut[i^1] = 1;
}
}
else if(i != (edge^1)) low[x] = min(low[x],dfn[y]);
}
}
void dfs(int u){
st[u] = 1;
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(st[k] || cut[i]) continue;
dfs(k);
v[cnt].emplace_back(k);
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
for(int i = 1;i <= m;i++){
int a,b;scanf("%d %d",&a,&b);
add(a,b);add(b,a);
}
for(int i = 1;i <= n;i++){
if(!dfn[i]) tarjan(i,0);
}
for(int i = 1;i <= n;i++){
if(!st[i]) {
cnt++;
v[cnt] = {i};
dfs(i);
}
}
cout << cnt << endl;
for(int i = 1;i <= cnt;i++){
printf("%d ",v[i].size());
for(auto x:v[i]){
printf("%d ",x);
}
printf("\n");
}
}
点双连通分量
不存在割点
一张无向图是点双连通图,当且仅当满足下列两个条件之一:
- 图的顶点数不超过 2。
- 图中任意两点都同时包含在至少一个简单环中。其中“简单环”指的是不自交的环,也就是我们通常画出的环。
//【模板】点双连通分量 https://www.luogu.com.cn/problem/P8435
#include <iostream>
#include <cstring>
#include <vector>
#include <stack>
using namespace std;
const int N = 500005,M = 4000006;
int n,m;
int h[N],e[M],ne[M],idx;
int dfn[N],low[N],dn,root;
bool cut[N];
stack<int>sk;
vector<int>v[N];
int cnt;
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a]= idx++;
}
void tarjan(int x){
dfn[x] = low[x] = ++dn;
sk.emplace(x);
if(x == root && h[x] == -1) {//处理孤立点
v[++cnt].emplace_back(x);
return;
}
int son = 0;
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(!dfn[y]){
tarjan(y);
son++;
low[x] = min(low[x],low[y]);
if(dfn[x] <= low[y]){
if(x != root || son >= 2) cut[x] = 1;
v[++cnt].emplace_back(x);
v[cnt].emplace_back(y);
while(sk.top() != y){
v[cnt].emplace_back(sk.top());
sk.pop();
}
sk.pop();
}
}
else low[x] = min(low[x],dfn[y]);
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
for(int i = 1;i <= m;i++){
int a,b;scanf("%d %d",&a,&b);
if(a == b) continue;
add(a,b);add(b,a);
}
for(int i = 1;i <= n;i++){
if(!dfn[i]) root = i,tarjan(i);
}
cout << cnt << endl;
for(int i = 1;i <= cnt;i++){
printf("%d ",v[i].size());
for(auto x:v[i]){
printf("%d ",x);
}
printf("\n");
}
}
强连通分量
有向图强连通分量的Tarjan算法 (byvoid.com)
给点一张有向图,诺对于图中任意两个节点相互可达,则称该有向图是“强连通图” 有向图的极大强连通子图被称为“强连通分量”,简记为SCC。
一个环一定是强连通图。Tarjan算法基本思路就是对于每个点,尽可能找到与它一起能构成环的所有节点。每个强连通分量为搜索树中的一棵子树。搜索时,把当前搜索树中未处理的节点加入一个栈,回溯时可以判断栈顶到栈中的节点是否为一个强连通分量
//B3609 [图论与代数结构 701] 强连通分量 https://www.luogu.com.cn/problem/B3609
#include <iostream>
#include <algorithm>
#include <cstring>
#include <stack>
#include <vector>
using namespace std;
const int N = 10004,M = 200005;
int n,m;
int h[N],e[M],ne[M],idx;
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
vector<int>v[N];//第i个强连通分量包含的节点
int dfn[N],low[N],dn;
int id[N],idn;//节点i所在强连通分量scc
stack<int>sk;
void tarjan(int x){
dfn[x] = low[x] = ++dn;
sk.push(x);
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(!dfn[y]){//如果y未被搜索过,递归搜索y
tarjan(y);
low[x] = min(low[x],low[y]);
}
else if(!id[y]){//如果y被搜索过,且不属于任何一个强连通分量(则y在栈中),用dfn[y]更新low[x]
low[x] = min(low[x],dfn[y]);
}
}
if(dfn[x] == low[x]){
id[x] = ++idn;
v[idn].emplace_back(x);
while(sk.top() != x){
id[sk.top()] = idn;
v[idn].emplace_back(sk.top());
sk.pop();
}
sk.pop();
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
for(int i = 1;i <= m;i++){
int a,b;cin >> a >> b;
add(a,b);
}
for(int i = 1;i <= n;i++){
if(!dfn[i]) tarjan(i);
}
for(int i = 1;i <= idn;i++) sort(v[i].begin(),v[i].end());
cout << idn << '\n';
vector<int>st(n+1);
for(int i = 1;i <= n;i++){
if(st[i]) continue;
for(auto x:v[id[i]]){
cout << x << ' ';
st[x] = 1;
}
cout << '\n';
}
}
常应用缩点消除环的影响,转化为DAG图解决
在缩点后的DAG中,强连通分量的标号顺序是其拓扑序的逆序,出度为0的点标号标号越小,即反图的拓扑序。
2-SAT
有N个变量,每个变量只有两种可能得取值。再给点M个条件,每个条件都是对两个变量的取值限制。求是否存在对N个变量的合法赋值,使得M个条件均得到满足。
设一个变量$A_i$的两种取值分别是$A_{i,0}$和$A_{i,1}$ 。每个条件可以转化为统一的形式: “诺$A_i$的赋值为$A_{i,p}$,则$A_j$的赋值必须为$A_{j,q}$”,其中$p,q\in{0,1}$。
2-SAT问题的判断方法如下(时间复杂度O(N+M)):
-
建立2N个节点的有向图,每个变量$A_i$对应两个节点
i和i+n。 - 考虑每个条件,形如“诺$A_i$的赋值为$A_{i,p}$,则$A_j$的赋值必须为$A_{j,q}$”,$p,q\in{0,1}$,从
i+p*n到j+q*n连一条有向边。 注意上述条件蕴含着它的逆否命题“诺$A_j$的赋值为$A_{j,1-q}$,则$A_i$的赋值必须为$A_{i,1-p}$”。如果在给点的M个限制条件中,原命题和逆否命题不一定成对出现,应该从j+(1-q)*n到i+(1-p)*n也连一条有向边。 - 用Tarjan算法求出有向图中所有的强连通分量。
- 诺存在$i\in [1,n]$满足
i和i+n属于同一个强连通分量,则出现了矛盾:诺变量$A_i$赋值为$A_{i,p}$,则变量$A_i$必须赋值为$A_{i,1-p}$,说明问题无解。 - 诺问题还要求具体解,Tarjan后同一元素拆点强连通分量编号小的点即为合法点,如果一个元素拆成的两个点之间没有任何路径相连,即使是有向路径,那么这两点都可以成为合法点,这两点的分量编号不同,选小的即可
P4782 【模板】2-SAT - 洛谷 (luogu.com.cn)
N个变量,M个条件:$「x_i 为 a 或 x_j 为 b」(a,b∈{0,1})$ 条件可转化为 $诺x_i为1-a则x_j必为b$ , $诺x_j为1-b则x_i必为a$。以此建边
#include <iostream>
#include <cstring>
#include <stack>
using namespace std;
const int N = 2000006;
int n,m;
int h[N],e[N],ne[N],idx;
int dfn[N],low[N],dn;
int id[N],idn;
stack<int>sk;
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void tarjan(int x){
dfn[x] = low[x] = ++dn;
sk.push(x);
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(!dfn[y]) {
tarjan(y);
low[x] = min(low[x],low[y]);
}
else if(!id[y]) low[x] = min(low[x],dfn[y]);
}
if(low[x] == dfn[x]){
++idn;
id[x] = idn;
while(sk.top() != x){
id[sk.top()] = idn;
sk.pop();
}
sk.pop();
}
}
int main(){
memset(h,-1,sizeof h);
scanf("%d %d",&n,&m);
while(m--){
int a,x,b,y;scanf("%d %d %d %d",&a,&x,&b,&y);
if(x == 0 && y == 0){
add(a+n,b);
add(b+n,a);
}
if(x == 0 && y == 1){
add(a+n,b+n);
add(b,a);
}
if(x == 1 && y == 0){
add(a,b);
add(b+n,a+n);
}
if(x == 1 && y == 1){
add(a,b+n);
add(b,a+n);
}
}
for(int i = 1;i <= n << 1;i++){//2n层循环
if(!dfn[i]) tarjan(i);
}
for(int i = 1;i <= n;i++){
if(id[i] == id[i+n]) {//属于同一个强连通分量,无解
cout << "IMPOSSIBLE";
return 0;
}
}
cout << "POSSIBLE\n";
for(int i = 1;i <= n;i++){//这里a[i]为0,a[i+n]为1,选所在强连通分量小的为合法解
cout << (id[i] > id[i+n]) << ' ';
}
}
P10969 Katu Puzzle - 洛谷 (luogu.com.cn)
网络流
一个网络G=(V,E),是一张有向图,图中每条边 $(x,y)\in E$ 都有一个给定的权值c(x,y) ,称为边的容量,特别的诺$(x,y)\notin E$,则c(x,y) = 0 。图中还有两个指定的特殊节点 源点S 和 汇点T (S != T)。
设f(x,y) 是定义在节点二元组$(x\in V,y \in V)$三的实数函数,且满足:
- 容量限制:
f(x,y) <= c(x,y) - 斜对称:
f(x,y) = -f(y,x) - 流量守恒:c
f()称为网络的流量函数,对于$(x,y)\in E$,f(x,y)称为边的流量,c(x,y) - f(x,y)称为边的剩余容量
$\sum_{(S,v)\in E} f(S,v)$,为整个网络的流量(其中S表示源点)
最大流
对于一个给定的网络,合法流函数f()有很多。其中使得整个网络的流量最大的流函数被称为网络的最大流。
建边时反边容量全为0
Edmondsd-Karp
时间复杂度$O(NM^2)$,实际效率较高,一般能处理10^3 ~ 10^4 规模的网络
每次bfs遍历整个残量网络,找出任意一条增广路,同时计算路径上各边剩余流量的最小值minf,显然可以让一股流沿着增广路从S流向T,网络的流量就可以增加minf。直到网络上不存在增广路为止。
//模版 https://www.luogu.com.cn/problem/P3376
#include <iostream>
#include <queue>
#include <cstring>
using namespace std;
const int N = 205,M = 10004;
const int INF = 0x3f3f3f3f;
int n,m,s,t;
long long maxflow;
int h[N],e[M],ne[M],idx;
long long w[M];//容量
long long rest[N];//记录各边剩余容量的最小值
int pre[M];//记录点x是从哪条边过来的
bool vis[N];
void add(int x,int y,int z){
w[idx] = z,e[idx] = y,ne[idx] = h[x],h[x] = idx++;
}
bool bfs(){
memset(vis,0,sizeof vis);
queue<int>q;
q.push(s);
vis[s] = 1;
rest[s] = INF;
while(q.size()){
int x = q.front();
q.pop();
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(vis[y] || w[i] == 0) continue;
rest[y] = min(rest[x],w[i]);
pre[y] = i;
q.push(y);
vis[y] = 1;
if(y == t) return 1;
}
}
return 0;
}
int update(){//将流过的路径容量减少minf,反边增加minf
int x = t;
while(x != s){
int i = pre[x];
w[i] -= rest[t];
w[i^1] += rest[t];
x = e[i^1];
}
return rest[t];//网络的流量可以增加最小值minf
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m >> s >> t;
for(int i = 1;i <= m;i++){
int x,y,z;cin >> x >> y >> z;
add(x,y,z);add(y,x,0);
}
while(bfs()) maxflow += update();
cout << maxflow;
}
Dinic
时间复杂度$O(N^2M)$,实际效率较高,能处理 10^4~10^5 规模的网络。特别地,在求解二分图最大匹配时间复杂度为$O(M \sqrt{N})$,边权设为1,源点向A集合连边,B集合向汇点连边。
EK算法每次只找出一条增广路,而Dinic可以一次找出多条。
- 在[残量网络]上bfs求出节点的层次,构造[分层图]。
- 在分层图上dfs寻找增广路,回溯时更新边权。
#include <iostream>
#include <queue>
#include <cstring>
using namespace std;
const int INF = 0x3f3f3f3f;
const int N = 205,M = 10004;
int n,m,s,t;
long long maxflow;
int h[N],e[M],ne[M],w[M],idx;
int d[N];
int now[N];//当前弧优化
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
bool bfs(){//在残量网络上构造分层图
memset(d,0,sizeof d);
queue<int>q;
q.push(s);
d[s] = 1;
now[s] = h[s];
while(q.size()){
int x = q.front();
q.pop();
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(!w[i] || d[y]) continue;
d[y] = d[x] + 1;
now[y] = h[y];
q.push(y);
if(y == t) return 1;
}
}
return 0;
}
int dfs(int x,int flow){//flow表示经过该点的剩余流量
if(x == t) return flow;
int res = 0;//res表示经过该点的所有流量和
for(int i = now[x];~i && flow;i = ne[i]){//只有当前还有流时才继续搜索
now[x] = i;//当前弧优化
int y = e[i];
if(!w[i] || d[y] != d[x] + 1) continue;
int k = dfs(y,min(flow,w[i]));
if(k == 0) d[y] = 0;//剪枝,去掉增广完毕的点
w[i] -= k;
w[i^1] += k;
res += k;
flow -= k;
}
return res;
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m >> s >> t;
for(int i = 1;i <= m;i++){
int a,b,c;cin >> a >> b >> c;
add(a,b,c);add(b,a,0);
}
while(bfs()) maxflow += dfs(s,INF);
cout << maxflow;
}
最小割
诺删除一个边集$E\prime \in E$后,S与T将不再连通, 则$E\prime$为该网络的一个割。容量之和最小的割称为网络的最小割。
最大流最小割定理:任何一个网络的最大流量等于最小割中边的容量之和,即“最大流=最小割”
求具体方案
在求完最大流后,从源点S出发,BFS遍历残量网络中还能到达的点,这些点属于S集合,剩下无法到达的点属于T集合。所有连接S和T的边即为属于最小割的边。
bool st[N] = {};//st[x]=1则属于S,否则属于T
void uuz(){
queue<int>q;
q.push(s);
st[s] = 1;
while(q.size()){
int x = q.front();
q.pop();
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(!st[y] && w[i]){
q.push(y);
st[y] = 1;
}
}
}
for(int i = 0;i < idx;i += 2){
int x = e[i^1],y = e[i];
if(st[x] && !st[y]){//此时w[i] == 0
cout << x << ' ' << y << endl;//边(x,y)属于最小割
}
}
}
求割边数量
如果要在最小割的前提下最小化个边数量,那么先求出最小割,然后把没有满流的边容量改为INF,满流的边容量改为1,再跑一边最小割就可以求出最小割边数量; 如果没有最小割的前提,直接把所有边的容量设为1,求一遍最小割即可。
常见问题模型
有n个物品和两个集合A,B,每个物品必须且只能放入一个集合里,如果一个物品没有放入A集合会花费$a_i$,如果没有放入B集合会花费$b_i$,还有诺干个条件如$(u_i,v_i,w_i)$表示如果$u_i$和$v_i$不在同一个集合里会花费$w_i$,求最小代价。
这是一个经典的二者选一的最小割题目。我们设立一个超级源点s和超级汇点t,对每个点i连边add(s,i,a[i])和add(i,t,b[i]),反边容量均为0。对每个限制条件连双向边add(u,v,w),add(v,u,w)。
注意到,但源点和汇点不相连时,代表这些点都选择了一个其中集合,最小割就是最小花费。如果要求最大花费,将所有花费减去最小割即可。
例题:P1361 小M的作物 - 洛谷 (luogu.com.cn)
最大权闭合图
给定一张有向图,每个点都有一个权值a[i](可能 <= 0),你需要选择权值和最大的一组点集,满足:每个点的后继节点都必须包含在点集中。
结论:建立超级源点s和超级汇点t,诺节点u权值为正,则连边(s,u,a[i]);诺节点u权值为负,则连边(u,t,-a[i]);权值为0不用连,原图上所有边权改为$\infin$。所有反边边权全为0,跑最大流,答案即为所有正权点之和减去最小割。
例题:Get More Money(★7) - AtCoder typical90_an - Virtual Judge (vjudge.net)
也可用于处理不连通的有向森林
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int INF = 0x3f3f3f3f;
const int N = 105,M = N*N;
int n,m;
int h[N],e[M],ne[M],idx,w[M];
int a[N];
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
s = 0,t = n+1;
for(int i = 1;i <= n;i++){
cin >> a[i];
a[i] -= m;
if(a[i] > 0){
ans += a[i];
add(s,i,a[i]);
add(i,s,0);
}
if(a[i] < 0){
add(i,t,-a[i]);
add(t,i,0);
}
}
for(int i = 1;i <= n;i++){
int k;cin >> k;
while(k--){
int j;cin >> j;
add(j,i,INF);
add(i,j,0);
}
}
while(bfs()) maxflow += dfs(s,INF);//Dinic最大流板子省略
cout << ans - maxflow;
}
费用流
给定一个网络$G=(V,E)$,每条边除了有容量限制c(x,y)外,还有一个单位流量的费用w(x,y),当(x,y)的流量为f(x,y)时,需要花费f(x,y) * w(x,y)的费用。w也满足斜对称性质,即w(x,y) = -w(y,x)。
使该网络中花费最小的最大流称为最小费用最大流。注意:费用流的前提是最大流。
SSP算法(Successive Shortest Path):每次寻找单位费用最小的增广路进行增广,直到图上不存在增广路为止。时间复杂度最坏为$O(nmf)$,其中f表示网络的最大流。实现时,只需将 EK 算法或 Dinic 算法中找增广路的过程,替换为用最短路算法寻找单位费用最小的增广路即可。需要保证网络没有负环。
P3381 【模板】最小费用最大流 - 洛谷 (luogu.com.cn)
//基于EK算法实现
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int INF = 0x3f3f3f3f;
const int N = 5003,M = 100005;
int n,m,s,t;
int maxflow,mincost;
int h[N],e[M],ne[M],w[M],c[M],idx;//w为容量,c为费用
bool vis[N];
int pre[M];
int rest[N];
int dist[N];
void add(int u,int v,int x,int y){
c[idx] = y,w[idx] = x,e[idx] = v,ne[idx] = h[u],h[u] = idx++;
}
bool spfa(){
memset(vis,0,sizeof vis);
memset(dist,0x3f,sizeof dist);
queue<int>q;
q.push(s);
vis[s] = 1;
rest[s] = INF;
dist[s] = 0;
while(q.size()){
int x = q.front();
q.pop();
vis[x] = 0;
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(w[i] && dist[y] > dist[x] + c[i]){
dist[y] = dist[x] + c[i];
rest[y] = min(rest[x],w[i]);
pre[y] = i;
if(!vis[y]){
q.push(y);
vis[y] = 1;
}
}
}
}
return dist[t] < INF;
}
void update(){
int x = t;
while(x != s){
int i = pre[x];
w[i] -= rest[t];
w[i^1] += rest[t];
x = e[i^1];
}
mincost += rest[t] * dist[t];
maxflow += rest[t];
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m >> s >> t;
for(int i = 1;i <= m;i++){
int u,v,x,y;cin >> u >> v >> x >> y;
add(u,v,x,y);add(v,u,0,-y);//费用取反
}
while(spfa()) update();
cout << maxflow << ' ' << mincost;
}
//基于Dinic算法实现
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int INF = 0x3f3f3f3f;
const int N = 5003,M = 100005;
int n,m,s,t;
int maxflow,mincost;
int h[N],e[M],ne[M],w[M],c[M],idx;
int now[N],dist[N];
bool vis[N];
void add(int a,int b,int x,int y){//w[] = x为容量,c[] = y为费用
c[idx] = y,w[idx] = x,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
bool spfa(){
memset(vis,0,sizeof vis);
memset(dist,0x3f,sizeof dist);
queue<int>q;
q.push(s);
now[s] = h[s];
dist[s] = 0;
while(q.size()){
int x = q.front();
q.pop();
vis[x] = 0;
for(int i = h[x];~i;i = ne[i]){
int y = e[i];
if(w[i] && dist[y] > dist[x] + c[i]){
dist[y] = dist[x] + c[i];
now[y] = h[y];
if(!vis[y]){
q.push(y);
vis[y] = 1;
}
}
}
}
return dist[t] < INF;
}
int dfs(int x,int flow){
if(x == t) return flow;
vis[x] = 1;//
int res = 0;
for(int i = now[x];~i && flow;i = ne[i]){
now[x] = i;
int y = e[i];
if(w[i] && dist[y] == dist[x] + c[i] && !vis[y]){
int k = dfs(y,min(w[i],flow));
if(!k) dist[y] = 0;
w[i] -= k;
w[i^1] += k;
res += k;
flow -= k;
mincost += k*c[i];//最小费用 += 当前流量*当前费用
}
}
vis[x] = 0;
return res;
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m >> s >> t;
for(int i = 1;i <= m;i++){
int a,b,x,y;cin >> a >> b >> x >> y;
add(a,b,x,y);add(b,a,0,-y);//费用取反
}
while(spfa()) maxflow += dfs(s,INF);
cout << maxflow << ' ' << mincost;
}
欧拉图
欧拉路:给定一张无向图,诺存在一条从节点S到节点T的路径,恰好不重不漏地经过每条边一次,则称该路径为S到T的欧拉路
欧拉回路:特别地,诺存在一条从节点S出发,恰好不重不漏地经过每一条边一次(可以重复经过图中的节点),最终回到起点S,则称该路径为欧拉回路。存在欧拉回路的图被称为欧拉图。
欧拉路的存在性判断:一张无向图中存在欧拉路,当且仅当无向图连通,且起点和终点的度数为奇数,其它节点的度数为偶数。
使用DFS寻找欧拉路的基本思想如下:
DFS寻找到第一个无边可走的节点,则这个节点必定为终点。
接下来由于DFS的递归回溯,会退回终点的上一个节点,继续往下搜索,直到寻找到第二个无边可走的节点,则这个节点必定为欧拉路中终点前最后访问的节点。
于是当通过DFS遍历完整张图后,就可以倒序储存下整个欧拉路。该算法时间复杂度为O(NM),因为一个节点会被遍历多次,且递归层数为O(M)级别,容易栈溢出。可以使用栈模拟递归,且每次访问一条边后删除该边(修改表头,令其指向下一条边)
//诺欧拉回路存在,则可用dfs和栈求出欧拉回路的一种具体方案
#include <iostream>
#include <cstring>
#include <stack>
#include <vector>
using namespace std;
const int N = 10004,M = 100005;
int n,m;
int h[N],e[M],ne[M],idx;
bool vis[M];
stack<int>sk;
vector<int>ans;
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void euler(){//栈模拟递归
sk.emplace(1);
while(sk.size()){
int u = sk.top();
int i = h[u];
while(~i && vis[i]) i = ne[i];//找到一条尚未访问的边
if(~i){//沿着这条边模拟递归过程,标记该边,并更新表头,避免重复检查已处理边
sk.emplace(e[i]);
vis[i] = vis[i^1] = 1;//诺将该行注释掉,则为每条边正反恰好各走一次的答案[Luogu_P6066]
h[u] = ne[i];
}
else{//u相连的所有边均已访问,模拟回溯过程,记录答案
sk.pop();
ans.emplace_back(u);
}
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
for(int i = 1;i <= m;i++){
int a,b;cin >> a >> b;
add(a,b);add(b,a);
}
euler();//这里假设1为起点
for(int i = ans.size()-1;i >= 0;i--){
cout << ans[i] << '\n';
}
}
动态规划
「笔记」DP从入土到入门 - Luckyblock - 博客园 (cnblogs.com)
【题单】动态规划(入门/背包/状态机/划分/区间/状压/数位/树形/数据结构优化) - 力扣(LeetCode)
- 构造问题
- 拆解子问题
- 求解最简单子问题
- 通过子问题推当前问题,构建状态转移方程
- 判断复杂度
memset()初始化
dp[0][0][...] = 边界值
for(状态1 :所有状态1的值){
for(状态2 :所有状态2的值){
for(...){
//状态转移方程
dp[状态1][状态2][...] = 求max/min/sum...
}
}
}
背包问题
01背包
每个物品最多只能用一次
//一维优化
//dp[j] = max(dp[k], dp[k - v[i]] + w[i]);
//1. dp[i] 仅用到了dp[i-1]层,
//2. k与k-v[i] 均小于k
//3.若用到上一层的状态时,从大到小枚举, 反之从小到大哦
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1003;
int n, m;
int v[N], w[N];
int dp[N];//dp[i]表示背包容量不超过i下的最大价值
int main() {
cin >> n >> m;
for (int i = 0; i < n;i++) {
cin >> v[i] >> w[i];
}
for (int i = 0; i < n;i++) {//枚举所有物品
for (int k = m; k >= v[i];k--) {//k从m~v[i]能枚举所有体积
dp[k] = max(dp[k], dp[k - v[i]] + w[i]);
}
}
cout << dp[m];
return 0;
}
//二维未优化版
int dp[N][N];//dp[i][j]表示前i个物品,总体积不超过j的最大价值
for(int i = 1;i <= n;i++){
for(int j = 1;j <= m;j++){
if(j-v[i] >= 0) dp[i][j] = max(dp[i-1][j],dp[i-1][j-v[i]]+w[i]);
else dp[i][j] = dp[i-1][j];
}
}
完全背包
每个物品可以使用无数次
//https://www.acwing.com/problem/content/3/
//未优化版 时间复杂度较高 最大为O(nmk)
//f[i][j] = max(f[i][j], f[i - 1][j - k * v[i]] + k * w[i]);
//二维优化 (i:1~n) (j:0~m)
if (j >= v[i]) f[i][j] = max(f[i - 1][j], f[i][j - v[i]] + w[i]);
else f[i][j] = f[i - 1][j];
//一维优化 O(NM)
#include <iostream>
using namespace std;
const int N = 1003;
int n,m;
int w[N],v[N],dp[N];
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++){
cin >> v[i] >> w[i];
}
for(int i = 1;i <= n;i++){
for(int k = v[i];k <= m;k++){//一维完全背包这里k从小到大枚举
dp[k] = max(dp[k],dp[k-v[i]]+w[i]);
}
}
cout << dp[m] << endl;
return 0;
}
多重背包
每个物品使用有限次
//https://www.acwing.com/problem/content/4/
//二维未优化 O(nms)
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 103;
int n, m;
int v[N], w[N], s[N];
int f[N][N];
int main() {
cin >> n >> m;
for (int i = 1; i <= n;i++) {
cin >> v[i] >> w[i] >> s[i];
}
for (int i = 1; i <= n;i++) {
for (int j = 0; j <= m;j++) {//j:0~m
for (int k = 0; k <= s[i] && k * v[i] <= j;k++) {//k*v[i] <= j
f[i][j] = max(f[i][j], f[i - 1][j - k * v[i]] + k * w[i]);//
}
}
}
cout << f[n][m];
return 0;
}
//https://www.acwing.com/problem/content/5/
//二进制优化 O(nmlogs) 再用01背包问题求解
//任意一个正整数s都可拆成1+2+4+8+16+... = s
#include <iostream>
using namespace std;
const int N = 200005;
int n,m;
int v[N],w[N],dp[N],idx;
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++){
int a,b,s;cin >> a >> b >> s;
int k = 1;
while(k <= s){
idx++;//第cnt个物品体积为a*s,价值为b*s
v[idx] = a*k;
w[idx] = b*k;
s-=k;
k*=2;
}
if(s > 0){//补上剩下的s个物品
idx++;
v[idx] = a*s;
w[idx] = b*s;
}
}
for(int i = 1;i <= idx;i++){//再用01背包处理该idx个物品
for(int k = m;k >= v[i];k--){
dp[k] = max(dp[k],dp[k-v[i]]+w[i]);
}
}
cout << dp[m];
}
//////////////////////////////////////////////////////
//简写,优化空间
#include <iostream>
using namespace std;
const int N = 2003;
int dp[N];
int main(){
int n,m;cin >> n >> m;
for(int i = 1;i <= n;i++){
int v,w,s;cin >> v >> w >> s;
for(int k = 1;k <= s;k <<= 1){
s -= k;
for(int j = m;j >= k*v;j--){
dp[j] = max(dp[j],dp[j-k*v]+k*w);
}
}
if(s){
for(int j = m;j >= s*v;j--){
dp[j] = max(dp[j],dp[j-s*v]+s*w);
}
}
}
cout << dp[m];
}
//单调队列优化 O(nm)
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1003,M = 20004;
int n,m;
int v[N],w[N],s[N];
int dp[M],g[M];//对于第i层只用到第i-1层,可用拷贝/滚动数组优化
int q[M],hh,tt = -1;//单调队列滑动窗口
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++){
cin >> v[i] >> w[i] >> s[i];
}
for(int i = 1;i <= n;i++){
memcpy(g,dp,sizeof g);//g[]作为dp[]的i-1层
int k = (s[i]+1)*v[i];//(s[i]+1)*v[i]为窗口最大长度,诺超出则窗口右移
for(int r = 0;r < v[i];r++){//r为m%v[i]的偏移量
hh = 0,tt = -1;//L(hh),R(tt)
for(int j = r;j <= m;j += v[i]){
if(hh <= tt && j-k >= q[hh]) hh++;
while(hh <= tt && g[q[tt]]+(j-q[tt])/v[i]*w[i] <= g[j]) tt--;
//把以队尾q[tt]为值时<=g[j]的数都弹出,保持队列单调递减
q[++tt] = j; //队首q[hh]为滑动窗口最大值
dp[j] = g[q[hh]] + (j-q[hh])/v[i]*w[i];
//dp[i][j] = dp[i-1][mx] + (j-mx)/v[i]*w[i];
}
}
}
cout << dp[m];
}
分组背包
每组有若干个物品,同一组内的物品最多只能选一个。
//https://www.acwing.com/problem/content/description/9/
#include <iostream>
using namespace std;
const int N = 105;
int n, m;
int dp[N];//只从前i组物品中选,当前体积小于等于j的最大值
int v[N][N], w[N][N], s[N];
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i++) {
cin >> s[i];//每组s[i]个物品
for (int j = 1; j <= s[i]; j++) {
cin >> v[i][j] >> w[i][j];
}
}
for (int i = 1; i <= n; i++) {//枚举所有背包
for (int k = m; k >= 0; k--) {//从m~0枚举所有体积
for (int j = 0; j <= s[i]; j++) {//枚举所有选择
if (k >= v[i][j]) {
dp[k] = max(dp[k]/*不选*/, dp[k - v[i][j]] + w[i][j]/*选*/);
}
}
}
}
cout << dp[m];
}
二维费用背包
//二维费用01背包 https://www.acwing.com/problem/content/8/
//容量不超过V,重量不超过M
#include <iostream>
using namespace std;
const int MX = 1003;
int N,V,M;
int v[MX],m[MX],w[MX];
int dp[105][105];
int main(){
cin >> N >> V >> M;
for(int i = 1;i <= N;i++){
cin >> v[i] >> m[i] >> w[i];
}
for(int i = 1;i <= N;i++){
for(int j = V;j >= v[i];j--){
for(int k = M;k >= m[i];k--){
dp[j][k] = max(dp[j][k],dp[j-v[i]][k-m[i]] + w[i]);
}
}
}
cout << dp[V][M];
}
//潜水员 http://ybt.ssoier.cn:8088/problem_show.php?pid=1271
//01背包,求满足氧气>=A,氮气>=B的同时,最小重量和
#include <iostream>
#include <cstring>
using namespace std;
int A,B,n;
int dp[25][80];
int main(){
memset(dp,0x3f,sizeof dp);
dp[0][0] = 0;
cin >> A >> B >> n;
for(int i = 1;i <= n;i++){
int a,b,w;cin >> a >> b >> w;
for(int j = A;j >= 0;j--){
for(int k = B;k >= 0;k--){
dp[j][k] = min(dp[j][k],dp[max(j-a,0)][max(k-b,0)]+w);
}
}
}
cout << dp[A][B];
}
//空间未优化版 dp[i][j][k] = min(dp[i-1][j][k],dp[i-1][max(j-a,0)][max(k-b,0)]+w);
求具体方案
求具体方案,空间一般不能优化成二维
//01背包 https://www.acwing.com/problem/content/12/
#include <iostream>
using namespace std;
const int N = 1003;
int n,m;
int v[N],w[N];
int dp[N][N];
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++){
cin >> v[i] >> w[i];
}
for(int i = n;i >= 1;i--){
for(int j = 0;j <= m;j++){
dp[i][j] = dp[i+1][j];
if(j >= v[i]) dp[i][j] = max(dp[i+1][j],dp[i+1][j-v[i]]+w[i]);
}
}
//dp[1][m]为终点状态
for(int i = 1,j = m;i <= n;i++){
if(j >= v[i] && dp[i][j] == dp[i+1][j-v[i]]+w[i]){
cout << i << ' ';//字典序最小的方案,从前往后推
j -= v[i];
}
}
}
//分组背包 机器分配:https://www.acwing.com/problem/content/1015/
#include <iostream>
using namespace std;
const int N = 20;
int n,m;
int w[N][N];
int dp[N][N];
int ans[N];
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++){
for(int j = 1;j <= m;j++){
cin >> w[i][j];
}
}
for(int i = 1;i <= n;i++){
for(int k = 0;k <= m;k++){
for(int j = 0;j <= m;j++){
if(k >= j){
dp[i][k] = max(dp[i][k],dp[i-1][k-j]+w[i][j]);
}
}
}
}
cout << dp[n][m] << '\n';
for(int i = n,k = m;i >= 1;i--){
for(int j = 1;j <= m;j++){
if(k >= j && dp[i][k] == dp[i-1][k-j]+w[i][j]){
k -= j;
ans[i] = j;
break;
}
}
}
for(int i = 1;i <= n;i++){//第i组里选第ans[i]个物品(可能为0)
cout << i << ' ' << ans[i] << '\n';
}
}
求方案数
//01背包求最优选的方案数 https://www.acwing.com/problem/content/11/
//使总价值最大的最优方案数 O(nm)
#include <iostream>
using namespace std;
const int N = 1003,mod = 1e9+7;
int n,m;
int v[N],w[N];
int dp[N],f[N];
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++){
cin >> v[i] >> w[i];
}
for(int i = 0;i <= m;i++) {//什么都不选也是一种方案
f[i] = 1;
}
for(int i = 1;i <= n;i++){
for(int j = m;j >= v[i];j--){
if(dp[j] < dp[j-v[i]]+w[i]){
dp[j] = dp[j-v[i]]+w[i];
f[j] = f[j-v[i]];
}
else if(dp[j] == dp[j-v[i]]+w[i]){
f[j] = (f[j]+f[j-v[i]])%mod;
}
}
}
cout << f[m];
}
//01背包求价值恰好为m的方案数 https://www.acwing.com/problem/content/description/280/
//O(nm)
#include <iostream>
using namespace std;
const int N = 105,M = 10004;
int n,m;
int a[N];
int dp[M];
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++){
cin >> a[i];
}
dp[0] = 1;
for(int i = 1;i <= n;i++){
for(int j = m;j >= a[i];j--){
dp[j] += dp[j-a[i]];
}
}
cout << dp[m];
}
//完全背包求最优选的方案数(待验证) O(nm)
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1003,mod = 1e9+7;
int n,m;
int v[N],w[N];
int dp[N],f[N];
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++){
cin >> v[i] >> w[i];
}
for(int i = 0;i <= m;i++){
f[i] = 1;
}
for(int i = 1;i <= n;i++){
for(int j = v[i];j <= m;j++){
if(dp[j] < dp[j-v[i]]+w[i]){
dp[j] = dp[j-v[i]]+w[i];
f[j] = f[j-v[i]];
}
else if(dp[j] == dp[j-v[i]]+w[i]){
f[j] = (f[j]+f[j-v[i]])%mod;
}
}
}
cout << f[m];
}
//完全背包求价值恰好为m的方案数 https://www.acwing.com/problem/content/1023/
// 给你一个n种面值的货币系统,求组成面值为m的货币有多少种方案。 O(nm)
#include <iostream>
using namespace std;
const int N = 20,M = 3003;
int n,m;
int a[N];
long long dp[M];
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++){
cin >> a[i];
}
dp[0] = 1;
for(int i = 1;i <= n;i++){
for(int j = a[i];j <= m;j++){
dp[j] += dp[j-a[i]];
}
}
cout << dp[m];
}
有依赖的背包问题
有 N 个物品和一个容量是 V 的背包。物品之间具有依赖关系,且依赖关系组成一棵树的形状。如果选择一个物品,则必须选择它的父节点。
//树上分组背包 dp与类似于洛谷P2014选课
#include <iostream>
#include <cstring>
using namespace std;
const int N = 105;
int n,m;
int v[N],w[N],p[N];
int h[N],e[N],ne[N],idx;
int dp[N][N];
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dfs(int u){
for(int i = h[u];~i;i = ne[i]){//物品组
dfs(e[i]);
for(int j = m;j >= 0;j--){//体积
for(int k = 0;k <= j-v[u];k++){//决策
dp[u][j] = max(dp[u][j],dp[u][j-k]+dp[e[i]][k]);
}
}
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
int root;
for(int i = 1;i <= n;i++){
cin >> v[i] >> w[i] >> p[i];
for(int j = v[i];j <= m;j++) dp[i][j] = w[i];//初始状态
if(p[i] == -1) root = i;
else add(p[i],i);
}
dfs(root);
cout << dp[root][m];
}
线性DP
数字三角形
//https://www.acwing.com/problem/content/900/
#include <iostream>
using namespace std;
const int INF = 0x3f3f3f3f;
const int N = 505;
int arr[N][N],dp[N][N];
int n;
int main() {
cin >> n;
for (int i = 1; i <= n;i++) {
for (int j = 1; j <= i;j++) {
cin >> arr[i][j];
}
}
for (int i = 0; i <= n;i++) {//初始化多一层
for (int j = 0; j <= i + 1;j++) {
dp[i][j] = -INF;
}
}
dp[1][1] = arr[1][1];
for (int i = 2; i <= n;i++) {
for (int j = 1; j <= i;j++) {
dp[i][j] = arr[i][j] + max(dp[i-1][j-1], dp[i-1][j]);
}
}
int ans = -INF;
for (int i = 1; i <= n;i++) {//寻找最后一层的最大值
ans = max(ans, dp[n][i]);
}
cout << ans;
}
//方格取数:https://www.luogu.com.cn/problem/P1004
//左上到右下走两次
#include <iostream>
using namespace std;
const int N = 12;
int n;
int arr[N][N];
int dp[N+N][N][N];//dp[k][i1][i2]:k = i1+j1 = i2+j2
//从(1,1)走到(i1,j2)和(i2,j2)能得到的最大数
int main(){
cin >> n;
int a,b,c;
while(cin >> a >> b >> c,a&&b&&c){
arr[a][b] = c;
}
for(int k = 2;k <= n+n;k++){
for(int i1 = 1;i1 <= n;i1++){
for(int i2 = 1;i2 <= n;i2++){
int j1 = k-i1,j2 = k-i2;
if(j1 >= 1 && j1 <= n && j2 >= 1 && j2 <= n){
int t = arr[i1][j1];
if(i1 != i2) t += arr[i2][j2];//i1 != i2 说明当前不在同一个格子
int &x = dp[k][i1][i2];
//所有从上个状态转移过来的最大值
x = max(x,dp[k-1][i1-1][i2-1]+t);
x = max(x,dp[k-1][i1-1][i2] + t);
x = max(x,dp[k-1][i1][i2-1] + t);
x = max(x,dp[k-1][i1][i2] + t);
}
}
}
}
cout << dp[n+n][n][n];
}
最长上升子序列
LIS Longest Increasing Subsequence,最长递增子序列
//https://www.luogu.com.cn/problem/B3637
//O(n^2) -- DP
#include <iostream>
using namespace std;
const int N = 5005;
int n,ans;
int arr[N],dp[N];//dp[i]为以第i个点的a[i]结尾的最大的上升序列
int main() {
cin >> n;
for (int i = 1; i <= n;i++) {
cin >> arr[i];
}
for (int i = 1; i <= n; i++) {
dp[i] = 1;//初始化dp[i] = 1;
for (int j = 1; j < i;j++) {
if (arr[i] > arr[j]) {
dp[i] = max(dp[i], dp[j] + 1);
//前一个小于自己的数结尾的最大上升子序列加上自己,即+1
}
}
ans = max(ans, dp[i]);
}
cout << ans;
}
//https://www.acwing.com/problem/content/898/
//O(nlogn) -- 模拟栈 + 二分
//诺求最长单调非递减子序列 lb改为ub,>改>=即可:https://ac.nowcoder.com/acm/contest/83252/D
#include <iostream>
#include <vector>
using namespace std;
const int N = 100005;
int n,arr[N];
vector<int>v;//模拟堆栈
int main() {
cin >> n;
for (int i = 1; i <= n;i++) {
cin >> arr[i];
}
for (int i = 1; i <= n;i++) {
if (v.empty()||arr[i] > v.back()) { //如果arr[i]大于栈顶元素,将该元素入栈
v.push_back(arr[i]);
}
else {//否则替换掉第栈中一个大于或者等于arr[i]的那个数
*lower_bound(begin(v), end(v), arr[i]) = arr[i];
}
}
cout << v.size();
}
最长公共子序列
LCS Longest Common Subsequence,最长公共子序列
//https://www.acwing.com/problem/content/899/
//O(nm)
#include <iostream>
using namespace std;
const int N = 1005;
int n, m, dp[N][N];//dp[i][j]表示a的前i个字母和b的前j个字母最长公共子序列长度
string a, b;
int main() {
cin >> n >> m >> a >> b;
a = ' ' + a, b = ' ' + b;
for (int i = 1; i <= n;i++) {
for (int j = 1; j <= m;j++) {
if(a[i] == b[j]){//情况一:a[i]在b[j]在(dp[i][j])
dp[i][j] = max(dp[i][j],dp[i-1][j-1]+1);
}
else {//情况二:a[i]在b[j]不在(dp[i][j-1])、情况三:a[i]不在b[j]在(d[i-1][j])
//(情况四:a[i]不在b[j]不在(dp[i-1][j-1]),已经包含在情况二、三中
dp[i][j] = max(dp[i-1][j],dp[i][j-1]);
}
}
}
cout << dp[n][m];
/* 具体序列方案
string s;
for(int i = n,j = m;i >= 1 && j >= 1;){
if(dp[i][j] == dp[i-1][j-1]+1){
s += s1[i];
i--;j--;
}
else if(dp[i][j] == dp[i-1][j]) i--;
else if(dp[i][j] == dp[i][j-1]) j--;
}
for(int i = s.size()-1;i >= 0;i--){
cout << s[i];
}*/
}
最长公共上升子序列LCIS
//https://www.acwing.com/problem/content/274/
#include <iostream>
using namespace std;
const int N = 3003;
int n;
int a[N],b[N];
int dp[N][N];//a[]中前i个数字,b[]中前j个数字,..且当前以b[j]结尾的子序列的最长方案
int main(){
cin >> n;
for(int i = 1;i <= n;i++) cin >> a[i];
for(int i = 1;i <= n;i++) cin >> b[i];
for(int i = 1;i <= n;i++){
int nmax = 1;
for(int j = 1;j <= n;j++){
dp[i][j] = dp[i-1][j];
if(b[j] == a[i]) dp[i][j] = max(dp[i][j],nmax);
if(b[j] < a[i]) nmax = max(nmax,dp[i-1][j] + 1);
}
}
int ans = 0;
for(int i = 0;i <= n;i++){ans = max(ans,dp[n][i]);}
cout << ans;
return 0;
}
编辑距离
将字符串a通过以下操作变为字符串b的最小操作次数
- 删除一个字符
- 插入一个字符
- 修改一个字符
if (a[i] == b[j]) dp[i][j] = dp[i-1][j-1]; //无需修改 else{ dp[i][j] = min({dp[i-1][j-1]+1,dp[i-1][j]+1,dp[i][j-1]+1}); /*min{ a[1~i-1] = b[1~j-1],修改a[i]为b[j] a[1~i-1] = b[1~j],删除a[i] a[1~i] = b[1~j-1],增加b[j] }*/ }
//https://www.luogu.com.cn/problem/P2758
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 2003;
int n,m;
string a,b;
int dp[N][N];//dp[i][j]为将a[1~i]变为b[1~j]的最小操作次数
int main(){
cin >> a >> b;n = a.size();m = b.size();
a = ' ' + a,b = ' ' + b;
for(int i = 1;i <= n;i++) dp[i][0] = i;//初始化
for(int j = 1;j <= m;j++) dp[0][j] = j;
for(int i = 1;i <= n;i++){
for(int j = 1;j <= m;j++){
if(a[i] == b[j]){
dp[i][j] = dp[i-1][j-1];
}
else{
dp[i][j] = min({dp[i-1][j-1]+1,dp[i-1][j]+1,dp[i][j-1]+1});
}
}
}
cout << dp[n][m];
}
区间DP
定义
区间类动态规划是线性动态规划的扩展,它在分阶段地划分问题时,与阶段中元素出现的顺序和由前一阶段的哪些元素合并而来有很大的关系。
令状态 $f(i,j)$ 表示将下标位置 $i$ 到 $j$ 的所有元素合并能获得的价值的最大值,那么 $f(i,j)=\max{f(i,k)+f(k+1,j)+cost}$,$cost$ 为将这两组元素合并起来的价值。
性质
区间 DP 有以下特点:
合并:即将两个或多个部分进行整合,当然也可以反过来;
特征:能将问题分解为能两两合并的形式;
求解:对整个问题设最优值,枚举合并点,将问题分解为左右两个部分,最后合并两个部分的最优值得到原问题的最优值。
一维
石子合并
n个数a[1]~a[n]排成一排,进行n-1次合并操作,每次操作将相邻的两堆合并成一堆,并获得新的一堆中的石子数量的和的得分。你需要最小化你的得分。
诺要求环形的,只需将两个a[ ]接在一起。枚举所有长度为n的区间取最值
//https://www.luogu.com.cn/problem/P1775
//O(n^3)
#include <iostream>
#include <cstring>
using namespace std;
const int N = 305;
int n;
int s[N];//a[]的前缀和
int dp[N][N];//dp[i][j]表示将i到j这一段石子合并成一堆的方案的集合,属性Min
int main() {
cin >> n;
for (int i = 1; i <= n;i++) {
cin >> s[i];
s[i] += s[i-1];
}
memset(dp,0x3f,sizeof dp);
for(int i = 1;i <= n;i++) dp[i][i] = 0;
for (int len = 2; len <= n;len++) {//枚举区间长度,可以跳过1,从2开始
for (int l = 1; l + len - 1 <= n;l++) {//枚举区间左右端点
int r = l + len - 1;
for (int k = l; k < r;k++) {// 枚举分割点,构造状态转移方程
dp[l][r] = min(dp[l][r], dp[l][k]+dp[k+1][r] + s[r]-s[l-1]);
}
}
}
cout << dp[1][n];
}
///////////////////////////////////////////////////
//记忆化搜索写法
int sol(int l,int r){
if(l >= r) return 0;
if(dp[l][r] != -1) return dp[l][r];
dp[l][r] = 0x3f3f3f3f;
for(int k = l;k <= r-1;k++){
dp[l][r] = min(dp[l][r],sol(l,k)+sol(k+1,r) + s[r]-s[l-1]);
}
return dp[l][r];
}
memset(dp,-1,sizeof dp);
cout << sol(1,n);
当n很大时,用Garsia–Wachs 算法求解
每次找到第一个a[i-1] < a[i+1]的位置,把a[i-1]和a[i]合并为now,再将now插入到从i开始左边第一个a[k] > now的a[k]后面
//https://www.luogu.com.cn/problem/P5569
//需要开启O2优化,或使用平衡树等数据结构
#include<bits/stdc++.h>
using namespace std;
const int N= 40004;
const long long INF = 1e18;
long long ans;
int main(){
int n;cin >> n;
vector<long long>v(n+2);
for(int i = 1;i <= n;i++){ cin >> v[i]; }
v[0] = v[n+1] = INF;//在两端设置哨兵
n++;
while(n-- && n >= 2){
int i,k;
for(i = 1;i <= n;i++){
if(v[i-1] < v[i+1]) break;
}
int now = v[i-1]+v[i];
ans += now;
for(k = i-1;k >= 0;k--){
if(v[k] > now) break;
}
v.erase(v.begin()+i-1);
v.erase(v.begin()+i-1);
v.insert(v.begin()+k+1,now);
}
cout << ans;
}
二维
棋盘分割
将一个 $8\times 8$ 的棋盘进行如下分割:将原棋盘割下一块矩形棋盘并使剩下部分也是矩形,再将剩下的两部分中的任意一块继续如此分割,这样割了 $(n-1)$ 次后,连同最后剩下的矩形棋盘共有 $n$ 块矩形棋盘。(每次切割都只能沿着棋盘格子的边进行)。原棋盘上每一格有一个分值,一块矩形棋盘的总分为其所含各格分值之和。现在需要把棋盘按上述规则分割成 $n$ 块矩形棋盘,并使各矩形棋盘总分的平方和最小,给定n求最小值时多少?
#include <iostream>
#include <cmath>
#include <cstring>
using namespace std;
const long long INF = 1e18;
const int N = 20,M = 10;
int n,m = 8;
long long a[M][M],s[M][M];
long long dp[M][M][M][M][N];
//dp[x1][y1][x2][y2][k]表示该矩阵且切割了k次的最小平方和
long long get(int x1,int y1,int x2,int y2){
long long sum = s[x2][y2] - s[x2][y1-1] - s[x1-1][y2] + s[x1-1][y1-1];
return sum*sum;
}
long long dfs(int x1,int y1,int x2,int y2,int k){//记忆化搜索dp
long long &now = dp[x1][y1][x2][y2][k];
if(now >= 0) return now;//如果该区间已经求过,直接返回
if(k == 1) return now = get(x1,y1,x2,y2);//k=1不分割,直接返回该区间和
now = INF;
for(int i = x1;i < x2;i++){//枚举横着分割
now = min(now,dfs(x1,y1,i,y2,k-1)+get(i+1,y1,x2,y2));//选上半段
now = min(now,dfs(i+1,y1,x2,y2,k-1)+get(x1,y1,i,y2));//选下半段
}
for(int i = y1;i < y2;i++){//枚举竖着分割
now = min(now,dfs(x1,y1,x2,i,k-1)+get(x1,i+1,x2,y2));//选左半段
now = min(now,dfs(x1,i+1,x2,y2,k-1)+get(x1,y1,x2,i));//选右半段
}
return now;
}
int main(){
cin >> n;
for(int i = 1;i <= m;i++){
for(int j = 1;j <= m;j++){
cin >> a[i][j];
s[i][j] += s[i-1][j] + s[i][j-1] - s[i-1][j-1] + a[i][j];
}
}
memset(dp,-0x3f,sizeof dp);
cout << dfs(1,1,8,8,n);
}
计数DP
整数划分
一个正整数 n 可以表示成若干个正整数之和,形如:n=n1+n2+…+nk,其中 n1≥n2≥…≥nk,k≥1。现在给定一个正整数 n(1<=n<=1000),请你求出 n共有多少种不同的划分方法。
完全背包解法:把1,2,3, … n分别看做n个物体的体积,这n个物体均无使用次数限制,问恰好能装满总体积为n的背包的总方案数
//https://www.acwing.com/problem/content/902/
//O(N^2)
#include <iostream>
using namespace std;
const int N = 1005, mod = 1e9 + 7;
int n, dp[N];
int main() {
cin >> n;
dp[0] = 1;//容量为0时,前i个物品全不选也是一种方案
for (int i = 1; i <= n;i++) {
for (int j = i; j <= n;j++) {
dp[j] = (dp[j] + dp[j - i]) % mod;
}
}
cout << dp[n];
}
另一种解法:dp[i] [j]表示为总和为i,总个数为j的方案数
#include <iostream>
using namespace std;
const int N = 1005, mod = 1e9 + 7;
int n,ans, dp[N][N];
int main() {
cin >> n;
dp[0][0] = 1;
for (int i = 1; i <= n;i++) {
for (int j = 1; j <= i;j++) {
dp[i][j] = (dp[i - 1][j - 1] + dp[i - j][j]) % mod;
}
}
for (int i = 1; i <= n;i++) {
ans = (ans + dp[n][i]) % mod;
}
cout << ans;
}
https://codeforces.com/contest/560/problem/E
给定一个H*W的棋盘,其中有n个黑格子不能走,每次只能向下或右走,问从左上走到右下角共有多少种走法? 排序后,令dp[i]表示从左上走到排序后的第i个格子且不经过其他黑格子的走法,则有: \(dp[i] = C_{x_i+y_i-2}^{x_i-1}-\sum_{j=0}^{i-1}{dp[j]*C_{x_i+y_i-x_j-y_j}^{x_i-x_j}},其中x_i>=x_j且y_i>=y_j\)
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 200005;
int h,w,n;
const int mod = 1e9+7;
long long dp[N];
struct node{
int x,y;
bool operator < (const auto&e2){
if(x != e2.x) return x < e2.x;
return y < e2.y;
}
}a[N];
long long qmi(long long a,long long b,long long p){
long long ans = 1;
while(b){
if(b&1) ans = ans*a%mod;
b >>= 1;
a = a*a%mod;
}
return ans%mod;
}
long long fact[N],infact[N];
void init(){
fact[0] = infact[0] = 1;
for(int i = 1;i < N;i++){
fact[i] = i*fact[i-1]%mod;
}
infact[N-1] = qmi(fact[N-1],mod-2,mod);
for(int i = N-2;i >= 1;i--){
infact[i] = infact[i+1]*(i+1)%mod;
}
}
long long C(int a,int b){
return fact[a]*infact[b]%mod*infact[a-b]%mod;
}
int main(){
init();
cin >> h >> w >> n;
for(int i = 1;i <= n;i++){ cin >> a[i].x >> a[i].y; }
sort(a+1,a+n+1);
a[n+1] = {h,w};
for(int i = 1;i <= n+1;i++){
auto [x,y] = a[i];
dp[i] = C(x+y-2,x-1);
for(int j = 1;j < i;j++){
if(x < a[j].x || y < a[j].y) continue;
dp[i] -= dp[j]*C(x+y - a[j].x-a[j].y,x-a[j].x)%mod;
}
dp[i] = (dp[i]%mod+mod)%mod;
}
cout << dp[n+1];
}
数位DP
求区间[l,r]中答案的个数,可以转化为求 F(r) - F(l-1),其中F(x)为区间[1,x]中答案的个数
[P2602 ZJOI2010] 数字计数 - 洛谷 (luogu.com.cn)
题目大意:给定两个正整数a,b,求在[a,b]中的所有整数中,每个数码(digit)各出现了多少次。
#include <iostream>
#include <cstring>
const int N = 13;
int nums[N],len;
long long dp[N][N];//dp[pos][sum]表示pos位置,当前已经统计了sum个目标数字的方案数
long long dfs(int pos,bool lim,bool zero,int dig,int sum){
if(!pos) return sum;
if(!lim && !zero && ~dp[pos][sum]) return dp[pos][sum];
int up = lim ? nums[pos] : 9;
long long ans = 0;
for(int i = 0;i <= up;i++){
bool count = (!(zero&(!i)) && (i == dig));//当前i==dig且不存在前导0
ans += dfs(pos-1,lim&(i==up),zero&(!i),dig,sum+count);
}
return (lim || zero) ? ans : dp[pos][sum] = ans;
}
long long f(long long x,int dig){
len = 0;
while(x) nums[++len] = x % 10, x /= 10;
return dfs(len,1,1,dig,0);
}
int main(){
long long l,r; std::cin >> l >> r;
for(int i = 0;i <= 9;i++){
std::memset(dp,-1,sizeof dp);
std::cout << f(r,i) - f(l-1,i) << ' ';
}
}
//度的数量 https://ac.nowcoder.com/acm/contest/973/A
//求给定区间[X,Y]中满足下列条件的整数个数:这个数恰好等于K个互不相等的B的整数次幂之和。
#include <iostream>
#include <vector>
using namespace std;
const int N = 35;
int k,b;
int c[N][N];
void init(){
for(int i = 0;i < N;i++){
for(int j = 0;j <= i;j++){
if(!j) c[i][j] = 1;
else c[i][j] = c[i-1][j] + c[i-1][j-1];
}
}
}
int f(int n){
if(n == 0) return 0;
vector<int>v;
while(n) v.emplace_back(n%b),n/=b;//将n转化为b进制数
for(int i = v.size()-1;i >= 0;i--){
cout << v[i];
}
cout << endl;
int ans = 0;
int last = 0;//记录前面已经占用多少位
for(int i = v.size()-1;i >= 0;i--){
int x = v[i];
if(x > 0){
if(i >= k-last) ans += c[i][k-last];//当前位(i)填0,则剩下位(0~i-1)可以任意填,共有C(i,k-last)种填法
if(x >= 2){//当前位(i)填1,则剩下位(0~i-1)可以任意填,共有C(i,k-last-1)种填法,直接break
if(i >= k-last-1 && k-last-1 >= 0) ans += c[i][k-last-1];
break;
}
else {//如果x==1,则当前位只能填1,已用位数last++,防止加上后面填的数会超过n,继续处理下一位
last++;
if(last > k) break;
}
}
if(i == 0 && last == k) ans++;//特殊处理最后一位右分支
}
return ans;
}
int main(){
init();
int l,r;cin >> l >> r >> k >> b;
cout << f(r) - f(l-1);
}
//非下降数 https://ac.nowcoder.com/acm/problem/50517
//求给定区间内有多少个非下降数
#include <iostream>
#include <vector>
using namespace std;
const int N = 15;
int dp[N][N];//dp[i][j]表示共有i位,且最高位数字是j的所有非下降数的个数
void init(){
for(int i = 1;i <= 9;i++){ dp[1][i] = 1; }
for(int i = 2;i < N;i++){
for(int j = 0;j <= 9;j++){
for(int k = j;k <= 9;k++){
dp[i][j] += dp[i-1][k];
}
}
}
}
int f(int n){
if(n == 0) return 1;
vector<int>v;
while(n) v.emplace_back(n%10),n/=10;
int ans = 0;
int last = 0;//保存前面位的最大值
for(int i = v.size()-1;i >= 0;i--){
int x = v[i];
for(int j = last;j < x;j++){//左边分支,因为要保持不降序,所以j>=last
ans += dp[i+1][j];
}
if(x < last) break;//如果上一位最大值大于x的话,不构成降序,所以右边分支结束
else last = x;
if(i == 0) ans++;//全部枚举完了,说明n本身构成一个方案
}
return ans;
}
int main(){
init();
int l,r;
while(cin >> l >> r){
cout << f(r) - f(l-1) << '\n';
}
}
记忆化搜索
建议数位DP使用记忆化搜索做,大部分情况下比递推简单一点。
//常规写法
//zero根据前导零是否会影响答案添加
//state可能需要设计多个
ll dfs(int pos,bool lim,bool zero ,int state){
if(!pos) return check(state);
if(!lim && !zero && ~dp[pos][state]) return dp[pos][state];
int up = lim ? nums[pos] : 9;
ll ans = 0;
for(int i = 0;i <= up;i++){
ans += dfs(pos-1,lim&(i==up),zero&(!i),update(state));
}
return (lim || zero) ? ans : dp[pos][state] = ans;
}
ll f(ll x){
len = 0;
while(x) nums[++len] = x % 10, x /= 10;
return dfs(len,1,1,0);
}
XHXJ’s LIS - HDU 4352 - Virtual Judge (vjudge.net)
T组询问,每次求区间[L,R]内有多少整数的最长上升子序列长度为K?
考虑到最长上升子序列值域为不会超过9,可以用一个二进制状态压缩表示当前LIS的状态。前导0不能算入LIS,所以参数要传入前导0状态。多开一维K可以节省初始化DP数组的时间
#include <iostream>
#include <cstring>
const int N = 22;
int k;
long long dp[N][1 << 10][10];//dp[pos][state][k]表示第pos位,LIS状态压缩为state,LIS为k的方案数
int nums[N],len;
int update(int state,int x,int zero){
if(zero && (!x)) return state;//前导零不计入序列
for(int i = x;i <= 9;i++){//用x替换state中第一个>=x的数
if(state >> i & 1) {
return state & (~(1 << i)) | (1 << x);
}
}
return state | 1 << x;
}
long long dfs(int pos,int state,int lim,int zero){//lim判断当前位是否有限制,zero判断是否有前导0
if(!pos) return __builtin_popcount(state) == k;//递归终点,判断LIS长度
if(~dp[pos][state][k] && !lim) return dp[pos][state][k];//记忆化结果(无限制时复用)
int up = lim ? nums[pos] : 9;//当前位上限,无限制则可任意填
long long ans = 0;
for(int i = 0;i <= up;i++){
ans += dfs(pos-1,update(state,i,zero),lim && (i == up),zero && (!i));
}
return lim ? ans : dp[pos][state][k] = ans;//无限制时结果记忆化
}
long long f(long long x){
len = 0;
while(x) nums[++len] = x % 10, x /= 10;
return dfs(len,0,1,1);
}
void sol(){
long long l,r; std::cin >> l >> r >> k;
std::cout << f(r) - f(l-1) << '\n';
}
int main(){
std::memset(dp,-1,sizeof dp);
int t; std::cin >> t;
for(int i = 1;i <= t;i++){
printf("Case #%d: ",i);
sol();
}
}
试填法
P10958 启示录 - 洛谷 (luogu.com.cn)
只要某数字的十进制表示中有三个连续的 6,即认为这是个魔鬼的数,比如 666,1666,6663,16666,6660666 等等。
给定n,求第n个魔鬼数是多少。
当然也可以使用二分+记忆化搜索:记录详情 (luogu.com.cn)
#include <iostream>
using namespace std;
const int N = 12;
int n;
int dp[N][3],g[N];//dp[i][j]表示共有i位,且有连续j(0~2)个6,g[i]表示i位共有多少个魔鬼数
void init(){
dp[0][0] = 1;
dp[0][1] = dp[0][2] = 0;
for(int i = 1; i < N;i++){
dp[i][0] = 9*(dp[i-1][0]+dp[i-1][1]+dp[i-1][2]);
dp[i][1] = dp[i-1][0];
dp[i][2] = dp[i-1][1];
g[i] = 10*g[i-1] + dp[i-1][2];
}
}
void sol(){
cin >> n;
int m = 3;
while(g[m] < n) m++;//确定位数,第n个魔鬼数有m位
for(int i = m,k = 0;i >= 1;i--){
for(int j = 0;j <= 9;j++){//当前第i位诺填j
long long cnt = g[i-1];//后面i-1位还有cnt种填法能让整个数是魔鬼数
if(j == 6 || k == 3){
//当前位i开始,左边已经有了连续k+(j==6)个6,还差3-(k+(j==6))个6
for(int l = max(3-k-(j==6),0);l <= 2;l++){
cnt += dp[i-1][l];
}
}
if(cnt >= n){
cout << j;
if(k < 3){
if(j == 6) k++;
else k = 0;
}
break;
}
else n -= cnt;
}
}
cout << '\n';
}
int main(){
init();
int t;cin >> t;
while(t--) sol();
}
状压DP
长方形摆放
求把 N×M的棋盘分割成若干个 1×2 的长方形,有多少种方案。


| 用二进制j表示第i列状态,如第1列状态为10010,第2列状态为01001,st[1 | 2] = 11011 |
//https://www.acwing.com/problem/content/description/293/
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
const int N = 12, M = 1 << N;//M = 2^N
int n, m;
bool st[M];
long long dp[N][M];//第一维表示列, 第二维表示所有可能的状态(1表示当前位置放了横着的长方形的左半边)
vector<int>v[M];//二维数组记录合法的状态
int main() {
while (cin >> n >> m, n && m) {//n行,m列
//预处理1:筛掉连续奇数个0的状态(不能竖着放满长方形)
for (int j = 0; j < (1 << n); j++) {//j < 2^n
st[j] = 1;
int cnt = 0;//cnt记录连续0的个数
for (int k = 0; k < n; k++) {
if ((j >> k) & 1) {//如果当前位为1,且前有连续奇数个0则状态不合法
if (cnt & 1)st[j] = 0;
cnt = 0;
}
else cnt++;
}
if (cnt & 1)st[j] = 0;//判断最后一节连续0个数
}
//预处理2:看第i列能使用那些状态而不会和第i-1列冲突
for (int j = 0; j < (1 << n); j++) {//枚举第i列的所有状态j
v[j].clear();//初始化清空上次操作遗留的状态,防止影响本次状态。
for (int k = 0; k < (1 << n); k++) {//枚举第i-1列的所有状态k
if ((j & k) == 0 && st[j | k]) {
//j&k按位与判断i-1列伸到i列和第i列状态是否重合冲突
//j|k按位或判断i-1列伸出去的方块是否会导致i列有连续奇数个0
v[j].emplace_back(k);
//j表示第i列的可行状态,k表示第i列状态为j的情况下第i-1列所有可行状态
}
}
}
memset(dp, 0, sizeof dp);
dp[0][0] = 1;
//第1列由虚构的第0列推导,第0列不可能放横条,只能全摆薯条,故摆法只有一种,无需考虑奇偶性
for (int i = 1; i <= m; i++) {
for (int j = 0; j < (1 << n); j++) {
for (auto& k : v[j]) {
dp[i][j] += dp[i - 1][k];
}
}
}
cout << dp[m][0] << endl;
//dp[m][0]表示 前m-1列都处理完,并且第m-1列没有伸出来的所有方案数
//既整个棋盘处理完的方案数
}
}
最短Hamilton路径
给定一张 n(n≤20) 个点的带权无向图,点从0∼n−1标号,求起点 0 到终点 n-1 的最短Hamilton路径。 Hamilton路径的定义是从 0 到 n-1 不重不漏地经过每个点恰好一次。
//https://ac.nowcoder.com/acm/problem/50909
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 21, M = 1 << N;
int n;
int a[N][N];//带权无向图
int dp[M][N];//dp[i][j],i表示当前走过的点的集合,j表示当前停在了哪个点
//i为二进制表示路径,如走0,1,2,4点则i为(10111)=23
int main() {
cin >> n;
for (int i = 0; i < n;i++) {
for (int j = 0; j < n;j++) {
cin >> a[i][j];
}
}
memset(dp, 0x3f, sizeof dp);//因为要求最小值,所以初始化为无穷大
dp[1][0] = 0;//0为起点,所以dp[1][0] = 0;
for (int i = 1; i < 1 << n;i++) {//枚举所有路径
for (int j = 0; j < n;j++) {//枚举所有终点
if (i >> j & 1) {//合法终点j
for (int k = 0; k < n;k++) {//枚举所有终点
if (i >> k & 1) {//合法终点k
dp[i][j] = min(dp[i][j], dp[i - (1 << j)][k] + a[k][j]);
//dp[i][j] 对 (dp[i中不包含点j的所有子路径][终点为k] + a[k][j]) 取最小值
}
}
}
}
}
cout << dp[(1 << n) - 1][n - 1];//[1111111...][n-1]表示所有点都走过,终点为n-1
}
bitset优化
Many Graph Queries(★7) - AtCoder typical90_bg - Virtual Judge (vjudge.net)
给定N个点,M条边的有向图。回答Q个询问:从点a能否到达点b?$N,M,Q\le 10^5$
将询问分成$\sqrt Q$组,依次处理每组询问。
#include <iostream>
#include <bitset>
#include <vector>
using namespace std;
int main(){
int n,m,q;cin >> n >> m >> q;
vector<vector<int>>e(n);
for(int i = 0;i < m;i++){
int a,b;cin >> a >> b;
a--;b--;
e[a].emplace_back(b);
}
vector<int>a(q),b(q);
for(int i = 0;i < q;i++){
cin >> a[i] >> b[i];
a[i]--;b[i]--;
}
for(int i = 0;i < q;i += 316){
vector<bitset<316>>dp(n+1);
for(int j = 0;j < 316 && i+j < q;j++){
dp[a[i+j]][j] = 1;
}
for(int x = 0;x < n;x++){
for(auto& y:e[x]){
dp[y] |= dp[x];
}
}
for(int j = 0;j < 316 && i+j < q;j++){
if(dp[b[i+j]][j]) cout << "Yes\n";
else cout << "No\n";
}
}
}
重复覆盖问题
给定n个集合,和一个目标集合,选择最少的集合,使得所选集合的并集=目标集合
时间复杂度$O(N*2^M)$,诺复杂度过高,可以考虑Dancing Links解决
//糖果 https://www.luogu.com.cn/problem/P8687
//dp[i]表示从状态0000走到状态i的最少步数
#include <iostream>
#include <cstring>
using namespace std;
const int N = 105,M = 1 << 21;
int a[N];
int dp[M];
int main(){
int n,m,k;cin >> n >> m >> k;
for(int i = 1;i <= n;i++){
for(int j = 1;j <= k;j++){
int x;cin >> x;
a[i] |= 1 << (x-1);
}
}
memset(dp,0x3f,sizeof dp);
dp[0] = 0;
for(int i = 1;i <= n;i++){
for(int j = 0;j < 1 << m;j++){
dp[a[i]|j] = min(dp[a[i]|j],dp[j]+1);//核心代码
}
}
int ans = dp[(1<<m)-1];
if(ans == 0x3f3f3f3f) cout << -1;
else cout << ans;
}
//dfs+记忆化写法 dp[i]表示从状态i走到目标状态1111的最少步数,如果dp[i]=0(且i!=n)则没有访问过该状态
//memset(dp,0,sizeof dp);
//int ans = dfs(0);
int dfs(int u){
if(u == (1 << m)-1) return 0;//目标状态
if(dp[u]) return dp[u];//诺状态u到之前达过,则直接返回
int ans = 0x3f3f3f3f;//可以用dp[u] = 0x3f3f3f3f替换;
for(int i = 1;i <= n;i++){
if((u|a[i]) == u) continue;//只有状态发生改变才转移,防止死循环
ans = min(ans,dfs(u|a[i])+1);
}
return dp[u] = ans;
}
树形DP
求解一颗有向树的最大权独立集,每条边最多选一个点
我们设 $f(i,0/1)$ 代表以 $i$ 为根的子树的最优解(第二维的值为 0 代表 $i$ 不参加舞会的情况,1 代表 $i$ 参加舞会的情况)。
对于每个状态,都存在两种决策(其中下面的 $x$ 都是 $i$ 的儿子):
- 上司不参加舞会时,下属可以参加,也可以不参加,此时有 $f(i,0) = \sum\max {f(x,1),f(x,0)}$;
- 上司参加舞会时,下属都不会参加,此时有 $f(i,1) = \sum{f(x,0)} + a_i$。
我们可以通过 DFS,在返回上一层时更新当前结点的最优解。
//https://www.luogu.com.cn/problem/P1352
#include <iostream>
#include <cstring>
using namespace std;
const int N = 6006;
int n,w[N];
int h[N], e[N], ne[N], idx;
int dp[N][2];//dp[i][0]表示i节点不参加,dp[i][1]表示i节点参加
bool st[N];//标记节点是否有父节点
void add(int a, int b) {
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
void dfs(int u) {
dp[u][1] = w[u];
for (int i = h[u]; i != -1;i = ne[i]) {
int k = e[i];
dfs(k);
dp[u][0] += max(dp[k][0], dp[k][1]);//父节点参加时子节点可参加可不参加
dp[u][1] += dp[k][0];//父节点参加时子节点都不能参加
}
}
int main() {
memset(h, -1, sizeof h);
cin >> n;
for (int i = 1; i <= n;i++) {
cin >> w[i];
}
for (int i = 1; i < n;i++) {
int a, b; cin >> a >> b;
add(b, a);
st[a] = 1;//标记a有父节点
}
int root = 1;
while (st[root]) root++;
dfs(root);//从根节点搜索
cout << max(dp[root][0], dp[root][1]);
}
每个节点至少要连接一个被选择的点,并使所有选择的点总花费最小
dp[i,0] 表示未选择当前点,且选择了其父节点。 dp[i,1] 表示未选择当前点,且选择了至少一个子节点。 dp[i,2] 表示选择了当前点。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 1505;
int n;
int h[N],e[N],ne[N],w[N],idx;
int dp[N][N];
bool st[N];
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dfs(int u){
dp[u][2] = w[u];
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
dfs(k);
dp[u][0] += min(dp[k][1],dp[k][2]);
dp[u][2] += min({dp[k][0],dp[k][1],dp[k][2]});
}
dp[u][1] = 0x3f3f3f3f;
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
dp[u][1] = min(dp[u][1],dp[u][0]+dp[k][2]-min(dp[k][1],dp[k][2]));
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n;
for(int i = 1;i <= n;i++){
int a,k;cin >> a >> w[a] >> k;
while(k--){
int b;cin >> b;
add(a,b);
st[b] = 1;
}
}
int root = 1;
while(st[root]) root++;
dfs(root);
cout << min(dp[root][1],dp[root][2]);
}
树上背包
//选课 https://www.luogu.com.cn/problem/P2014
//O(N*M^2) 有依赖关系的背包问题
//对于森林,可以将每一棵树的根节点都接到一个"虚拟根节点0"上,以0作为根节点,dp[0][m+1]即为答案
#include <iostream>
#include <cstring>
using namespace std;
const int N = 305;
int n,m;
int s[N],k[N];
int h[N],e[N],ne[N],idx;
int dp[N][N];//选到节点i,价值不超过j的最大价值
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dfs(int u){//分组背包处理
for(int i = h[u];~i;i = ne[i]){//枚举物品组
dfs(e[i]);
for(int j = m+1;j >= 0;j--){//枚举体积 j(m+1~0)
for(int k = 0;k <= j-1;k++){//枚举决策 k(0~j-v[u])
dp[u][j] = max(dp[u][j],dp[u][j-k]+dp[e[i]][k]);
}
}
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n >> m;
for(int i = 1;i <= n;i++){
cin >> k[i] >> s[i];
for(int j = 1;j <= m;j++) dp[i][j] = s[i]; //初始状态
add(k[i],i);
}
dfs(0);
cout << dp[0][m+1];
}
换根DP
树形 DP 中的换根 DP 问题又被称为二次扫描,通常不会指定根结点,并且根结点的变化会对一些值,例如子结点深度和、点权和等产生影响。
通常需要两次 DFS,第一次 DFS 自底向上预处理诸如深度,子树大小,点权和之类的信息,在第二次 DFS 自顶向下开始运行换根动态规划。
//https://www.luogu.com.cn/problem/P3478
//给定一个n个点的树,请求出一个结点,使得以这个结点为根时,所有结点的深度之和最大。
#include <iostream>
#include <cstring>
using namespace std;
const int N = 2000006;
int n;
int h[N],e[N],ne[N],idx;
long long f[N],siz[N],deep[N];
void add(int a,int b){
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dfs_d(int u,int fa){
siz[u] = 1;
deep[u] = deep[fa]+1;
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(k == fa) continue;
dfs_d(k,u);
siz[u] += siz[k];
}
}
void dfs_u(int u,int fa){
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(k == fa) continue;
f[k] = f[u]-siz[k]+n-siz[k];
dfs_u(k,u);
}
}
int main(){
memset(h,-1,sizeof h);
cin >> n;
for(int i = 1;i < n;i++){
int a,b;cin >> a >> b;
add(a,b);add(b,a);
}
dfs_d(1,0);//一般第一遍dfs由底回溯到根统计信息
for(int i = 1;i <= n;i++) f[1] += deep[i];//任选一个点(一般为1)作为根
dfs_u(1,0);//再dfs由根到底考虑将根不断转移到子节点,更新每个节点作为根时的答案
long long ans = 0,p = 0;
for(int i = 1;i <= n;i++){
if(ans < f[i]){ ans = f[i]; p = i; }
}
cout << p;
}
//hdu2196 computer https://acm.hdu.edu.cn/showproblem.php?pid=2196
//求每个节点距离其它节点的最远距离
#include <iostream>
#include <cstring>
using namespace std;
const int N = 20004;
int n;
int h[N],e[N],ne[N],idx,w[N];
int d1[N],d2[N],p1[N],p2[N],up[N];//d1和d2为节点u向下的最大值和次大值,up为向上的最大值
void add(int a,int b,int c){
w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
void dfs_d(int u,int fa){
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(k == fa) continue;
dfs_d(k,u);
int t = d1[k] + w[i];
if(t > d1[u]){
d2[u] = d1[u];d1[u] = t;
p2[u] = p1[u];p1[u] = k;
}
else if(t > d2[u]){
d2[u] = t;
p2[u] = k;
}
}
}
void dfs_u(int u,int fa){
for(int i = h[u];~i;i = ne[i]){
int k = e[i];
if(k == fa) continue;
if(p1[u] == k){ up[k] = max(up[u],d2[u]) + w[i]; }
else { up[k] = max(up[u],d1[u]) + w[i];}
dfs_u(k,u);
}
}
int main(){
while(cin >> n){
for(int i = 1;i <= n;i++){
h[i] = -1; d1[i] = d2[i] = up[i] = 0;
}
idx = 0;
for(int i = 2;i <= n;i++){
int b,c;cin >> b >> c;
add(i,b,c);add(b,i,c);
}
dfs_d(1,0);
dfs_u(1,0);
for(int i = 1;i <= n;i++){
int now = max(d1[i],up[i]);
cout << now << '\n';
}
}
}
记忆化搜索
记忆化搜索是一种通过记录已经遍历过的状态的信息,从而避免对同一状态重复遍历的搜索实现方式。
因为记忆化搜索确保了每个状态只访问一次,它也是一种常见的动态规划实现方式。
滑雪
//https://ac.nowcoder.com/acm/problem/235954
#include <iostream>
#include <cstring>
using namespace std;
const int N = 305;
int n, m;
int a[N][N];
int dp[N][N];//dp[i][j]表示从i,j开始滑的最长路径
int px[] = { 0,0,-1,1 }, py[] = { 1,-1,0,0 };
int dfs(int x, int y) {
if (dp[x][y]) return dp[x][y];//如果已经计算过了,就可以直接返回答案,避免重复计算
dp[x][y] = 1;//注意dp[x][y]至少为1(四个方向都不能滑)
for (int i = 0; i < 4;i++) {//枚举上下左右四个方向
int dx = x + px[i], dy = y + py[i];
if (dx >= 1 && dx <= n && dy >= 1 && dy <= m && a[x][y]>a[dx][dy]) {//判断能否从x,y滑向滑dx,dy
dp[x][y] = max(dp[x][y], dfs(dx, dy) + 1);//更新dp[x][y]
}
}
return dp[x][y];
}
int main() {
cin >> n >> m;
for (int i = 1; i <= n;i++) {
for (int j = 1; j <= m;j++) {
cin >> a[i][j];
}
}
int ans = 0;//因为可以在任意一点开始滑,所以要遍历一遍滑雪场,取最大值
for (int i = 1; i <= n;i++) {
for (int j = 1; j <= m;j++) {
ans = max(ans, dfs(i, j));
}
}
cout << ans;
}
DP优化
单调队列优化
- 加入所需元素:向单调队列重复加入元素直到当前元素达到所求区间的右边界,这样就能保证所需元素都在单调队列中。
- 弹出越界队首:单调队列本质上是维护的是所有已插入元素的最值,但我们想要的往往是一个区间最值。于是我们弹出在左边界外的元素,以保证单调队列中的元素都在所求区间中。
- 获取最值:直接取队首作为答案即可。
//烽火传递 https://loj.ac/p/10180
//给定数组a[N],每连续m个元素至少有一个被选中,最小选中代价
#include <iostream>
using namespace std;
const int N = 200005;
int n,m,a[N];
int dp[N];//dp[i]表示选择第i个时的最小代价
int q[N],hh,tt;
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++) cin >> a[i];
for(int i = 1;i <= n;i++){
dp[i] = dp[q[hh]] + a[i];//队首即为最值 dp[i] = min(dp[i-m]~dp[i-1]) + a[i]
if(hh <= tt && i - q[hh] >= m) hh++;//弹出越界队首
while(hh <= tt && dp[i] <= dp[q[tt]]) tt--;//加入所需元素,并保持队列单调递增
q[++tt] = i;
}
int ans = 0x3f3f3f3f;
for(int i = n-m+1;i <= n;i++) ans = min(ans,dp[i]);
cout << ans;
}
//修剪草坪 https://loj.ac/p/10177
//给定a[N],不能选择连续m个元素,求最大代价
//dp[i] = max(dp[i-1],max(dp[j-1]+sum(j+1,i))) //选/不选第i个
//其中dp[j-1]+sum(j+1,i) = dp[j-1] + s[i] - s[j] 只需要单调队列求出最大的dp[j-1]-s[j]
#include <iostream>
using namespace std;
const int N = 100005;
int n,m;
long long a[N],dp[N];
int q[N],hh,tt;
long long g(int i){
return dp[i-1] - a[i];
}
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++){
cin >> a[i]; a[i] += a[i-1];
}
for(int i = 1;i <= n;i++){
dp[i] = max(dp[i-1],g(q[hh]) + a[i]);
//区间[i-m,i-1],窗口大小为m (不包括i)
if(hh <= tt && i - q[hh] >= m) hh++;
//区间[i-m+1,i-1],窗口大小为m-1 (不包括i)
while(hh <= tt && g(i) >= g(q[tt])) tt--;
q[++tt] = i;
//区间[i-m+1,i],窗口大小为m (包括i)
}
cout << dp[n];
}
数据结构优化
给定n个区间以及其花费{ [ l , r ] , c },选择合理的区间使其能够完全覆盖区间[st,ed],并使得总花费最小
将所有区间按右端点排序后,遍历n个区间,对于当前区间l,r,c
dp[r] = min(dp[r] , dp[l-1~r-1] + c)
考虑线段树优化,单点修改,求区间最小值
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100005;
const long long INF = 0x3f3f3f3f3f3f3f3f;
int n,st,ed;
long long dp[N];
struct node{
int l,r;
long long c;
bool operator < (const auto &e2){
return r < e2.r;
}
}a[N];
struct ST{
int l,r;
long long dat;
}t[N<<2];
void pushup(ST &p,ST &pl,ST &pr){
p.dat = min(pl.dat,pr.dat);
}
void pushup(int p){
pushup(t[p],t[p<<1],t[p<<1|1]);
}
void build(int p,int l,int r){
t[p] = {l,r};
if(l == r){
t[p].dat = INF;
return;
}
int mid = l + r >> 1;
build(p<<1,l,mid);build(p<<1|1,mid+1,r);
pushup(p);
}
void modify(int p,int l,int r,long long x){
if(l <= t[p].l && r >= t[p].r){
t[p].dat = x;
return;
}
int mid = t[p].l + t[p].r >> 1;
if(l <= mid) modify(p<<1,l,r,x);
if(r > mid) modify(p<<1|1,l,r,x);
pushup(p);
}
ST query(int p,int l,int r){
if(l <= t[p].l && r >= t[p].r){
return t[p];
}
int mid = t[p].l + t[p].r >> 1;
if(r <= mid) return query(p<<1,l,r);
if(l > mid) return query(p<<1|1,l,r);
ST pl = query(p<<1,l,r),pr = query(p<<1|1,l,r),ans;
pushup(ans,pl,pr);
return ans;
}
int main(){
cin >> n >> st >> ed;
build(1,0,ed);
for(int i = 1;i <= n;i++){
cin >> a[i].l >> a[i].r >> a[i].c;
}
sort(a+1,a+n+1);
memset(dp,0x3f,sizeof dp);
for(int i = 1;i <= n;i++){
auto [l,r,c] = a[i];
if(l - 1 <= st - 1) dp[r] = min(dp[r],c);
else dp[r] = min(dp[r],query(1,l-1,r-1).dat + c);
modify(1,r,r,dp[r]);
}
if(dp[ed] == INF) cout << -1;
else cout << dp[ed];
}
树状数组优化 UVA12983 (luogu.com.cn)
在长度为n的数列a[ ]中,求长度为m的严格上升子序列的个数
dp[i,j]表示以a[i]结尾,且长度为j的上升子序列个数
dp[i,j] = $\sum dp[k,j-1]$ 其中1 <= k < i && a[k] < a[i]
考虑将a[ ]离散化后建立树状数组,query(id(a[i])-1) 为1~id(a[i])中的$\sum dp[k,j-1]$,插入的先后顺序保证了不会重复计算到后面的值
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 1005,mod = 1e9+7;
int n,m;
int a[N],hs[N];
long long t[N],dp[N][N];
void add(int p,long long x){
while(p <= n){
t[p] = (t[p] + x)%mod;
p += p&-p;
}
}
long long query(int p){
long long ans = 0;
while(p > 0){
ans = (ans + t[p]) % mod;
p -= p&-p;
}
return ans;
}
void sol(){
memset(dp,0,sizeof dp);
cin >> n >> m;
for(int i = 1;i <= n;i++){
scanf("%d",&a[i]);hs[i] = a[i];
}
sort(hs+1,hs+n+1);
for(int i = 1;i <= n;i++){ a[i] = lower_bound(hs+1,hs+n+1,a[i])-hs; }
for(int i = 1;i <= n;i++){ dp[i][1] = 1;}
for(int j = 2;j <= m;j++){
memset(t,0,sizeof t);
for(int i = 1;i <= n;i++){
dp[i][j] = query(a[i]-1);
add(a[i],dp[i][j-1]);
}
}
long long ans = 0;
for(int i = 1;i <= n;i++){
ans = (ans + dp[i][m]) % mod;
}
cout << ans << '\n';
}
int main(){
int T;cin >> T;
for(int o = 1;o <= T;o++){
cout << "Case #" << o << ": ";sol();
}
}
斜率优化
【学习笔记】动态规划—斜率优化DP(超详细)——辰星凌的博客QAQ
先写出DP方程,例如:$dp[i] = min{dp[j] + (s[i]-s[j])^2 + m}$ 去掉$min$,对齐进行移项变换为$y = kx+b$的点斜式。 把含有$function(i)funciton(j)$的表达式看做斜率$k$乘以未知数$x$,含有$dp[i]$或常数项在$b$的表达式中,含有$function(j)$的项在$y$的表达式中。 $dp[j] + s[j]^2 = 2s[i]s[j] + dp[i]-s[i]^2-m$。 此处 $y = dp[j] +s[j]^2$,$k = 2s[i]$,$x = s[j]$,$b = dp[i]-s[i]^2 - m$。 即找出一个点$(s[j],dp[j]+s[j]^2)$,使得$b$也即$dp[i]$最大
写出DP方程后,判断能否使用斜率优化,即是否存在 $function(i) * function(j)$ 的项,或者 $\frac{Y(j)-Y(j’)}{X(j) - X(j’)}$
通过大小于符号或者换$b$中$dp[i]$的符号结合题目要求$(min/max)$判断是上凸包还是下凸包。
P10979 任务安排 2 - 洛谷 (luogu.com.cn) \(dp[i] = min_{0\le j<i}\{dp[j]-(s+st[i])*sc[j]\} + st[i]*sc[i]+s*sc[n]\) 把$min$函数去掉,把关于$j$的值$dp[j]$和$sc[j]$看作变量,其余部分看作常数得到: \(dp[j] = (s+st[i])*sc[j]+dp[i]-st[i]*sc[i]-s*sc[n]\) 以$sc[j]$为横坐标,$dp[j]$为纵坐标建立平面直角坐标系,当前点$i$斜率$k$为固定值$s+st[i]$,决策候选集合是坐标系中的一个点集,每个决策j都对应着坐标系中的一个点$(sc[j],dp[j])$,要使$dp[i]$最小,也就是在前$i-1$个点中选择一个点,使得在$k$一定的情况下,截距最小,不难发现,答案必然在原点集的一个右下凸包上:

由于本题中$t$为正整数,$st$递增也即斜率$k$递增,每次决策时将队首斜率小于$k$的弹出,队头即为目标 $j$。 将点$i$插入前,诺队尾两点和点$i$形成凹包,则不断将队尾弹出,直到满足凸包。
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 300005;
long long n,s;
long long dp[N];
long long c[N],t[N],sc[N],st[N];
int q[N],hh,tt;
long long X(int i){return sc[i];}
long long Y(int i){return dp[i];}
long long up(int a,int b) {return Y(a) - Y(b);}//分子
long long down(int a,int b) {return X(a) - X(b);}//分母
int main(){
cin >> n >> s;
for(int i = 1;i <= n;i++){
cin >> t[i] >> c[i];
st[i] = st[i-1] + t[i];
sc[i] = sc[i-1] + c[i];
}
for(int i = 1;i <= n;i++){
int k = st[i] + s;
while(hh <= tt-1 && up(q[hh+1],q[hh]) <= k * down(q[hh+1],q[hh])) hh++;
int j = q[hh];
dp[i] = dp[j] - (s+st[i])*sc[j] + st[i]*sc[i] + s*sc[n];
while(hh <= tt-1 && up(i,q[tt])*down(q[tt],q[tt-1]) <= up(q[tt],q[tt-1])*down(i,q[tt]))tt--;
q[++tt] = i;
}
cout << dp[n];
}
[P5785 SDOI2012] 任务安排 - 洛谷 (luogu.com.cn)
本题,诺k不满足单调性,则需要维护整个凸包,每次决策时只需要在队列中用二分/CDQ/平衡树找到点 j 满足:点j左边的斜率都小于k,右边的斜率都大于k。
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 300005;
long long n,s;
long long dp[N];
long long c[N],t[N],sc[N],st[N];
int q[N],hh,tt;
struct node{
long long x,y;
};
int lb(long long k,int bl,int br){
auto check = [&](int x)->bool{
node p1 = {sc[q[x]],dp[q[x]]},p2 = {sc[q[x+1]],dp[q[x+1]]};
return (p2.y - p1.y) >= k*(p2.x - p1.x);
};
int l = bl,r = br;
while(l < r){
int mid = l + r >> 1;
if(check(mid)) r = mid;
else l = mid + 1;
}
return q[r];
}
int main(){
cin >> n >> s;
for(int i = 1;i <= n;i++){
cin >> t[i] >> c[i];
st[i] = st[i-1] + t[i];
sc[i] = sc[i-1] + c[i];
}
for(int i = 1;i <= n;i++){
int j = lb(st[i]+s,hh,tt);
dp[i] = dp[j] - (s+st[i])*sc[j] + st[i]*sc[i] + s*sc[n];
while(hh <= tt - 1){
node p1 = {sc[q[tt-1]],dp[q[tt-1]]},p2 = {sc[q[tt]],dp[q[tt]]},p3 = {sc[i],dp[i]};
if(__int128(p3.y-p2.y)*(p2.x-p1.x) <= __int128(p2.y-p1.y)*(p3.x-p2.x)) tt--;
else break;
}
q[++tt] = i;
}
cout << dp[n];
}
对于每只小猫所需要的早出发时间为$a[i] = t[i]-\sum{d[i]}$,排序后对a[ ]建立前缀和数组s[ ]
令dp[i][j]表示前i个人运输前j只小猫所需要的最小等待次数。第i个人运输第k+1~j只猫。则有:
\(dp[i][j] = min\{dp[i-1][k]+a[j]*(j-k)-(s[j]-s[k])\}\)
去掉min,移项得:
\(dp[i-1][k]+s[k] = a[j]*k + dp[i][j]-a[j]*j+s[j]\)
斜率优化O(1)求出k,以k为横轴,dp[i-1][k]+s[k]为纵轴建立坐标系,当前斜率为a[j],坐标轴上每个点为(k,dp[i-1][k]+s[k])
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100005;
int n,m,p;
long long d[N];
long long h[N],t[N],a[N],s[N];
long long dp[105][N];
int q[N],hh,tt;
struct node{
long long x,y;
};
int main(){
cin >> n >> m >> p;
for(int i = 2;i <= n;i++){
cin >> d[i];
d[i] += d[i-1];
}
for(int i = 1;i <= m;i++){
cin >> h[i] >> t[i];
a[i] = t[i] - d[h[i]];
}
sort(a+1,a+m+1);
for(int i = 1;i <= m;i++){
s[i] = s[i-1] + a[i];
}
memset(dp,0x3f,sizeof dp);
dp[0][0] = 0;
for(int i = 1;i <= p;i++){
hh = 0,tt = 0;
for(int j = 1;j <= m;j++){
while(hh <= tt - 1){//由于斜率a[j]递增,每次维护队首即可
node p1 = {q[hh],dp[i-1][q[hh]]+s[q[hh]]},p2 = {q[hh+1],dp[i-1][q[hh+1]]+s[q[hh+1]]};
if((p2.y-p1.y) <= a[j]*(p2.x-p1.x)) hh++;
else break;
}
dp[i][j] = dp[i-1][q[hh]] + a[j]*(j-q[hh])-s[j]+s[q[hh]];
while(hh <= tt-1){
node p1 = {q[tt-1],dp[i-1][q[tt-1]]+s[q[tt-1]]},p2 = {q[tt],dp[i-1][q[tt]]+s[q[tt]]};
node p3 = {j,dp[i-1][j]+s[j]};//插入的点p3,取值应为dp[i-1]
if((p3.y-p2.y)*(p2.x-p1.x) <= (p2.y-p1.y)*(p3.x-p2.x)) tt--;
else break;
}
q[++tt] = j;
}
}
cout << dp[p][m];
}
其他
环形处理
断环成链,复制拼接
P10957 环路运输 - 洛谷 (luogu.com.cn)
#include <iostream>
using namespace std;
const int N = 2000006;
int n;
long long a[N];
int q[N],hh,tt;
long long g(int i){
return a[i] - i;
}
int main(){
cin >> n;
for(int i = 1;i <= n;i++){
cin >> a[i];
a[i+n] = a[i];
}
long long ans = 0;
for(int i = 1;i <= n << 1;i++){//单调队列优化
ans = max(ans,a[i] + i + g(q[hh]));
if(hh <= tt && i - q[hh] >= n/2) hh++;
while(hh <= tt && g(i) >= g(q[tt])) tt--;
q[++tt] = i;
}
cout << ans;
}
二次DP
一次选择N和1断开,另一次选择N和1连接。答案取两次DP的最值
[P6064 USACO05JAN] Naptime G - 洛谷 (luogu.com.cn)
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 3900;
int n,a[N],m;
int dp[2][N][2];
int main(){
cin >> n >> m;
for(int i = 1;i <= n;i++){
cin >> a[i];
}
memset(dp,-0x3f,sizeof dp);
for(int i = 1;i <= n;i++) dp[i&1][0][0] = 0;
dp[1&1][1][1] = 0;
for(int i = 2;i <= n;i++){
dp[i&1][0][0] = dp[(i-1)&1][0][0];
for(int j = 1;j <= m;j++){
dp[i&1][j][0] = max(dp[(i-1)&1][j][0],dp[(i-1)&1][j][1]);
dp[i&1][j][1] = max(dp[(i-1)&1][j-1][0],dp[(i-1)&1][j-1][1]+a[i]);
}
}
int ans = max(dp[n&1][m][0],dp[n&1][m][1]);
memset(dp,-0x3f,sizeof dp);
for(int i = 1;i <= n;i++) dp[i&1][0][0] = 0;
dp[1][1][1] = a[1];
for(int i = 2;i <= n;i++){
for(int j = 1;j <= m;j++){
dp[i&1][j][0] = max(dp[(i-1)&1][j][0],dp[(i-1)&1][j][1]);
dp[i&1][j][1] = max(dp[(i-1)&1][j-1][0],dp[(i-1)&1][j-1][1]+a[i]);
}
}
ans = max(ans,dp[n&1][m][1]);
cout << ans;
}
滚动数组
简要来说就是通过观察dp方程来判断需要使用哪些数据,可以抛弃哪些数据,一旦找到关系,就可以用新的数据不断覆盖旧的没用的数据来减少空间的使用。还要注意根据数据是否可以直接继承考虑是否需要情况数组
利用对自然数取模的周期性
//例:递推求斐波那契数列
for (int i=3;i<=n;i++) f[i%3]=f[(i-1)%3]+f[(i-2)%3];
cout << f[n%3];
dp[i][s1][s2] = max(dp[i][s1][s2],dp[i-1&1][s2][s3]+1);
//只用到了i-1项,可以优化为
dp[i&1][s1][s2] = max(dp[i&1][s1][s2],dp[i-1&1][s2][s3]+1);
for(int i = 1;i <= n+1;i++){//dp[N][M]
for(auto s1:st[i-1]){
for(auto s2:st[i]){
if(s1&s2) continue;
dp[i][s2] = (dp[i][s2]+dp[i-1][s1])%mod;
}
}
}
//可以优化为
for(int i = 1;i <= n+1;i++){//dp[2][M]
for(auto s1:st[i-1]){
for(auto s2:st[i]){
if(s1&s2) continue;
dp[i&1][s2] = 0;
}
}
for(auto s1:st[i-1]){
for(auto s2:st[i]){
if(s1&s2) continue;
dp[i&1][s2] = (dp[i&1][s2]+dp[i-1&1][s1])%mod;
}
}
}
状态机DP
给定m个DNA序列片段,计算有多少长度为n的DNA序列不包含上述m个片段 $0\le m \le 10,1\le n \le 2*10^9$
#include <iostream>
#include <queue>
#include <cstring>
#include <vector>
namespace ACAM{
const int N = 105,M = 4;
int son[N][M],cnt[N],fail[N],idx;
struct Trie{
Trie(){idx = 0;init(idx);};
void init(int p){
fail[p] = cnt[p] = 0;
std::memset(son[p],0,sizeof son[p]);
}
int get(char x){
if(x == 'A') return 0;
if(x == 'C') return 1;
if(x == 'T') return 2;
if(x == 'G') return 3;
return 0;
}
void insert(const std::string &s){
int p = 0;
for(int i = 0;i < s.size();i++){
int u = get(s[i]);
if(!son[p][u]){
son[p][u] = ++idx;
init(idx);
}
p = son[p][u];
}
cnt[p]++;
}
void get_fail(){
std::queue<int>q;
for(int u = 0;u < M;u++){
if(son[0][u]) {
fail[son[0][u]] = 0;
q.push(son[0][u]);
}
}
while(q.size()){
int p = q.front();
q.pop();
cnt[p] |= cnt[fail[p]];//将当前节点的禁止状态与fail指针的禁止状态合并
for(int u = 0;u < M;u++){
if(son[p][u]) {
fail[son[p][u]] = son[fail[p]][u];
q.push(son[p][u]);
}
else{
son[p][u] = son[fail[p]][u];
}
}
}
}
};
}
using ACAM::Trie;
using ACAM::fail,ACAM::son,ACAM::cnt,ACAM::idx;
const int mod = 100000;
template<typename T>
struct Mat{
int n;
std::vector<std::vector<T>>a;
Mat(int _n,T val){
n = _n;
a = std::vector<std::vector<T>>(n,std::vector<T>(n,val));
}
Mat<T> operator * (const Mat<T> &m2){
Mat<T> ans(n,0);
for(int i = 0;i < n;i++){
for(int j = 0;j < n;j++){
for(int k = 0;k < n;k++){
ans.a[i][j] = (ans.a[i][j] + a[i][k] * m2.a[k][j]) % mod;
}
}
}
return ans;
}
void norm(){
for(int i = 0;i < n;i++) a[i][i] = 1;
}
Mat<T> qmi(long long b){
auto base = *this;
Mat<T> ans(n,0);
ans.norm();
while(b){
if(b&1) ans = ans * base;
b >>= 1;
base = base * base;
}
return ans;
}
};
const int N = 12;
std::string s[N];
int main(){
int m,n; std::cin >> m >> n;
Trie t;
for(int i = 1;i <= m;i++){
std::cin >> s[i];
t.insert(s[i]);
}
t.get_fail();
Mat<long long> base(idx+1,0);
for(int i = 0;i <= idx;i++){
for(int u = 0;u < 4;u++){
int p = son[i][u];
if(cnt[p]) continue;
base.a[p][i]++;//状态i通过字符c转移至状态p //dp[k][p] += dp[k-1][i]
}
}
base = base.qmi(n);//矩阵快速幂加速递推
long long res = 0;
for(int i = 0;i <= idx;i++){
res = (res + base.a[i][0]) % mod;
}
std::cout << res;
}
贪心
区间问题
区间选点
给定 N 个闭区间 [ai,bi] ,请你在数轴上选择尽量少的点,使得每个区间内至少包含一个选出的点。 输出选择的点的最小数量。(位于区间端点上的点也算作区间内)
//https://www.acwing.com/problem/content/907/
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100005;
int n;
struct Edge{
int l,r;
}e[N];
int main(){
cin >> n;
for(int i = 1;i <= n;i++){ cin >> e[i].l >> e[i].r; }
sort(e+1,e+n+1,[](auto&e1,auto&e2){return e1.l < e2.l;});//按左端点从小到大排序
int ans = 1;
int ed = e[1].r;
for(int i = 2;i <= n;i++){
if(e[i].l > ed){
ans++;
ed = e[i].r;
}
else{
ed = min(ed,e[i].r);
}
}
cout << ans;
}
//畜栏预定 https://www.acwing.com/problem/content/113/
//给定N段区间[l,r],当两个区间相交时(包括端点),这两头牛不能安排在同一个畜栏吃草
//求需要的最小畜栏数目和每头牛对应的畜栏方案
#include <iostream>
#include <algorithm>
#include <queue>
using namespace std;
const int N = 100005;
using pii = pair<int,int>;
int n;
int id[N];
struct Edge{
int l,r,rk;
}e[N];
int main(){
cin >> n;
for(int i = 1;i <= n;i++){
cin >> e[i].l >> e[i].r;
e[i].rk = i;
}
sort(e+1,e+n+1,[](auto &e1,auto &e2){return e1.l < e2.l;});
//按左端点将区间排序
priority_queue<pii,vector<pii>,greater<pii>>pq;
//堆中存放的元素为<当前分组内区间右端点的最小值,畜栏编号>
for(int i = 1;i <= n;i++){
if(pq.empty() || pq.top().first >= e[i].l){//新建堆
//当前堆为空 或 堆顶最小值右端点r与当前牛左端点l重合
pii t = {e[i].r,pq.size()};
id[e[i].rk] = t.second;
pq.push(t);
}
else{//使用原来的堆
auto t = pq.top();
pq.pop();//弹出堆顶
t.first = e[i].r;//让当前牛使用该畜栏
id[e[i].rk] = t.second;//记录答案
pq.push(t);
}
}
cout << pq.size() << endl;
for(int i = 1;i <= n;i++){
cout << id[i]+1 << endl;
}
}
区间合并
现给定 𝑛个闭区间 𝑎𝑖,𝑏𝑖(1≤𝑖≤𝑛)。这些区间的并可以表示为一些不相交的闭区间的并。在这些表示方式中找出包含最少区间的方案。
//https://www.luogu.com.cn/problem/P2434
#include <bits/stdc++.h>
using PII = std::pair<int, int>;
using namespace std;
struct P {
int l,r;
}p[50005];
queue<PII>q;
bool cmp(P p1, P p2) {
return p1.l < p2.l;
}
int main() {
int n; cin >> n;
for (int i = 0; i < n; i++) {
cin >> p[i].l >> p[i].r;
}
sort(p, p + n, cmp);
int op = p[0].l, ed = p[0].r;
for (int i = 0; i < n; i++) {
if (ed >= p[i].l) {
ed = max(ed, p[i].r);
}
else {
q.push({ op,ed });
op = p[i].l;
ed = p[i].r;
}
}
q.push({ op,ed });
while (q.size()) {
cout << q.front().first << ' ' << q.front().second << endl;
q.pop();
}
}
不相交区间
给定 𝑁 个闭区间 [𝑎𝑖,𝑏𝑖],请你在数轴上选择若干区间,使得选中的区间之间互不相交(包括端点)。 输出可选取区间的最大数量。
//https://www.acwing.com/problem/content/910/
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100005;
int n;
struct Point {
int x, y;
}p[N];
bool cmp(Point p1, Point p2) {
return p1.x < p2.x;
}
int main() {
cin >> n;
for (int i = 1; i <= n;i++) {
cin >> p[i].x >> p[i].y;
}
sort(p + 1, p + n + 1,cmp);
int ans = 1;
int r = p[1].y;
for (int i = 2; i <= n; i++) {
if (p[i].y < r) {
r = p[i].y;
}
if (p[i].x > r) {
ans++;
r = p[i].y;
}
}
cout << ans;
}
区间覆盖
给定 N 个闭区间 [𝑎𝑖,𝑏𝑖] 以及一个线段区间 [𝑠,𝑡],请你选择尽量少的区间,将指定线段区间完全覆盖。 输出最少区间数,如果无法完全覆盖则输出 −1。
核心思想:在左端点l都小于a的情况下,取右端点最大的小区间
//https://www.acwing.com/problem/content/description/909/
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100005,INF = 0x3f3f3f3f;
struct P {
int x, y;
}p[N];
bool cmp(P p1, P p2) {
return p1.x < p2.x;
}
int main() {
int a, b; cin >> a >> b;
int n; cin >> n;
for (int i = 1; i <= n;i++) {
cin >> p[i].x >> p[i].y;
}
sort(p + 1, p + n + 1, cmp);
int ans = 0;
bool flag = 0;
for (int i = 1; i <= n;i++) {
int j = i, r = -INF;
while (j <= n && p[j].x <= a){
r = max(r, p[j].y);
j++;
}
if (r < a) {
ans = -1;
break;
}
ans++;
if (r >= b) {
flag = 1;
break;
}
a = r;
i = j - 1;
}
if (!flag) ans = -1;
cout << ans;
return 0;
}
区间分组
(某个点)最多同时重叠区间个数
给定 𝑁 个闭区间 [𝑎𝑖,𝑏𝑖],请你将这些区间分成若干组,使得每组内部的区间两两之间(包括端点)没有交集,并使得组数尽可能小。输出最小组数。
我们可以把所有开始时间和结束时间排序,遇到开始时间就把需要的教室数cnt加1,遇到结束时间就把需要的教室数cnt减1,在一系列需要的教室个数cnt变化的过程中,cnt的峰值就是多同时进行的活动数,也是我们至少需要的教室数。
如果值域较小,可以写差分
//https://www.acwing.com/problem/content/908/
#include <iostream>
#include <algorithm>
#include <vector>
#define fastio ios::sync_with_stdio(0),cin.tie(0)
using namespace std;
const int N = 100005;
vector<pair<int,int>>v;
struct Edge{
int l,r;
}e[N];
int main(){
fastio;
int n;cin >> n;
for(int i = 1;i <= n;i++){
auto&[l,r] = e[i];
cin >> l >> r;
v.emplace_back(l,0);//0代表开始
v.emplace_back(r,1);//1代表结束
}
sort(v.begin(),v.end());
int ans = 0;
int cnt = 0;
for(int i = 0;i < v.size();i++){
if(v[i].second == 0) cnt++;
else cnt--;
ans = max(ans,cnt);
}
cout << ans;
}
(任意长度为d的区间)最多/最少包含不同区间个数(重叠区间的长短并不重要)
//https://codeforces.com/contest/2014/problem/D
#include <bits/stdc++.h>
#define INF 0x3f3f3f3f
using ll = long long;
using namespace std;
void sol(){
ll n,d,k;cin >> n >> d >> k;
vector<ll>a(n+5);
for(int i = 1;i <= k;i++){//差分,让区间[l-d+1,r]加1
int l,r;cin >> l >> r;
a[max(l-d+1,(ll)0)]++;
a[r+1]--;
}
for(int i = 1;i <= n;i++){ a[i] += a[i-1];}//a[i]表示从点i开始,长为d的一段区间,包含不同区间的个数
ll kb = 0,pb = 0,km = INF,pm = 0;
for(int i = 1;i <= n-d+1;i++){
if(a[i] > kb){ kb = a[i];pb = i;}
if(a[i] < km){ km = a[i];pm = i;}
}
cout << pb << ' ' << pm << endl;
}
int main() {
int T = 1;cin >> T;
while(T--){ sol(); }
}
区间包含
//https://acm.hdu.edu.cn/showproblem.php?pid=7497
#include <bits/stdc++.h>
#define fastio ios::sync_with_stdio(false),cin.tie(0),cout.tie(0)
#define endl '\n'
#define ll long long
#define PII std::pair<int, int>
#define INF 0x3f3f3f3f
using namespace std;
int n,m;
struct Edge{
ll l,r;
ll len;
};
bool cmp(ll x,ll y){
return x < y;
}
bool cmp1(pair<ll,ll>x,pair<ll,ll>y){
if(x.first != y.first) return x.first < y.first;
else{ return x.second < y.second; }
}
void sol(){
cin >> n >> m;
vector<Edge>a(n),b(m);
vector<ll>all;
for(int i = 0;i < n;i++){
cin >> a[i].l >> a[i].r;
all.emplace_back(a[i].l*2+1);
all.emplace_back(a[i].r*2);
}
for(int i = 0;i < m;i++){
cin >> b[i].l >> b[i].r;
b[i].len = 2*(b[i].r-b[i].l);
all.emplace_back(b[i].l*2+1);
all.emplace_back(b[i].r*2);
}
sort(all.begin(),all.end(),cmp);
int cnt = 0;
for(int i = 0;i < all.size();i++){//判断A组区间与B组区间中是否存在区间香蕉(区间分组)
if(all[i]&1){ cnt++; }
else { cnt--; }
if(cnt > 1){ cout << "No" << endl; return; }
}
vector<pair<ll,ll>>al;
for(int i = 0;i < n;i++){
al.emplace_back(a[i].l,2);
al.emplace_back(a[i].r,3);
}
for(int i = 0;i < m;i++){
al.emplace_back(b[i].r,0);
al.emplace_back(b[i].r+b[i].len,4);
}
sort(al.begin(),al.end(),cmp1);
int ok = 0,cla = 0;//判断A组区间是否完全包含于C组区间(区间分组加强版)
for(int i = 0;i < al.size();i++){
if(al[i].second == 0) ok++;//0代表清醒状态开始
if(al[i].second == 4) ok--;//4代表清醒状态结束
if(al[i].second == 2) cla++;//2代表上课开始
if(al[i].second == 3) cla--;//3代表上课结束
if(cla >= 1 && ok <= 0){//如果出现当前正在上课,并且状态不清醒,返回No
cout << "No" << endl; return;
}
}
cout << "Yes" << endl;
}
int main() {
fastio; int T = 1;
cin >> T;
while(T--){sol();}
}
绝对值不等式
货仓选址
在一条数轴上有 𝑁 家商店,它们的坐标分别为 𝐴1∼𝐴𝑁。 现在需要在数轴上(任意一点)建立一家货仓,每天清晨,从货仓到每家商店都要运送一车商品。 为了提高效率,求把货仓建在何处,可以使得货仓到每家商店的距离之和最小。
在中位数处建点可以使得答案最小
//https://www.acwing.com/problem/content/106/
#include <iostream>
#include <cmath>
#include <algorithm>
using namespace std;
const int N = 100005;
int n,a[N];
int main(){
cin >> n;
for(int i = 1;i <= n;i++){
cin >> a[i];
}
sort(a+1,a+n+1);
long long ans = 0;
for(int i = 1;i <= n;i++){
ans+=abs(a[i]-a[n+1 >> 1]);
}
cout << ans;
}
均分纸牌
n个人坐在一排,每人有a[i]张纸牌,每次可将任意数量纸牌给相邻的一个人,求使所有人纸牌数相等的最小操作次数
//https://www.acwing.com/problem/content/1538/
#include <iostream>
using namespace std;
const int N = 10004;
int a[N];
int ans,sum;
int main(){
int n;cin >>n;
for(int i = 1;i <= n;i++){
cin >> a[i];
sum += a[i];
}
int avg = sum/n;
for(int i = 1;i < n;i++) {
a[i] -= avg;//最终所有人的纸牌一定变为平均数
if(a[i]){//不够的从i+1取,多的给i+1
a[i+1] += a[i];
ans++;
}
}
cout << ans;//每次可移动任意张,最小次数
}
环形均分纸牌
n个人围在一圈,每人有a[i]张纸牌,每次可将1张纸牌给相邻的一个人,求使所有人纸牌数相等的最小操作次数
//https://www.luogu.com.cn/problem/P2512
#include <iostream>
#include <algorithm>
using namespace std;
using ll = long long;
const int N = 1000006;
ll a[N],s[N];
int n;
ll sum,ans;
int main(){
cin >> n;
for(int i = 1;i <= n;i++) cin >> a[i],sum+=a[i];
ll avg = sum/n;
for(int i = 1;i <= n;i++){
s[i] = s[i-1] + a[i] - avg;
}
//s为a的所差的前缀和数组
//选取s的中位数最优,问题变为对s数组的货仓选址问题
sort(s+1,s+n+1);
ll mid = s[(n+1)/2];
for(int i = 1;i <= n;i++){
ans += abs(s[i] - mid);
}
cout << ans;//每次移动一张,最小次数
}
排序不等式
邻项交换法 证明在任意局面下,任何对局部最优策略的微小改变都会造成整体结果变差。经常用于以“排序”为贪心策略的证明。
诺交换相邻两项不会影响其他项的值,单独分析这两项,找出排序策略cmp
耍杂技的牛
奶牛们站在彼此的身上,形成一个高高的垂直堆叠。 这 𝑁 头奶牛中的每一头都有着自己的重量 𝑊𝑖 以及自己的强壮程度 𝑆𝑖。 一头牛支撑不住的可能性取决于它头上所有牛的总重量(不包括它自己)减去它的身体强壮程度的值,现在称该数值为风险值,风险值越大,这只牛撑不住的可能性越高。 确定奶牛的排序,使得所有奶牛的风险值中的最大值尽可能的小,求出该值。
将所有牛按w+s值从小到大排序时,最大的风险值一定最小
相邻两牛交换不会影响其它牛的风险值,所以只需要分析这两头牛即可
风险值 i牛 i+1牛 交换前: w[1]+….w[i-1]-s[i] w[1]+…+w[i-1]+w[i]-s[i+1] 交换后: w[1]+…+w[i-1]-s[i+1] w[1]+…+w[i-1]+w[i+1]-s[i] 交换前(化简): s[i+1] w[i]+s[i] 交换后(化简): s[i] w[i+1]+s[i+1] i牛风险值 -= s, i+1牛风险值 += s+w
//https://www.acwing.com/problem/content/127/
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 50004;
int n;
struct S{
int sum,w,s;
}s[N];
long long suf[N];
bool cmp(S x,S y){
return x.sum < y.sum;
}
int main(){
cin >> n;
for(int i = 1;i <= n;i++){
int a,b;cin >> a >> b;
s[i] = {a+b,a,b};
}
sort(s+1,s+n+1,cmp);
long long ans = -0x3f3f3f3f;
for(int i = 1;i <= n;i++){
suf[i] = suf[i-1]+s[i].w;
ans = max(ans,suf[i-1]-s[i].s);
}
cout << ans;
}
//栈压缩:https://qoj.ac/problem/9379
//国王游戏:https://www.acwing.com/problem/content/description/116/
后悔解法
无论当前的选项是否最优都接受,然后进行比较,如果选择之后不是最优了,则反悔,舍弃掉这个选项;否则,正式接受。如此往复。
给定N个工作,每个工作截止日期为$D_i$,如果能在截止日期前完成则会获得$P_i$的报酬,每天只能完成一项工作。$1\le N \le 10^5,1\le D_i,P_i \le 10^9$
//https://www.luogu.com.cn/problem/P2949
#include <iostream>
#include <queue>
#include <algorithm>
using namespace std;
using ll = long long;
using pii = pair<ll,ll>;
const int N = 100005;
ll ans;
struct Edge{
ll d,p;
}e[N];
int main(){
int n;cin >> n;
for(int i = 1; i <= n;i++){ cin >> e[i].d >> e[i].p; }
sort(e+1,e+n+1,[](auto &e1,auto &e2){return e1.d < e2.d;});
//将每一项工作按截止时间从小到大排序
priority_queue<ll,vector<ll>,greater<ll>>pq;//小根堆存决定做的工作的报酬p
//pq.size()即为做这些工作的最少安排时间
for(int i = 1;i <= n;i++){
if(e[i].d <= pq.size()){//如果当前工作截止时间与已经安排的时间冲突
if(e[i].p > pq.top()){//且选择当前工作比之前决定的工作报酬更高,则反悔之前报酬最低的决定
//ans += e[i].p - pq.top();
pq.pop();
pq.push(e[i].p);
}
}
else{//否则安排当前决定
//ans += e[i].p;
pq.push(e[i].p);
}
}
while(pq.size()){
ans += pq.top();
pq.pop();
}
cout << ans;
}
//https://codeforces.com/problemset/problem/1526/C2
//给你一个长度为n的序列A[],要求你找出最长的一个子序列使得这个子序列任意前缀和都非负。
#include <bits/stdc++.h>
int T = 1;
using ll = long long;
using namespace std;
void sol(){
int n;cin >>n;
unsigned ans = 0;
ll sum = 0;
priority_queue<ll,vector<ll>,greater<ll>>pq;
while(n--){
int x;cin >> x;
pq.push(x);//无论当前选择是否最优,先接受
sum += x;
while(sum < 0){//诺接受后不是最优,则反悔之前最差的决定
sum -= pq.top();
pq.pop();
}
ans = max(ans,pq.size());
}
cout << ans << endl;
}
int main() {
while(T--){ sol(); }
}
其它
字符与数字转换
ASCII码范围为0~127,注意不要越界,否则会乱码
字符串 <=> 数字
//字符串->数字
//atoi整型 atol长整型 atoll长长整型 atof浮点型 默认参数为const char*类型
//stoi类似,默认参数为const string*类型,且超出int范围会报错
string s1 = "123456";
int n = stoi(s1); //string类型字符串
int n1 = atoi(s1.c_str()); //c_str() 函数可以将 const string* 类型 转化为 cons char* 类型
char s2[] = "123456";
int n2 = atoi(s2); //char[]类型字符串
//数字->字符串
int n = 541;
string a = to_string(n);//#include<string>
//数字<=>字符串
//使用sstream 输入流
stringstream ss;
int n = 123456;
string str;
ss << n;
ss >> str;
字符c <=> 数字n
//字符c 转 数字n
n = c - '0' ; //或者 -48
//数字n 转 字符c
c = n + '0';
大小写转换
s[i] ^= ' ';//大小写互转 空格' '为char(32)
s[i] = tolower(s[i]);//转小写 s[i] |= ' '
s[i] = toupper(s[i]);//转大写 s[i] &= ~' '
进制转换
stoi k进制转十进制
stoi(字符串, 0, k进制):将一串k进制的字符串转换为 int 型数字。- stoll,stoull,stod,stold 同理。
//s为0~9 + 'a'~'z'
#include <iostream>
using namespace std;
int main(){
string s = "100";
int n = stoi(s,0,16);//将16进制的s转为十进制
cout << n << endl;
}
//s为数字
ll calc(vector<int> s,int k){
ll ans = 0;
ll base = 1;
for(int i = s.size()-1;i >= 0;i--){
ans += s[i]*base;
base *= k;
}
return ans;
}
十进制转k进制
建议直接手写进制转换函数
//n是待转换的十进制数,m是待转换成的进制数
//以数字+字母表示
string intToA(int n,int k){
string ans="";
do{ //使用do循环防止n为0的情况
int t =n %k;
if(t>=0&&t<=9) ans+=(t+'0');
else ans+=(t-10+'a');
n/=k;
}while(n);
reverse(ans.begin(),ans.end());
return ans;
}
//以数字表示
vector<int> calc(int n , int m){
vector<int>ans;
do{
ans.push_back(n%m);
n /= m;
}while(n);
reverse(ans.begin(),ans.end());
return ans;
}
//sprintf十进制转8/16进制
#include <iostream>
using namespace std;
int main() {
int n; cin >> n;
char s[100];
//x/X -16进制(大小写)
//o -8进制
//d -10进制
sprintf(s, "%x", n);
cout << s << endl;
return 0;
}
itoa
【注意】 不建议使用 itoa并不是一个标准的C函数,它是Windows特有的,如果要写跨平台的程序,需要用spraint。
【函数原型】char *itoa(int value, char *string, int radix);
【参数说明】 value:要转换的数据。 string:目标字符串的地址。 radix:转换后的进制数,可以是10进制、16进制等,范围必须在 2-36。
#include <iostream>
using namespace std;
int main() {
int n;cin >> n;
char str[100];
_itoa(n, str,36 );//例:10进制转36进制存于字符串str中
cout << str;
return 0;
}
精度/溢出问题
double n = 3.8;
double ans = n - int(n);
ans*=10;
int ans1 =int(ans);
cout << ans1 << endl;//预期为8,输出结果却是7
#define eps = 1e-8
double n = 3.8;
double ans = n - int(n);
ans*=10;
int ans1 =int(ans + eps);//对于负数的情况,只需要把ans + eps改为ans - eps即可
cout << ans1 << endl;//正确输出8
现在考虑一种情况,题目要求输出保留两位小数。有个case的正确答案的精确值是0.005,按理应该输出0.01,但你的结果可能是0.005000000001(恭喜),也有可能是0.004999999999(悲剧),如果按照printf(“%.2lf”, a)输出,那你的遭遇将和括号里的字相同。
解决办法是,如果a为正,则输出a+eps, 否则输出a-eps
两个浮点数之间的比较,eps缩写自epsilon,表示一个小量,但这个小量又要确保远大于浮点运算结果的不确定量。eps最常见的取值是1e-8左右。引入eps后,我们判断两浮点数a、b相等的方式如下:
定义三出口函数如下: int sgn(double a){return a < -eps ? -1 : a < eps ? 0 : 1;}
则各种判断大小的运算都应做如下修正:
| 传统意义 | 修正写法1 | 修正写法2 |
|---|---|---|
| a == b | sgn(a - b) == 0 | fabs(a – b) < eps |
| a != b | sgn(a - b) != 0 | fabs(a – b) > eps |
| a < b | sgn(a - b) < 0 | a – b < -eps |
| a <= b | sgn(a - b) <= 0 | a – b < eps |
| a > b | sgn(a - b) > 0 | a – b > eps |
| a >= b | sgn(a - b) >= 0 | a – b > -eps |
除法之间比较尽量转换为乘法之间比较,如$\frac{a}{b} < \frac{c}{d}$判断改为$ad < bc$
或者利用乘法逆元判断
//https://ac.nowcoder.com/acm/contest/93218/D
//求平面上有多少个不同的直线
#include <bits/stdc++.h>
int T = 1; using ll = long long;
const int mod = 1e9+7;
using namespace std;
const int N = 1003;
int n;
ll x[N],y[N];
ll qmi(ll a,ll b,ll p){
ll ans = 1;
while(b){
if(b&1) ans = ans*a%p;
b>>=1;
a = a*a%p;
}
return ans%p;
}
pair<ll,ll> uuz(ll x1,ll y1,ll x2,ll y2){
ll k;
if(y1 == y2) k = 1e18;//特判斜率不存在的情况
else if(x1 == x2) k = 0;
else k = (x1-x2)*qmi(y2-y1,mod-2,mod)%mod;//除法转乘法逆元
ll b = (y2*y2-y1*y1+x2*x2-x1*x1)*qmi(2*(y2-y1),mod-2,mod)%mod;
return {k,b};
}
void sol(){
cin >> n;
for(int i = 1;i <= n;i++){cin >> x[i];}
for(int i = 1;i <= n;i++){cin >> y[i];}
map<pair<ll,ll>,int>mp;
for(int i = 1;i <= n;i++){
for(int j = i+1;j <= n;j++){
auto [k,b] = uuz(x[i],y[i],x[j],y[j]);
if(k == 1e18) mp[{k,x[i]+x[j]}]++;
else mp[{k,b}]++;
}
}
cout << mp.size() << '\n';
}
int main() {
cin >> T;
while(T--){ sol(); }
}
sqrt
int ans1 = 0,ans2 = 0,ans3 = 0;
for(int i = 1;i <= 100;i++){
if(i == sqrt(i)*sqrt(i)) ans1++;//53
if(i - sqrt(i)*sqrt(i) < 1e-9) ans2++;//100
if(i == (int)sqrt(i)*sqrt(i)) ans3++;//10
}
sqrtl返回值为long double类型,精度更高。Yet Another Simple Math Problem - Problem - QOJ.ac
pow/ceil/floor/round参数类型和返回值类型均为浮点型,可能会导致输出与预期不符而wrong answer
int a = 1234;
cout << a*a << endl;//1522756
cout << pow(a, 2) << endl;//1.52276e+06 可以用int n = pow(a,2)类型转换再输出n
有符号整型 - 无符号整型
vector<int>v(3);
int n = 2;
while(n - v.size() > 0){
//预期2-3 = -1
//实际却是4294967295导致死循环
//应改写为while(n > s.size()) 或 while(n > (int)v.size())
}
输入输出优化
使用cin/cout会比scanf/printf慢
//关闭cstdio和iostream的同步后,cin/cout不要与printf/scanf/puts混用,也不要再使用endl,否则会造成输入输出混乱
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
//endl每次会清空缓冲区,效率比'\n'慢很多
#define endl '\n'
//快读快写 不要与ios::sync_with_stdio(false)同时使用
inline int read(){
int x = 0,f = 1;
char ch = getchar();//linux可以用更快的getchar_unlocked()
while(ch < '0' || ch > '9'){//跳过空格回车等其他字符+判断正负
if(ch == '-') f = -1;
ch = getchar();
}
while(ch >= '0' && ch <= '9'){//读取数字
x = x * 10 + ch - '0';
ch = getchar();
}
return x * f;
}
void write(int x) {
if (x < 0) putchar('-'), x = ~x + 1;
if (x > 9) write(x / 10);
putchar(x % 10 + '0');
}
//O2优化,程序开头加入
#pragma GCC optimize(2)
//火车头?
#pragma GCC optimize(3)
#pragma GCC target("avx")
#pragma GCC optimize("Ofast")
#pragma GCC optimize("inline")
#pragma GCC optimize("-fgcse")
#pragma GCC optimize("-fgcse-lm")
#pragma GCC optimize("-fipa-sra")
#pragma GCC optimize("-ftree-pre")
#pragma GCC optimize("-ftree-vrp")
#pragma GCC optimize("-fpeephole2")
#pragma GCC optimize("-ffast-math")
#pragma GCC optimize("-fsched-spec")
#pragma GCC optimize("unroll-loops")
#pragma GCC optimize("-falign-jumps")
#pragma GCC optimize("-falign-loops")
#pragma GCC optimize("-falign-labels")
#pragma GCC optimize("-fdevirtualize")
#pragma GCC optimize("-fcaller-saves")
#pragma GCC optimize("-fcrossjumping")
#pragma GCC optimize("-fthread-jumps")
#pragma GCC optimize("-funroll-loops")
#pragma GCC optimize("-fwhole-program")
#pragma GCC optimize("-freorder-blocks")
#pragma GCC optimize("-fschedule-insns")
#pragma GCC optimize("inline-functions")
#pragma GCC optimize("-ftree-tail-merge")
#pragma GCC optimize("-fschedule-insns2")
#pragma GCC optimize("-fstrict-aliasing")
#pragma GCC optimize("-fstrict-overflow")
#pragma GCC optimize("-falign-functions")
#pragma GCC optimize("-fcse-skip-blocks")
#pragma GCC optimize("-fcse-follow-jumps")
#pragma GCC optimize("-fsched-interblock")
#pragma GCC optimize("-fpartial-inlining")
#pragma GCC optimize("no-stack-protector")
#pragma GCC optimize("-freorder-functions")
#pragma GCC optimize("-findirect-inlining")
#pragma GCC optimize("-fhoist-adjacent-loads")
#pragma GCC optimize("-frerun-cse-after-loop")
#pragma GCC optimize("inline-small-functions")
#pragma GCC optimize("-finline-small-functions")
#pragma GCC optimize("-ftree-switch-conversion")
#pragma GCC optimize("-foptimize-sibling-calls")
#pragma GCC optimize("-fexpensive-optimizations")
#pragma GCC optimize("-funsafe-loop-optimizations")
#pragma GCC optimize("inline-functions-called-once")
#pragma GCC optimize("-fdelete-null-pointer-checks")
交互题
输入由评测机输入,根据输入的内容输出询问,直到确定正确答案,这一类题目,往往限制你交流(或询问)的次数,让你猜出一个东西来,此类问题比较经典的技巧有二分答案、随机化
需要注意的是,如果输出了一些数据,这些数据可能被放置于内部缓存区里,而且或许没有被直接传输给interactor,出现Idleness limit exceeded。为了避免这种情况的发生,需要每次输出时用一种特殊的清除缓存操作。
fflush(stdout);//方式一 cout << flush; //方式二 //endl换行时也会清除缓存,但'\n'不会 //最好不要使用快读、关同步流等
//https://codeforces.com/contest/1999/problem/G1
#include <bits/stdc++.h>
using namespace std;
void sol() {
int l = 2, r = 1000;
while (l < r) {
int mid = l + r >> 1;
cout << "? 1 " << mid <<endl;
int res; cin >> res;
if (mid != res) r = mid;
else l = mid + 1;
}
cout << "! " << l << endl;
}
int main() {
int T = 1;
cin >> T;
while (T--) {
sol();
}
}
一些语法/标准
重载运算符
一些可重载运算符的列举
- 一元运算:
+(正号);-(负号);~(按位取反);++;--;!(逻辑非);*(取指针对应值);&(取地址);->(类成员访问运算符)等。 - 二元运算:
+;-;&(按位与);[](取下标);=(赋值);><>=<===+=&=等。 - 其它:
()(函数调用);""(后缀标识符,C++11 起);new(内存分配);,(逗号运算符);<=>(三路比较(C++20 起)等。
实现
重载运算符分为两种情况,重载为成员函数或非成员函数。
当重载为成员函数时,因为隐含一个指向当前成员的 this 指针作为参数,此时函数的参数个数与运算操作数相比少一个。
而当重载为非成员函数时,函数的参数个数与运算操作数相同。
其基本格式为(假设需要被重载的运算符为 @):
class Example {
// 成员函数的例子
返回类型 operator @ (除本身外的参数) { /* ... */ }
};
// 非成员函数的例子
返回类型 operator @ (所有参与运算的参数) { /* ... */ }
#include <iostream>
#include <queue>
#include <set>
using namespace std;
const int P = 1e9 + 7;
struct Test {
int k;
};
struct Edge {
int a, b, w;
bool operator < (const Edge& e2) const {//set内容无法修改需要加const
if (a != e2.a) return a < e2.a;
if (b != e2.b) return b < e2.b;
return w < e2.w;
}
bool operator > (Edge& e2) {
if (a != e2.a) return a > e2.a;
if (b != e2.b) return b > e2.b;
return w > e2.w;
}
long long operator * (Edge& e2) {
return a * e2.a + b * e2.b + w * e2.w;
}
Edge operator += (Edge& e2){
a += e2.a; b += e2.b; w += e2.w;
return *this;//隐含了一个指向当前成员的this指针
}
long long operator * (Test& t) { //参数可以为其它类
return a * t.k + b * t.k + w * t.k;
}
};
Edge operator += (Edge& e, Test& t) {//非成员函数重载
return /*Edge*/{e.a - t.k, e.b - t.k, e.w - t.k};
}
struct cmp{
bool operator () (auto &e1,auto &e2)const{//cmp函数调用重载
return e1.a > e2.b;//pq小根堆,堆顶为最小值
return e1.a < e2.b;//pq大根堆,堆顶为最大值
}
};
int main() {
int n = 10; //cin >> n;
multiset<Edge>se;
priority_queue<Edge>pq;//优先队列默认重载<
//priority_queue<Edge,vector<Edge>,cmp>pq; //cmp函数调用重载
for (int i = 1; i <= n; i++) {
int x = abs((P * i * i) % 11) + 1;
Edge a = { x,x * i % 10,x * i * i % 10 };
se.insert(a);
pq.push(a);
}
se.insert({ 9,4,4 });
se.erase({ 9,4,4 });
cout << "multiset:" << endl;
for (const Edge& x : se) { cout << x.a << ' ' << x.b << ' ' << x.w << endl; }
cout << "\npq:" << endl;
while (pq.size()) {
Edge x = pq.top();
cout << x.a << ' ' << x.b << ' ' << x.w << endl;
pq.pop();
}
cout << "\ne1 = {1,2,3},e2 = {4,5,6}\n";
cout << "e1 * e2 = ";
Edge e1 = { 1,2,3 }, e2 = { 4,5,6 };
cout << e1 * e2 << endl;
cout << "e1 += e2 => ";
e1 += e2;
cout << e1.a << ' ' << e1.b << ' ' << e1.w << endl;
Test t = { 10 };
cout << "e1 * t = ";
cout << e1 * t << endl;
cout << "e1 = e1-t => ";
e1 = e1 += t;
cout << e1.a << ' ' << e1.b << ' ' << e1.w << endl;
return 0;
}
Lambda表达式
[capture list] (parameter list) -> return type { function body }
capture list是捕获列表,用于指定 Lambda表达式可以访问的外部变量,以及是按值还是按引用的方式访问。捕获列表可以为空,表示不访问任何外部变量,也可以使用默认捕获模式&或=来表示按引用或按值捕获所有外部变量,还可以混合使用具体的变量名和默认捕获模式来指定不同的捕获方式。parameter list是参数列表,用于表示 Lambda表达式的参数,可以为空,表示没有参数,也可以和普通函数一样指定参数的类型和名称,还可以在 c++14 中使用auto关键字来实现泛型参数。return type是返回值类型,用于指定 Lambda表达式的返回值类型,可以省略,表示由编译器根据函数体推导,也可以使用->符号显式指定,还可以在 c++14 中使用auto关键字来实现泛型返回值。function body是函数体,用于表示 Lambda表达式的具体逻辑,可以是一条语句,也可以是多条语句,还可以在 c++14 中使用constexpr来实现编译期计算。
int n,x;cin >> n >> x;
for(int i = 1;i <= n;i++){
cin >> a[i];
}
auto check = [&](int mid){//使用例子
return a[mid] >= x;
};
int l = 1,r = n;
while(l < r){
int mid = l + r >> 1;
if(check(mid)) r = mid;
else l = mid + 1;
}
cout << l << endl;
递归写法
//参数调用自己
auto fib = [&](auto &fib,int x){//递归求斐波那契
if(x == 1 || x == 2) return 1;
return fib(fib,x-1) + fib(fib,x-2);
};
cout << fib(fib,n) << endl;
auto dfs = [&](auto &dfs,int u,int fa)->void{//需要声明返回值类型
for(auto x:e[u]){
if(x == fa) continue;
dfs(dfs,x,u);
}
};
值捕获
值捕获的变量在 Lambda 表达式定义时就已经确定,不会随着外部变量的变化而变化。值捕获的变量默认不能在 Lambda 表达式中修改
int x = 10;
auto f = [x](auto a) -> int{ return a*x; };
x = 1;
cout << f(3) << endl;//结果为30,不随x值的变化而改变
引用捕获
在捕获列表中使用
&加变量名,表示将该变量的引用传递到 Lambda 表达式中,作为一个数据成员。引用捕获的变量在 Lambda 表达式调用时才确定,会随着外部变量的变化而变化。引用捕获的变量可以在 Lambda 表达式中被修改
int x = 10;
auto f = [&x](auto a) -> int{ x = 100;return a*x; };
cout << f(3) << endl;//结果为300,随x值的变化而改变
cout << x << endl;//x=100
隐式捕获
在捕获列表中使用
=或&,表示按值或按引用捕获 Lambda 表达式中使用的所有外部变量。这种方式可以简化捕获列表的书写,避免过长或遗漏。隐式捕获可以和显式捕获混合使用,但不能和同类型的显式捕获一起使用
int x = 10;
int y = 20;
auto f = [=, &y] (int z) -> int { return x + y + z; }; // 隐式按值捕获 x,显式按引用捕获 y
x = 30;
y = 40;
cout << f(5) << endl; //输出55,不受外部 x 的影响,受外部 y 的影响
初始化捕获(init capture):C++14 引入的一种新的捕获方式,它允许在捕获列表中使用初始化表达式,从而在捕获列表中创建并初始化一个新的变量,而不是捕获一个已存在的变量。这种方式可以使用 auto 关键字来推导类型,也可以显式指定类型。这种方式可以用来捕获只移动的变量,或者捕获 this 指针的值。
int x = 10;
auto f = [z = x + 5] (int y) -> int { return z + y; }; // 初始化捕获 z,相当于值捕获 x + 5
x = 20; // 修改外部的 x
cout << f(5) << endl; // 输出 20,不受外部 x 的影响
使用例子
作为函数参数,自定义排序准则
#include <iostream>
#include <algorithm>
using namespace std;
struct Edge{
int a,b;
}e[100005];
int main(){
int n;cin >> n;
for_each(e+1,e+n+1,[](auto &x){cin >> x.a >> x.b;});//Edge可换用auto
sort(e+1,e+n+1,[](auto &x,auto &y){if(x.a != y.a) return x.a > y.a;else return x.b > y.b;});
for_each(e+1,e+n+1,[](auto &x){cout << x.a << ' ' << x.b << endl;});
return 0;
}
int a,b,c; cin >> a >> b >> c;
auto add = [&](){w[idx] = c,e[idx] = b,ne[idx] = h[a],h[a] = idx++;};
add();
预编译头文件
通过预编译头文件<bits/stdc++.h>,加快编译万能头的时间,以windows下的gcc14.2.0编译器为例
#进入头文件所在目录 例如 C:\mingw64\include\c++\14.2.0\x86_64-w64-mingw32\bits
#打开cmd输入以下指令 其中-x c++-header可以告诉编译器这是头文件,确保编译器正确处理文件
g++ stdc++.h -O2 -x c++-header -o stdc++.h.gch
#进入源cpp文件所在目录
#预编译头文件的编译器版本、编译选项(如-std=c++23、-O2等)必须与后续编译完全一致。
g++ 1.cpp -O2 -o -1.exe
gcc标准
__int128
__int128 仅仅是 GCC 编译器内的东西,不在 C++标准内,且仅 GCC4.6 以上64位版本支持
数据范围
__int128数据范围 : $-2^{127} \sim 2^{127}-1$ 大于1.7e38
unsigned __int128数据范围 : $0 \sim 2^{128}$
输入输出
由于不在 C++ 标准内,没有配套的
printfscanfcincout等输入输出,只能手写,请不要与ios::sync_with_stdio(false)同时使用,否则会造成输入输出混乱。
使用方法
与int、long long 等整型类似,支持各种运算,如
+-*/%、移位<<>>、&|!^、==><等多种操作,可以直接与int进行运算
初始化
可以使用整型范围内的值直接赋初值 如
__int128 a = 114514;可以使用浮点数赋值,但超出浮点数有效精度的部分赋值不准确,
__int128 a = 1e30结果为 1000000000000000019884624838656__int128 a = 1e40诺超出__int128数据范围,则会赋值为最大值,即 $2^{127}-1$如果要自定义赋值为一个很大的数,可以用
__int128 a = (__int128(1) << 126)的方式 也可以写一个函数,将字符串转为__int128__int128 sto__int128(const string &s){ __int128 x = 0,f = 1; for(int i = 0;i < s.size();i++){ if(s[i] == '-') { f = -1;} else{x *= 10;x += s[i] - '0';} } return x*f; } __int128 n = sto__int128("-114514191981000");
//使用例题 https://vjudge.net/contest/233969#problem/I
#include <bits/stdc++.h>
using namespace std;
inline __int128 read(){
__int128 x = 0,f = 1;
char ch = getchar();
while(ch<'0'||ch>'9'){
if(ch == '-') f=-1;
ch = getchar();
}
while(ch>='0' && ch<='9'){
x = x*10 + ch - '0';
ch = getchar();
}
return x*f;
}
inline void write(__int128 x){
if(x < 0){ putchar('-'),x *= -1;}
if(x > 9) write(x/10);
putchar(x % 10 + '0');
}
void soviet(){
vector<__int128>a(4);
__int128 ans = 0;
for(int i = 0;i < 4;i++){
a[i] = read();
ans += a[i];
}
write(ans);
cout << '\n';
}
int main() {
int M_T = 1;//std::ios::sync_with_stdio(false),std::cin.tie(0);
std::cin >> M_T;
while(M_T--){ soviet(); }
return 0;
}
__cplusplus
cout << __cplusplus << endl;//可以直接输出预处理器宏参数
| 不同参数对应的默认c++标准 | |
|---|---|
| 1 | C++ pre-C++98 |
| 199711L | C++98 |
| 201103L | C++11 |
| 201402L | C++14 |
| 201703L | C++17 |
| 202002L | C++20 |
| 202302L | C++23 |
编译时如果存在类似 -std=c++17 的选项,则显式指定了标准;如果未指定,则使用 g++ 默认的标准(取决于版本)。
不同版本的 g++ 默认使用不同的 C++ 标准:使用bash指令gcc --version可以查看g++版本
所有Gcc版本对C和C++的支持情况(超详细版本)-CSDN博客
文件读写
//正式提交时请务必注释掉
int main() {
freopen("in.txt","r",stdin);
// freopen("out.txt","w",stdout);
int a,b; cin >> a >> b;
cout << a + b << endl;
}
#windows cmd控制台读写方式
a.exe < in.txt > out.txt
#linux 控制台
./a.out < in.txt > out.txt
时间复杂度
| 数据范围 | ||
|---|---|---|
| 20 | 指数级别 | dfs+剪枝、状压dp |
| 100 | O(n^3) | floyd、dp、高斯消元、矩阵 |
| 1000 | O(n^2) ~ O(n^2logn) | dp、二分,朴素版Dijkstra、Bellman-Ford、二分图 |
| 1e4 | O($n\sqrt n$) | 块状链表、分块、莫队、双指针 |
| 1e5 | nlogn | sort、线段树、树状数组、set/map、heap、拓扑排序、dijkstra、prim+heap、Kruskal、spfa、求凸包、求半平面交、二分、CDQ分治、整体二分、后缀数组、树链剖分、动态树 |
| 1e6 | O(n)~O(nlogn) | 单调队列、hash、双指针扫描、并查集,kmp、AC自动机,常数比较小的O(nlogn)的做法:sort、树状数组、heap、dijkstra、spfa |
| 1e7 | O(n) | 双指针扫描、kmp、AC自动机、线性筛素数 |
| 1e9 | O($\sqrt n$) | 判断质数、求欧拉函数 |
| 1e18 | O(logn) | 最大公约数、快速幂、数位DP |
| 1e1000 | O((logn)^2) | 高精度加减乘除 |
| 1e100000 | O(logk*loglogk) | 高精度加减、FFT/NTT |
//(n+n/2+n/3+...+n/n) = nlogn 调和级数
//https://codeforces.com/contest/1996/problem/D
//ab+bc+ac <= n,a+b+c <= x,0 < a,b,c
for(int i = 1;i <= n;i++){//枚举所有a
for(int j = 1;i*j <= n;j++){//枚举所有b
//则0 < c <= min((b-ab)/(a+b),x-(a+b))
}
}
//https://codeforces.com/contest/1991/problem/F
1 1 2 3 5 8 ...
fib(26) 约 1.2e5
fib(45) 约 1.1e9
//诺a[i] <= 1e9,则长度>=45的序列一定能构成一个三角形
//阶乘
8! 约 4.0e4
12! 约 4.7e8
//质数个数
1e8 约 5.7e6个
1e7 约 6.6e5个
1e6 约 7.8e4个
1e5 约 9.5e3个
C[n][0] + C[n][1] + C[n][2] + ... + C[n][n] = 2^n
$\sum_{i=1}^{n}\sum_{j=1}^{n}(a_ia_j) \ \ [i \neq j] = \sum_{i=1}^{n}(2a_i*sum_{i-1})$
$\sum_{i=1}^{n}\sum_{j=i+1}^{n}(a_i*a_j) = (sum^2 - \sum_{i=1}^{n}a_i^2)/2$
$\sum_{i=1}^{n}\sum_{j=1}^{n}(a_i+a_j) = sumn2$ ,诺有$k$层$\sum$求和,则答案为$sum * n^{k-1} * k$
$\sum_{i=1}^{n}\sum_{j=i+1}^{n}(a_i+a_j) = sum*(n-1)$
$\sum_{i=1}^n\sum_{j=1}^n\gcd(i,j) = \sum_{d=1}^n\left\lfloor\frac{n}{d}\right\rfloor^2\varphi(d)$ ,$\phi()$为欧拉函数,可以用整除分块进一步优化为$O(\sqrt{n})$
//1~n内数位非递减的数,如123,223等
//https://atcoder.jp/contests/typical90/tasks/typical90_y
//n = 1e18,cnt = 5e6
//n = 1e9,cnt = 5e4
#include <iostream>
using namespace std;
long long n,cnt = 0;
void dfs(long long u){
if(u > n) return;
cnt++;
for(int i = u%10;i <= 9;i++){
dfs(u*10+i);
}
}
int main(){
cin >> n;
for(int i = 1;i <= 9;i++){ dfs(i); }
cout << cnt << endl;
}
//1~根号n枚举
for(int i = 1;i*i <= n;i++); //建议使用,大概3周期,需要注意数据范围
for(int i = 1;i <= sqrt(n);i++);//大概10周期(需要开启O2优化或循环外提前计算sqrt(n)+eps)
for(int i = 1;i <= n/i;i++); //大概40周期,如果时间紧不建议使用
握手定理
n个人握手,每人握手m次,握手总次数$S = \frac{nm}{2}$ 给定无向图G=(V,E),有$\sum deg(V) = 2E$,图中所有结点的度数之和等于边数的两倍
//https://codeforces.com/gym/104337/problem/H
//a1+a2+a3+... = n 不同的a最多约为√2n种
分块打表

Harmonic Number - LightOJ 1234 - Virtual Judge (vjudge.net)
求$\sum_{i=1}^{n}\frac{1}{i}$,$1 \le n \le 10^8$,最多$10^4$组测试样例。
如果直接用前缀和预处理,数组需要开到10^8但空间不允许
我们可以每 $len$ 块为一组,每一块预处理。查询时,对于在表中的整块部分直接计算,其它部分暴力枚举
//O(N)预处理,O(len)查询,其中len为每块的大小
#include <iostream>
const int N = 100005;
double s[N];//统计的为块的前缀和信息
int len = 1000;
void init(int n){
double ans = 0;
for(int i = 1;i <= n*len;i++){
ans += 1.0/i;
if(i%len == 0){
s[i/len] += ans;
}
}
}
void sol(){
int n; std::cin >> n;
int k = n/len;
double ans = s[k];
for(int i = k*len+1;i <= n;i++){
ans += 1.0/i;
}
printf("%.10lf\n",ans);
}
int main(){
init(N-1);
int t; std::cin >> t;
for(int i = 1;i <= t;i++){
printf("Case %d: ",i);
sol();
}
}
随机数生成
//mt19937
#include <iostream>
#include <random>
#include <chrono>
using namespace std;
auto SEED = chrono::steady_clock::now().time_since_epoch().count();//利用时间生成随机种子
mt19937_64 rng(SEED);
int main() {
cout << rng() << endl;//每次调用rng()时,生成的数都不同
//cout << mt19937_64(1 + SEED)() << endl; //生成种子为1下的固定随机数
}
//xor_shift
//异或和移位每次都在上一次产生的值上产生新的值,因为在很大的值中舍弃了一些值,所以每次产生的值看起来就象是随机值,也就是多次shift下的伪随机数,常用于树哈希
//这种哈希十分好些且比mt19937_64(seed)()快,但随机性不强
const unsigned long long mask = mt19937_64(time(0))();//随机一个数作为固定种子
unsigned long long shift(unsigned long long x){//x在该种子下得到的随机数
x ^= mask;
x ^= x << 13;
x ^= x >> 7;
x ^= x << 17;
x ^= mask;
return x;
}
//更强的哈希函数
const auto RAND = std::chrono::steady_clock::now().time_since_epoch().count();
static long long splitmix64(long long x) {
x += 0x9e3779b97f4a7c15;
x = (x ^ (x >> 30)) * 0xbf58476d1ce4e5b9;
x = (x ^ (x >> 27)) * 0x94d049bb133111eb;
return (x ^ (x >> 31)) + RAND;
}
.vimrc
imap jk <Esc>
nmap <space> :
set cin
set sw=4
set ts=4
map <F5> :w <cr> :!clear & g++ % -O2 <cr>
map <F6> :!clear & ./a.out <cr>
map <C-F6> :!clear & ./a.out < in <cr>
"map <C-F6> :!clear & time ./a.out < in \| tee out <cr>
"set mouse=a
"syntax on
OI
